前言

相比于MySQL, 同样作为开源的关系型数据库(RDBMS), PostgreSQL(ORDBMS)的知名度远低于前者(至少在国内是如此). 但是随着MySQL被甲骨文收购(引起开源社区和其他大型存在业务竞争公司的担忧), 以及大数据的兴起, 近年PostgreSQL颇有异军突起的迹象.
差异
关于二者的一些特性, 或者优势什么之类的, 多是一家之言, 多带有特别强烈的商业利益, 特别是鼓吹PostgreSQL, 其背后的商业味道更浓(由于PostgreSQL的开源协议, 更适合作为二次开发的商品发布, 大量二次开发的商业数据库更倾向于使用PostgreSQL作为基础), 总之不管是MySQL, PostgreSQL的好与不好, 姑且听之, 适合自己的才是关键.
IBM: PostgreSQL vs MySQL: What are the differences?
There are many differences between PostgreSQL and MySQL. Some of the differences in features, functionality and benefits are as follows:
- Database type
- MySQL: Relational
- PostgreSQL: Object-relational
- Programming language
- MySQL: C/C++
- PostgreSQL: C
- Support for CASCADE
- MySQL: No
- PostgreSQL: Yes
- User interface
- MySQL: Workbench GUI
- PostgreSQL: PgAdmin
- Supported procedure complexity
- MySQL: SQL syntaxes and stored procedures
- PostgreSQL: Advanced procedures and stored procedures
- Supported index type
- MySQL: Binary Search Tree (B-Tree)
- PostgreSQL: Many, including GIN and Hash
- Encryption between client and server
- MySQL: Transport Layer Security (TLS) protocol
- PostgreSQL: SSL
- XML data type support
- MySQL: No
- PostgreSQL: Yes
- Support for materialized view and table inheritance
- MySQL: No
- PostgreSQL: Yes
- Support for advance data types
- MySQL: No
- PostgreSQL: Yes – hstore and user-defined tdtaa
- Support for multiversion concurrency control (MVCC)
- MySQL: No ?
- PostgreSQL: Yes
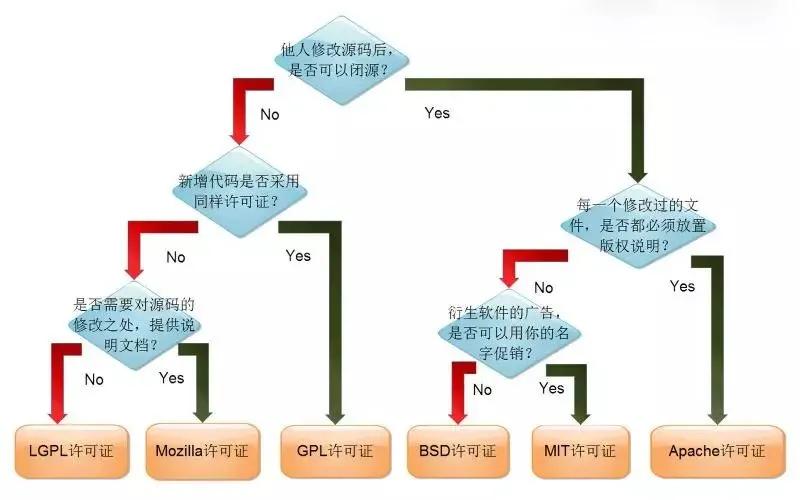
PostgreSQL许可是一种自由的开源许可证, 与BSD或MIT许可证类似
BSD许可证鼓励代码共享, 但需要尊重代码作者的著作权. BSD许可证由于允许使用者修改和重新发布代码, 也允许使用或在BSD代码上开发商业软件发布和销售, 因此是对商业集成很友好的许可证/协议. 很多的公司在选用开源产品的时候都首先考虑BSD许可证/协议的开源产品, 因为可以完全控制这些第三方的代码, 在必要的时候可以修改或者二次开发.
