本文主要讨论的是底层数学处理相关的问题, 如方程, 矩阵, 积分等实际的计算.
更多使用示例见其他文章, 如, 报童问题详解, 各种库在实际中的是如何使用的, 都起到些什么作用.
一. 内置数字类型
-
int, 整数
-
float, 浮点数
# 查看本机的浮点数精度 >>> import sys >>> sys.float_info sys.float_info(max=1.7976931348623157e+308, max_exp=1024, max_10_exp=308, min=2.2250738585072014e-308, min_exp=-1021, min_10_exp=-307, dig=15, mant_dig=53, epsilon=2.220446049250313e-16, radix=2, rounds=1) -
complex, 复数
>>> c = 1 + 2j >>> c.real 1.0 >>> c.imag 2.0 >>>
二. 数学运算符号
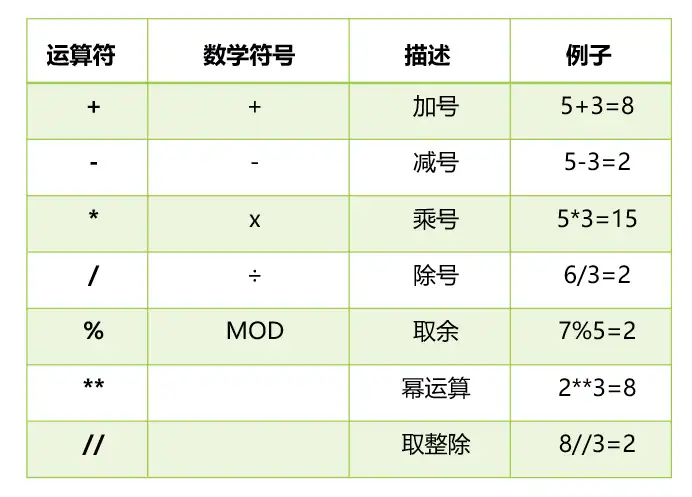
三种不同方式执行幂运算的差异, 效率, 精度.
- **
- pow
- math.pow, 默认返回的是浮点数类型
>>> 2 ** 2
4
>>> pow(2, 2)
4
>>> math.pow(2,2)
4.0
>>> 2.0 ** 2
4.0
>>> pow(2.0, 2)
4.0
>>> 2 ** 2.0
4.0
>>> pow(2, 2.0)
4.0
三. 内置数学函数
| 函数 | 含义 |
|---|---|
| int() | 将数据转换为整数 |
| float() | 将数据转换为浮点数 |
| complex() | 将数据转换为复数 |
| round() | 保留小数(或者整数) |
| pow() | 幂运算 |
| abs() | 取绝对值 |
| divmod() | 返回参与运算的商和余数, |
| min() | 最小值 |
| max() | 最大值 |
| sum() | 求和 |
>>> divmod(2, 3)
(0, 2)
3.1 浮点数精度问题
需要注意round()函数的四舍五入的操作
# 注意其执行的差异
>>> round(1.85, 1)
1.9
>>> round(1.825, 2)
1.82
返回 number 舍入到小数点后 ndigits 位精度的值. 如果 ndigits 被省略或为
None则返回最接近输入值的整数.对于支持
round()方法的内置类型 结果值会舍入至最接近的 10 的负 ndigits 次幂的倍数; 如果与两个倍数同样接近 则选用偶数. 因此round(0.5)和round(-0.5)均得出0而round(1.5)则为2. ndigits 可为任意整数值( 正数 零或负数) . 如果省略了 ndigits 或为None则返回值将为整数. 否则返回值与 number 的类型相同.对于一般的 Python 对象
number,round将委托给number.__round__.备注
对浮点数执行
round()的行为可能会令人惊讶: 例如round(2.675, 2)将给出2.67而不是期望的2.68. 这不算是程序错误: 这一结果是由于大多数十进制小数实际上都不能以浮点数精确地表示. 请参阅 浮点算术: 争议和限制 了解更多信息.
>>> from decimal import Decimal
>>> a = Decimal(1.825)
>>> a
Decimal('1.8249999999999999555910790149937383830547332763671875')
>>> a = Decimal("1.825")
>>> a
Decimal('1.825')
需要实现高精度的处理浮点数
>>> Decimal("1.825").quantize(Decimal("0.01"), rounding = "ROUND_HALF_UP")
Decimal('1.83')
注: 浮点数的处理需要格外注意, 特别是在进行比较的时候, 由于浮点数的不精准的特性, 比较最好手动指定范围, 可以使用math.isclose().
