new features:
index完善对numpy数据类型的支持- 读取数据, 增加对
pyarrow数据类型的支持 - 优化读写(
Copy-on-Write)性能
What’s new in 2.0.0 (March XX, 2023)
These are the changes in pandas 2.0.0. See Release notes for a full changelog including other versions of pandas.
make thing better and simpler.
new features:
index完善对numpy数据类型的支持pyarrow数据类型的支持Copy-on-Write)性能What’s new in 2.0.0 (March XX, 2023)
These are the changes in pandas 2.0.0. See Release notes for a full changelog including other versions of pandas.
简化, 并不是逐句翻译, 只关注重点部分, 部分内容加入了自己的理解.
索引和数据选取.
The axis labeling information in pandas objects serves many purposes:
轴标签信息在pandas对象中有多个用途:
In this section, we will focus on the final point: namely, how to slice, dice, and generally get and set subsets of pandas objects. The primary focus will be on Series and DataFrame as they have received more development attention in this area.
在这部分中, 将着重讨论最后一点, 如何对pandas的对象进行切片获取其中的部分数据(即读写操作). 这是pandas的开发优先关注的.
在使用pandas进行处理数据时, 时不时会出现一个异常的警告(注意这不是错误)
C:\Users\Lian\AppData\Local\Temp/ipykernel_15272/2330773252.py:4: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy tmp['c'] = tmp['a'] + tmp['b']
TOML aims to be a minimal configuration file format that's easy to read due to obvious semantics. TOML is designed to map unambiguously to a hash table. TOML should be easy to parse into data structures in a wide variety of languages.
在了解这个文件格式前, 需要了解以下配置文件的常见格式.
windows上相对流行.json的扩展版), 但是可阅读性较差?书写规条较多?.简而言之, 作为一个好用的配置文件, 既需要数据易于存储/读取(同时需要有效数据密度高), 同时也需要有较好的阅读体验. 以json为例, 假如不进行格式化, 将难以阅读其内容.
而Toml就号称满足上述要求:
TOML 旨在成为一个语义明显且易于阅读的最小化配置文件格式.TOML 被设计成可以无歧义地映射为哈希表.TOML 应该能很容易地被解析成各种语言中的数据结构.
目前主流的语言多已支持这种文件格式, 详情见v1.0.0 compliant
extension_id: Oracle.mysql-shell-for-vs-code
只需要在vscode扩展中搜索, 安装即可.
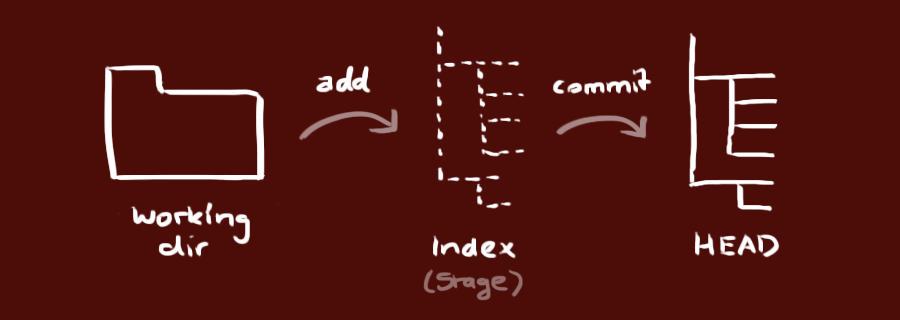
Git, 分布式版本管理系统(Distributed Version Control System)的一种.
突然有新的想法, 准备使用新的思路来写代码, 但是担心写不去, 需要在写之前预留一个副本. 避免写不下去时可以返回初始的状态.
多个需求或者多个方案, 代码存在多个分支, 方便维护.
多人同时对一项目作业, 不同部分的协作.
简而言之, 可以归结为以下三大功能:
>>> import re
>>> s = '请你查找在职员工自入职以来123的薪水涨anx-d幅情况'
>>> re_a = re.compile('\w+')
>>> re_a.search(s)
<re.Match object; span=(0, 23), match='请你查找在职员工自入职以来123的薪水涨anx'>
对, 没错, \w+这个正则表达式居然匹配出中文来了.
在使用MySQL中需要生成一些数据用于测试
mysql> desc test_a;

