python的正则和JavaScript的正则在使用上有轻微的差异.
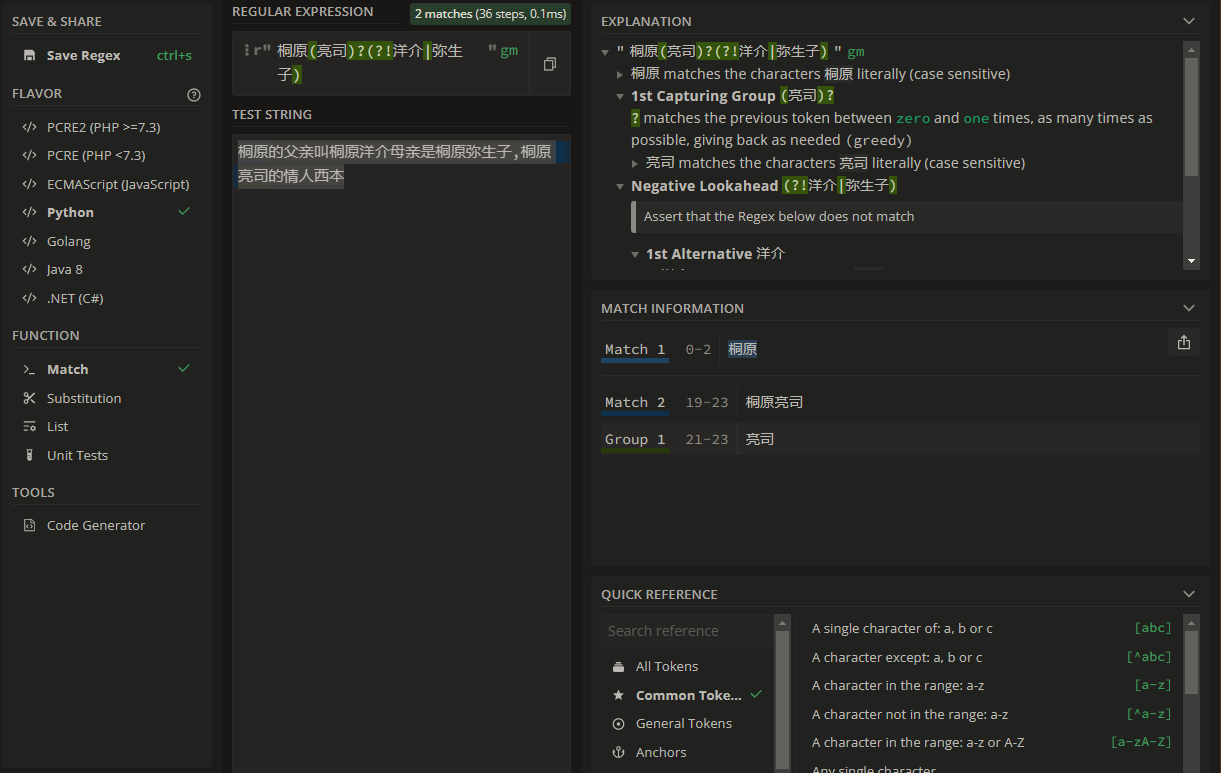
希望从这个文本中提取出桐原亮司, 桐原(但仅限于桐原, 不允许提取桐原洋介和桐原弥生子中的"桐原").
>>> import re
>>> reg_a = re.compile('桐原(亮司)?(?!洋介|弥生子)')
>>> s = '桐原的父亲叫桐原洋介母亲是桐原弥生子,桐原亮司的情人西本雪穗, 西本的情人是亮司'
>>> a = reg_a.findall(s)
>>> print(a)
['', '亮司']
# 主要卡在这里, 一开始我以为写错了正则表达式
# 但是在测试上, 已经正确显示内容, 为什么会出现这个问题?
在JavaScript上测试也没任何异常
{
const reg = /桐原(亮司)?(?!洋介|弥生子)/g;
const a = '桐原的父亲叫桐原洋介母亲是桐原弥生子,桐原亮司的情人西本雪穗, 西本的情人是亮司'.match(reg);
a.forEach(e => console.log(e));
}
// VM34:4 桐原
// VM34:4 桐原亮司
翻查文档发现
Return all non-overlapping matches of pattern in string, as a list of strings or tuples. The string is scanned left-to-right, and matches are returned in the order found. Empty matches are included in the result.
The result depends on the number of capturing groups in the pattern. If there are no groups, return a list of strings matching the whole pattern. If there is exactly one group, return a list of strings matching that group. If multiple groups are present, return a list of tuples of strings matching the groups. Non-capturing groups do not affect the form of the result.
findall()函数执行结果的返回, 返回的是捕获组(capturing groups), 并不是直接返回结果.
注意match, group的区别
# (), 这条正则增加了一个捕获组
>>> reg = re.compile('(桐原)(亮司)?(?!洋介|弥生子)')
>>> r = reg.findall(s)
>>> print(r)
# 可以看到的是这里得到的是捕获的组
[('桐原', ''), ('桐原', '亮司')]
# 这里还提供了另一个更强大的finditer, 返回更多的内容
>>> i = reg_a.finditer(s)
>>> print(i)
<callable_iterator object at 0x000001A10177D908>
>>> for e in i:
... print(e)
...
<re.Match object; span=(0, 2), match='桐原'>
<re.Match object; span=(19, 23), match='桐原亮司'>
>>> ir = reg.finditer(s)
>>> for e in ir:
... print(e)
...
<re.Match object; span=(0, 2), match='桐原'>
<re.Match object; span=(19, 23), match='桐原亮司'>
>>>
>>> ir = reg.finditer(s)
>>> for e in ir:
... print(e.span(0)[0], e.group(0))
...
0 桐原
19 桐原亮司
# 即可获得出现的位置和匹配的内容
其他的操作
# match, 从第一个开始匹配, 得到第一个结果即返回
>>> print(reg.match(s))
<re.Match object; span=(0, 2), match='桐原'>
# 返回第一个匹配值, 得到第一个结果即返回
>>> print(reg.search(s))
<re.Match object; span=(0, 2), match='桐原'>
# 拆分
>>> print(reg.split(s))
['', '桐原', None, '的父亲叫桐原洋介母亲是桐原弥生子,', '桐原', '亮司', '的情人西本雪穗, 西本的情人是亮司']
# 替换
>>> print(reg.sub('abc', s))
abc的父亲叫桐原洋介母亲是桐原弥生子,abc的情人西本雪穗, 西本的情人是亮司