四. 四. 数学处理相关库
| 库 | 作用 |
|---|---|
| pandas | 数据(交互)载体 |
| numpy | 数据底层载体 |
| math | 内置的数学库 |
| scipy | 综合性科学计算库 |
| sympy | 符号数学运算库 |
| statsmodels | 统计处理库 |
4.1 scipy
SciPy provides algorithms for optimization, integration, interpolation, eigenvalue problems, algebraic equations, differential equations, statistics and many other classes of problems.
综合性科学计算相关, 简单高效.
| 模块名 | 应用领域 |
|---|---|
| scipy.cluster | 向量计算/Kmeans |
| scipy.constants | 物理和数学常量 |
| scipy.fftpack | 傅立叶变换 |
| scipy.integrate | 积分程序 |
| scipy.interpolate | 插值 |
| scipy.io | 数据输入输出 |
| scipy.linalg | 线性代数程序 |
| scipy.ndimage | n维图像包 |
| scipy.odr | 正交距离回归 |
| scipy.optimize | 优化 |
| scipy.signal | 信号处理 |
| scipy.sparse | 稀疏矩阵 |
| scipy.spatial | 空间数据结构和算法 |
| scipy.special | 一些特殊的数学函数 |
| scipy.stats | 统计 |
# 一元线性回归的拟合
from scipy import stats
x = list(range(1, 21))
y = [
3, 4, 5, 5, 2, 4, 7, 8, 11, 8, 12,
11, 13, 13, 16, 17, 18, 17, 19, 21
]
stats.linregress(x, y)
'''
LinregressResult(
slope=0.9699248120300752,
intercept=0.5157894736842099,
rvalue=0.9690508744938254,
pvalue=2.211450394914175e-12,
stderr=0.058238193980801746,
intercept_stderr=0.6976439770211438
)
'''
scipy.optimize
| 求解器 | 中文名 | jac要求 | hess要求 | 边界约束 | 条件约束 | 求解规模 |
|---|---|---|---|---|---|---|
| Nelder-Mead | 单纯形法 | 无 | 无 | 可选 | 无 | 小 |
| Powell | 鲍威尔法 | 无 | 无 | 可选 | 无 | 小 |
| CG | 共轭梯度法 | 可选 | 无 | 无 | 无 | 中小 |
| BFGS | 拟牛顿法 | 可选 | 无 | 无 | 无 | 中大 |
| L-BFGS-B | 限制内存BFGS法 | 可选 | 无 | 可选 | 无 | 中大 |
| TNC | 截断牛顿法 | 可选 | 无 | 可选 | 无 | 中大 |
| COBYLA | 线性近似法 | 无 | 无 | 无 | 可选 | 中大 |
| SLSQP | 序列最小二乘法 | 可选 | 无 | 可选 | 可选 | 中大 |
| trust-constr | 信赖域算法 | 无 | 可选 | 可选 | 可选 | 中大 |
| Newton-CG | 牛顿共轭梯度法 | 必须 | 可选 | 无 | 无 | 大 |
| dogleg | 信赖域狗腿法 | 必须 | 可选 | 无 | 无 | 中大 |
| trust-ncg | 牛顿共轭梯度信赖域法 | 必须 | 可选 | 无 | 无 | 大 |
| trust-exact | 高精度信赖域法 | 必须 | 可选 | 无 | 无 | 大 |
| trust-krylov | 子空间迭代信赖域法 | 必须 | 可选 | 无 | 无 | 大 |
- SciPy_Cheat_Sheet
- Scipy系列(二): 线性代数及积分-CSDN博客
- 用 Python 做科学计算(工具篇)- - scipy 使用指南
- scipy-cheat-sheet-linear-algebra-in-python
- python Scipy.optimize 模块中优化求解器总结
4.2 sympy
该视频提供了大量的示例.
SymPy is a Python library for symbolic mathematics. It aims to become a full-featured computer algebra system (CAS) while keeping the code as simple as possible in order to be comprehensible and easily extensible. SymPy is written entirely in Python.
符号数学运算库, 这个库让绝大部分能够接触到的数学符号的计算成为很简单的事情.
注意: 复杂的函数执行速度可能很慢, 可以使用scipy来作一定的替代.
4.3 statsmodels
statsmodels is a Python module that provides classes and functions for the estimation of many different statistical models, as well as for conducting statistical tests, and statistical data exploration. An extensive list of result statistics are available for each estimator. The results are tested against existing statistical packages to ensure that they are correct. The package is released under the open source Modified BSD (3-clause) license. The online documentation is hosted at statsmodels.org.