趋势
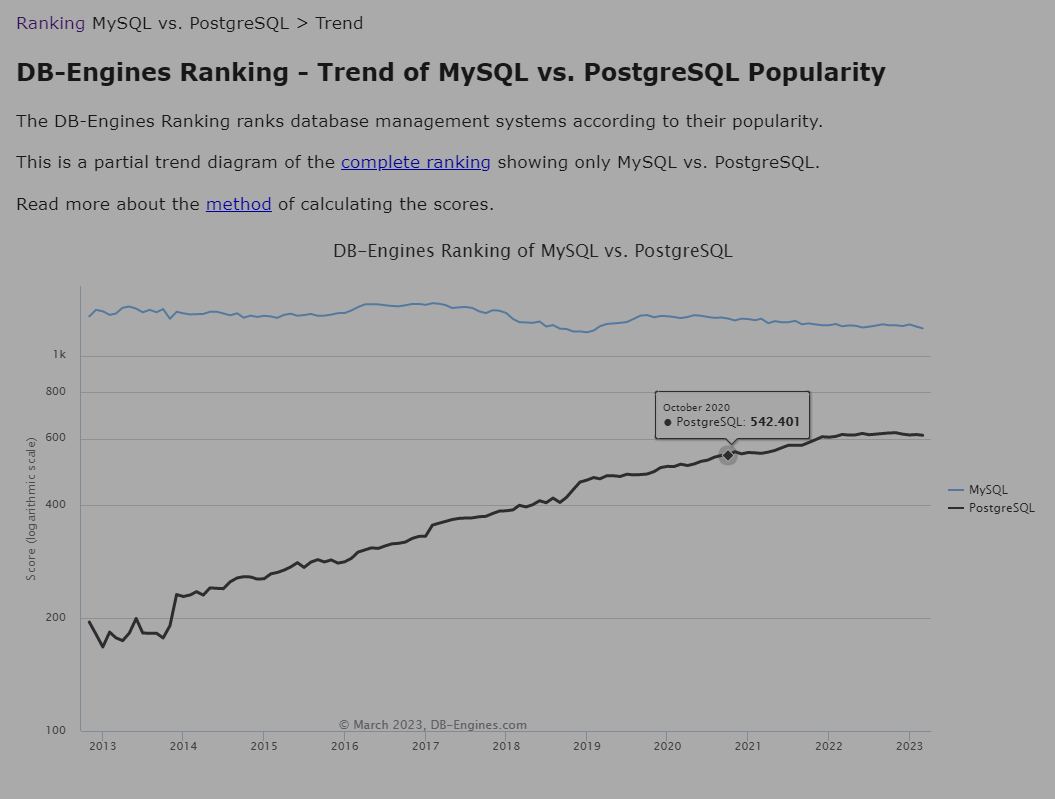
historical trend of MySQL vs. PostgreSQL popularity (db-engines.com)
趋势, 只是相对形象的描述二者之间在某些方面上的差异, 并不能代表实际的产品在业内的使用情况, 只是一个参考指标, 但是也一定程度反映二者的一些真实变化情况.
例如窗口函数(window function), 在很多数据库都支持下, MySQL才慢腾腾地支持这个特性(8.0版本引入大量新特性也让MySQL出现版本出现一定的断裂), 不得不说, 由于被甲骨文收购后, MySQL在某些方面的开发进度是相对放慢的, 毕竟不能和自家的付费产品直接竞争, 以及开源社区对MySQL警惕, 导致在外部开源生态环境的开发上, MySQL已经出现了不少的问题.
小结
先放在前面, 只是简单说说个人的观感和使用体验.
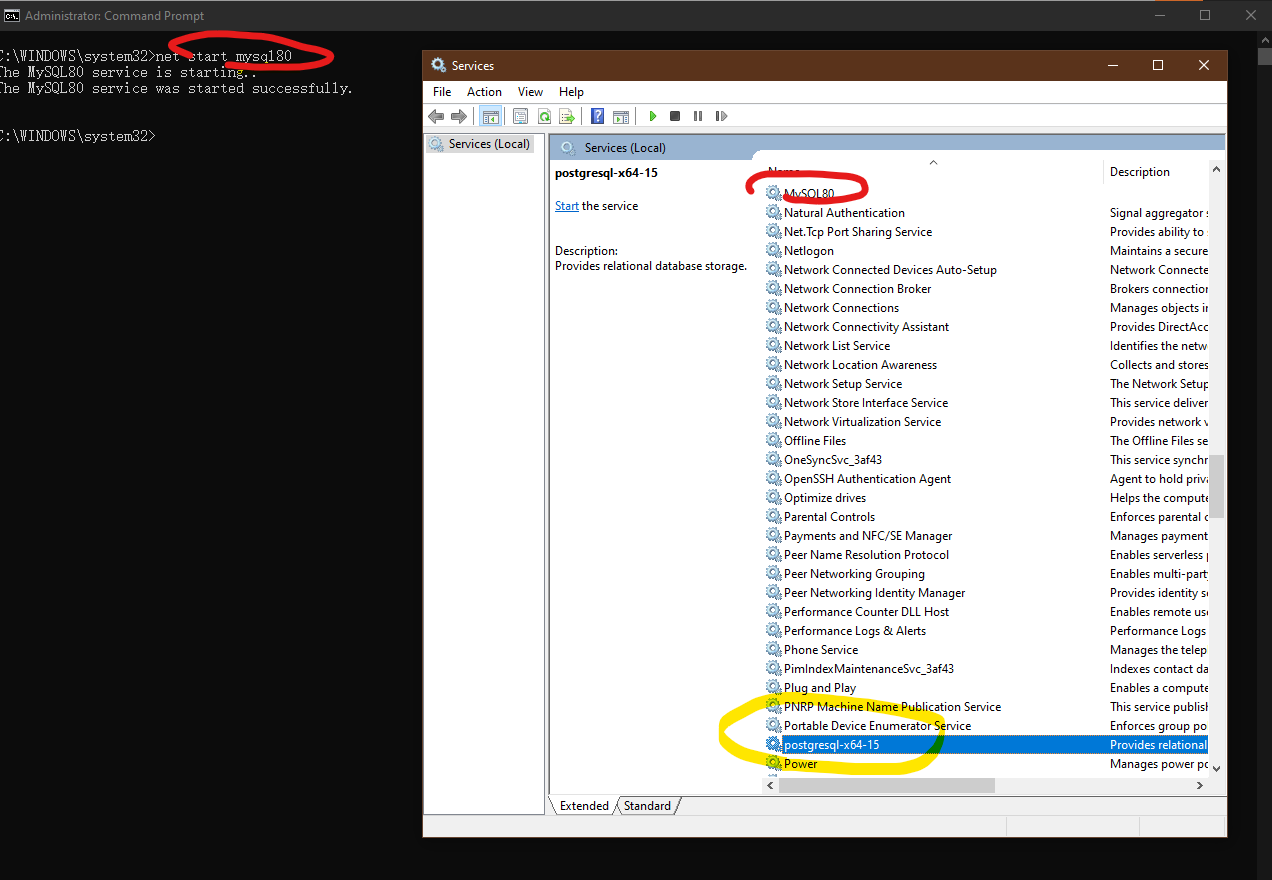
(同样是启动服务, 但是postgresql的服务名称却是这个样子的, postgresql-x64-15, 不拼写多几次未必记得住, 还得注意空格输入位置)
不得不说PostgreSQL这个单词真的有点阻碍这个产品的推广(滑稽), 相比于MySQL.
总体上手体验, 不是很近人性, 在很多操作上, 没有MySQL这么容易上手.
更为重要的一点, MySQL拥有庞大的现有经验和知识的积累, 大量的问题可以通过检索可以获取到(而且很多问题研究都非常深入), 但是PostgreSQL的相关知识的分享是偏少的, 这意味着新手不是那么容易掌握PostgreSQL(需要自己不断地去试错和踩雷, 而且缺乏资料, 这个过程是相对漫长的).
但是PostgreSQL的鼓吹者常说的, PostgreSQL更为严谨相比于MySQL是有一定道理的, 以及PostgreSQL目前在开源生态上更具有优势也是相对明显的.
简而言之, 对于纯纯的新手, 建议还是以MySQL作为练手(只是为了掌握基本的SQL命令, 没有必要挑一个资料缺乏的作为入门), 当深入到需要考虑大规模的数据复杂处理, 数据间的高度耦合等问题可以尝试PostgreSQL, 对于公司而言, 业务的展开速度应该更多时考虑的吧, 特别是对于非技术型导向的公司.