专注于解决统计相关内容.
models, 意味着这是集成模型的, 但是这和各类xx机器学习的库不一样, 这个库提供更为基础的, 更为完善针对统计的处理工具, 作业风格更像是SPSS, matlab..
import statsmodels.api as sta
model = sta.OLS(y, x).fit()
model.summary()
| OLS Regression Results | |||
|---|---|---|---|
| Dep. Variable: | y | R-squared: | 0.939 |
| Model: | OLS | Adj. R-squared: | 0.936 |
| Method: | Least Squares | F-statistic: | 277.4 |
| Date: | Thu, 06 Apr 2023 | Prob (F-statistic): | 2.21e-12 |
| Time: | 18:36:59 | Log-Likelihood: | -35.459 |
| No. Observations: | 20 | AIC: | 74.92 |
| Df Residuals: | 18 | BIC: | 76.91 |
| Df Model: | 1 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 0.5158 | 0.698 | 0.739 | 0.469 | -0.950 | 1.981 |
| x1 | 0.9699 | 0.058 | 16.654 | 0.000 | 0.848 | 1.092 |
| Omnibus: | 2.687 | Durbin-Watson: | 1.649 |
|---|---|---|---|
| Prob(Omnibus): | 0.261 | Jarque-Bera (JB): | 2.068 |
| Skew: | -0.767 | Prob(JB): | 0.356 |
| Kurtosis: | 2.638 | Cond. No. | 25.0 |
4.4 math
涵盖大部分常用数学的计算.
4.4.1 常数
| 常数 | 数学形式 | 描述 |
|---|---|---|
| pi | π | 圆周率 |
| e | e | 自然对数 |
| inf | ∞ | 正无穷 负无穷为-inf |
| nan | 非浮点数标记,Not a Number |
4.4.2 数值转换
| 函数 | 数学表示 | 描述 |
|---|---|---|
| fabs(x) | | x | | 返回x的绝对值 |
| fmod(x,y) | x % y | 返回x与y的模( 余数) |
| fsum([x,y,...]) | x + y + ...... | 浮点数精确求和 |
| gcd(x,y) | 返回x和y的最大公约数 x和y为整数 | |
| trunc(x) | 返回x的整数部分 | |
| modf(x) | 返回x的小数和整数部分 | |
| ceil(x) | ⌈ x ⌉ | 向上取整 返回不小于x的最小整数 |
| floor(x) | ⌊ x ⌋ | 向下取整 返回不大于x的最大整数 |
| factorial(x) | x! | 返回x的阶乘 x为整数 |
| frepx(x) | x = m * 2ᵉ | 返回(m,e) 当x=0 返回(0.0,0) |
| ldexp(x,i) | x * 2ⁱ | 返回x * 2ⁱ 运算值 frepx(x)函数的反运算 |
| copysign(x,y) | | x | * | x | / y | 用数值y的正负号替换数值x的正负号 |
| isclose(a,b) | 比较a和b的相似性 返回True或False | |
| isfinite(x) | 当x为无穷大 返回True; 否则 返回False | |
| isinf(x) | 当x为正数或负数无穷大 返回True; 否则 返回False | |
| isnan(x) | 当x是NaN 返回True; 否则 返回False |
4.4.3 幂对数函数
| 函数 | 数学表示 | 描述 |
|---|---|---|
| pow(x,y) | xʸ | 返回x的y次幂 |
| exp(x) | eˣ | 返回e的x次幂 e是自然对数 |
| expml(x) | eˣ - 1 | 返回e的x次幂减1 |
| sqrt(x) | √x | 返回x的平方根 |
| log(x[,base]) | logbase x | 返回x的对数值 只输入x时 返回自然对数 即㏑x |
| log1p(x) | ㏑(1+x) | 返回1+x的自然对数值 |
| log2(x) | logx | 返回x的2对数值 |
| log10(x) | log10 x | 返回x的10对数值 |
4.4.4 三角函数
| 函数 | 数学表示 | 描述 |
|---|---|---|
| degree(x) | 角度x的弧度值转角度值 | |
| radians(x) | 角度x的角度值转弧度值 | |
| hypot(x,y) | √(x²+y²) | 返回(x,y)坐标到原点(0,0)的距离 |
| sin(x) | sin x | 返回x的正弦函数值 x是弧度值 |
| cso(x) | cos x | 返回x的余弦函数值 x是弧度值 |
| tan(x) | tan x | 返回x的正切函数值 x是弧度值 |
| asin(x) | arcsin x | 返回x的反正弦函数值 x是弧度值 |
| acos(x) | arccos x | 返回x的反余弦函数值 x是弧度值 |
| atan(x) | arctan x | 返回x的反正切函数值 x是弧度值 |
| atan2(y,x) | arctan y/x | 返回y/x的反正切函数值 x是弧度值 |
| sinh(x) | sinh x | 返回x的双曲正弦函数值 |
| cosh(x) | cosh x | 返回x的双曲余弦函数值 |
| tanh(x) | tanh x | 返回x的双曲正切函数值 |
| asinh(x) | arcsinh x | 返回x的反双曲正弦函数值 |
| acosh(x) | arccosh x | 返回x的反双曲余弦函数值 |
| atanh(x) | arctanh x | 返回x的反双曲正切函数值 |
4.4.5 其他特殊函数
-
erf(x)
-
erfc(x)
-
gamma(x)
| 函数 | 数学表示 | 描述 |
|---|---|---|
| erf(x) | 高斯误差函数 应用于概率论 统计学等领域 | |
| erfc(x) | 余补高斯误差函数 erfc(x) = 1- erf(x) | |
| gamma(x) | 伽马(Gamma)函数 也叫欧拉第二积分函数 | |
| lgamma(x) | ㏑(gamma(x)) | 伽马函数的自然对数 |
五. 数学计算
# 先将全部的函数导入
from sympy import *
5.1 矩阵/方程
解上述的方程.
二元一次方程实际上可以转换为矩阵的形式:
## 直接调用np.linalg.solve
>>> import numpy as np
>>> a = np.mat('1,2; 4,5')
>>> a
matrix([[1, 2],
[4, 5]])
>>> b = np.mat('3,6')
>>> b
matrix([[3, 6]])
>>> b = b.T
>>> b
matrix([[3],
[6]])
>>> np.linalg.solve(a, b)
matrix([[-1.],
[ 2.]])
# 利用符号
>>> from sympy import symbols
>>> x = symbols('x')
>>> y = symbols('y')
>>> x
x
>>> y
y
>>> from sympy import solve
>>> solve([4 * x + 5 * y -6, x + 2 * y-3], [x, y])
{x: -1, y: 2}
# scipy
>>> a = np.array([[3, 2, 0], [1, -1, 0], [0, 5, 1]])
>>> a
array([[ 3, 2, 0],
[ 1, -1, 0],
[ 0, 5, 1]])
>>> a = np.array([[1,2], [4,5]])
>>> a
array([[1, 2],
[4, 5]])
>>> b = np.array([[3,6]])
>>> b
array([[3, 6]])
>>> b.T
array([[3],
[6]])
>>> b= b.T
>>> from scipy import linalg
>>> linalg.solve(a, b)
array([[-1.],
[ 2.]])
>>>
5.2 微分
>>> x = symbols('x')
>>> diff(x ** 4, x)
4*x**3
# 需要多次求导, 只需要在后面加x即可
>>> diff(x ** 4, x, x)
12*x**2
5.3 定积分
>>> from sympy import *
>>> x = symbols('x')
>>> print(integrate(x**2 + exp(x) + 1, (x, 0, 1)))
1/3 + E
5.4 不定积分
>>> x = symbols('x')
>>> print(integrate(x*exp(x)/(exp(x)+1)**2, x))
x - x/(exp(x) + 1) - log(exp(x) + 1)
5.5 多重定积分
>>> x, y = symbols('x y')
>>> print(integrate(x*y, (x, 0, 1), (y, 0, 1/2)))
0.0625000000000000
5.6 多重不定积分
>>> f = (4/3)*x + 2*y
>>> integrate(f, (x, 0, 1), (y, -x, x))
1.33333333333333*x
5.7 极限
>>> f = sin(x)/x
>>> print(limit(f, x, 0))
1
>>> print(limit(((x+3)/(x+2))**x, x, oo))
E
# oo表示无穷, -oo, +oo
5.8 最优化
这里使用的是scipy.optimize.linprog
scipy.optimize.**linprog**(*c*, *A_ub=None*, *b_ub=None*, *A_eq=None*, *b_eq=None*, *bounds=None*, *method='highs'*, *callback=None*, *options=None*, *x0=None*, *integrality=None*)
from scipy import optimize
# * -1, 转换为min
z = [-2, -3, 5]
a = [
[1, 1, 1],
# * -1, 转换为小于等于
[-2, 5, -1],
[1, 3, 1]
]
b = [
7, -10, 12
]
x1b = (0, None)
x2b = (0, None)
x3b = (0, None)
optimize.linprog(
z,
A_ub=a, b_ub=b,
bounds=[x1b, x2b, x3b],
method='revised simplex'
)
con: array([], dtype=float64)
fun: -14.571428571428571
message: 'Optimization terminated successfully.'
nit: 2
slack: array([0. , 0. , 3.85714286])
status: 0
success: True
x: array([6.42857143, 0.57142857, 0. ])
Linear programming: minimize a linear objective function subject to linear equality and inequality constraints.
Linear programming solves problems of the following form:
where x is a vector of decision variables; c, bub, beq, l, and u are vectors; and Aub and Aeq are matrices.
Alternatively, that’s:
minimize:
c @ xsuch that:
A_ub @ x <= b_ub A_eq @ x == b_eq lb <= x <= ubNote that by default
lb = 0andub = Noneunless specified withbounds.
c: 线性目标函数的系数
数据类型: 一维数组
A_ub( 可选参数) : 不等式约束矩阵 A u b A_{ub}Aub的每一行指定x xx上的线性不等式约束的系数
数据类型: 二维数组
b_ub( 可选参数) : 不等式约束向量 每个元素代表A u b x A_{ub}xAubx的上限
数据类型: 一维数组
A_eq( 可选参数) : 等式约束矩阵 A e q A_eqAeq的每一行指定x xx上的线性等式约束的系数
数据类型: 二维数组
b_eq( 可选参数) : 等式约束向量 A e q x A_{eq}xAeqx的每个元素必须等于b e q b_{eq}beq的对应元素
数据类型: 一维数组
bounds( 可选参数) : 定义决策变量x xx的最小值和最大值
数据类型:
(min, max)序列对None: 使用None表示没有界限 默认情况下 界限为( 0 None) ( 所有决策变量均为非负数)
如果提供一个元组
(min, max)则最小值和最大值将用作所有决策变量的界限.method( 可选参数) : 算法
{‘interior-point’, ‘revised simplex’, ‘simplex’}以上三种算法可选数据类型: 输入如上三种字符串
callback( 可选参数) : 调用回调函数 我的理解是等待被调用的参数 如果提供了回调函数 则算法的每次迭代将至少调用一次. 回调函数必须接受单个
scipy.optimize.OptimizeResult由以下字段组成:x: 当前解向量
数据类型: 一维数组
fun: 目标函数的当前值( c T x c^TxcTx)
数据类型: 浮点数
success: 当算法成功完成时为
True
数据类型: 布尔值
slack: 不等式约束的松弛值( 名义上为正值) b u b − A u b x b_{ub}-A_{ub}xbub−Aubx
数据类型: 一维数组
con: 等式约束的残差( 名义上为零) b e q − A e q x b_{eq}-A_{eq}xbeq−Aeqx
数据类型: 一维数组
phase: 正在执行算法的阶段
数据类型: 整数
status: 表示算法退出状态的整数
数据类型: 整数
0: 优化按名义进行
1: 达到了迭代限制
2: 问题似乎不可行
3: 问题似乎是不收敛
4: 遇到数值困难
nit: 当前的迭代次数
数据类型: 整数
message: 算法状态的字符串描述符
数据类型: 字符串
options( 可选参数) : 求解器选项字典 所有方法都接受以下选项:
数据类型: 字典
maxiter: 整数 要执行的最大迭代次数
disp: 布尔值 设置为True以打印收敛消息 默认值:False
autoscale: 布尔值 设置为True以自动执行平衡 如果约束中的数值分开几个数量级 请考虑使用此选项 默认值:False
presolve: 布尔值 设置为False可禁用自动预解析 默认值:True
rr: 布尔值 设置为False可禁用自动移除冗余 默认值:True
x0( 可选参数) : 猜测决策变量的值 将通过优化算法进行优化. 当前仅由’ revised simplex’ 方法使用此参数 并且仅当 x0 表示基本可行的解决方案时才可以使用此参数.
数据类型: 一维数组
输出格式:
x: 在满足约束的情况下将目标函数最小化的决策变量的值
数据类型: 一维数组
fun: 目标函数的最佳值( c T x c^TxcTx)
数据类型: 浮点数
slack: 不等式约束的松弛值( 名义上为正值) b u b − A u b x b_{ub}-A_{ub}xbub−Aubx
数据类型: 一维数组
con: 等式约束的残差( 名义上为零) b e q − A e q x b_{eq}-A_{eq}xbeq−Aeqx
数据类型: 一维数组
success: 当算法成功找到最佳解决方案时为
True数据类型: 布尔值
status: 表示算法退出状态的整数
数据类型: 整数
0: 优化成功终止
1: 达到了迭代限制
2: 问题似乎不可行
3: 问题似乎是不收敛
4: 遇到数值困难
nit: 在所有阶段中执行的迭代总数
数据类型: 整数
message: 算法退出状态的字符串描述符
数据类型: 字符串
六. 小结
以上, 从基本数学到高等数学, 统计, 模型等.
one python, one world!