基本操作
psql --help
psql是PostgreSQL 的交互式客户端工具。
使用方法:
psql [选项]... [数据库名称 [用户名称]]
通用选项:
-c, --command=命令 执行单一命令(SQL或内部指令)然后结束
-d, --dbname=DBNAME 指定要连接的数据库 (默认:"Lian")
-f, --file=文件名 从文件中执行命令然后退出
-l, --list 列出所有可用的数据库,然后退出
-v, --set=, --variable=NAME=VALUE
设置psql变量NAME为VALUE
(例如,-v ON_ERROR_STOP=1)
-V, --version 输出版本信息, 然后退出
-X, --no-psqlrc 不读取启动文档(~/.psqlrc)
-1 ("one"), --single-transaction
作为一个单一事务来执行命令文件(如果是非交互型的)
-?, --help[=options] 显示此帮助,然后退出
--help=commands 列出反斜线命令,然后退出
--help=variables 列出特殊变量,然后退出
输入和输出选项:
-a, --echo-all 显示所有来自于脚本的输入
-b, --echo-errors 回显失败的命令
-e, --echo-queries 显示发送给服务器的命令
-E, --echo-hidden 显示内部命令产生的查询
-L, --log-file=文件名 将会话日志写入文件
-n, --no-readline 禁用增强命令行编辑功能(readline)
-o, --output=FILENAME 将查询结果写入文件(或 |管道)
-q, --quiet 以沉默模式运行(不显示消息,只有查询结果)
-s, --single-step 单步模式 (确认每个查询)
-S, --single-line 单行模式 (一行就是一条 SQL 命令)
输出格式选项 :
-A, --no-align 使用非对齐表格输出模式
--csv CSV(逗号分隔值)表输出模式
-F, --field-separator=STRING
为字段设置分隔符,用于不整齐的输出(默认:"|")
-H, --html HTML 表格输出模式
-P, --pset=变量[=参数] 设置将变量打印到参数的选项(查阅 \pset 命令)
-R, --record-separator=STRING
为不整齐的输出设置字录的分隔符(默认:换行符号)
-t, --tuples-only 只打印记录i
-T, --table-attr=文本 设定 HTML 表格标记属性(例如,宽度,边界)
-x, --expanded 打开扩展表格输出
-z, --field-separator-zero
为不整齐的输出设置字段分隔符为字节0
-0, --record-separator-zero
为不整齐的输出设置记录分隔符为字节0
联接选项:
-h, --host=主机名 数据库服务器主机或socket目录(默认:"本地接口")
-p, --port=端口 数据库服务器的端口(默认:"5432")
-U, --username=用户名 指定数据库用户名(默认:"Lian")
-w, --no-password 永远不提示输入口令
-W, --password 强制口令提示 (自动)
更多信息,请在psql中输入"\?"(用于内部指令)或者 "\help"(用于SQL命令),
或者参考PostgreSQL文档中的psql章节.
臭虫报告至<pgsql-bugs@lists.postgresql.org>.
PostgreSQL 主页: <https://www.postgresql.org/
# 连接
psql -U username -h hostname -p port -d dbname
# 默认 postgres 用户
# 没有MySQL的 root好记
# 切换数据库
\c db_name
# use db_name
# mysql
# 查看数据库
\l
test_db=# \l
# show databases;
List of databases
Name | Owner | Encoding | Collate | Ctype | ICU Locale | Locale Provider | Access privileges
-----------+----------+----------+---------------------------+---------------------------+------------+-----------------+-----------------------
postgres | postgres | UTF8 | English_United States.936 | English_United States.936 | | libc |
template0 | postgres | UTF8 | English_United States.936 | English_United States.936 | | libc | =c/postgres +
| | | | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | English_United States.936 | English_United States.936 | | libc | =c/postgres +
| | | | | | | postgres=CTc/postgres
test_db | postgres | UTF8 | English_United States.936 | English_United States.936 | | libc |
(4 rows)
# 查看表
\d
test_db=# \d
List of relations
Schema | Name | Type | Owner
--------+--------+-------+----------
public | test_a | table | postgres
public | test_b | table | postgres
(2 rows)
# mysql
show tables;
\q
# 等价
# 退出
exit;
# mysql
简单使用
MySQL被嘲笑的最狠的一点应是ACID中的A, Atomicity, 原子性.
原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
同样是在事务中执行, MySQL的事务中执行假如出现错误, 是不会自动执行回滚的(在提交事务时), 导致部分数据被执行操作.
MySQL root@localhost:test_db> create table test_c (id int primary key);
Query OK, 0 rows affected
Time: 0.016s
MySQL root@localhost:test_db> begin;
Query OK, 0 rows affected
Time: 0.001s
MySQL root@localhost:test_db> insert into test_c values (1);
Query OK, 1 row affected
Time: 0.003s
MySQL root@localhost:test_db> insert into test_c values (1);
(1062, "Duplicate entry '1' for key 'test_c.PRIMARY'")
MySQL root@localhost:test_db> commit;
Query OK, 0 rows affected
Time: 0.002s
MySQL root@localhost:test_db> select * from test_c;
+----+
| id |
+----+
| 1 |
+----+
# 理论上, 是不希望这一行被插入
# 但在不少场合, 这一点未必是对的, 插入部分的数据, 也是可以的, 例如爬虫, 将爬取的数据部分插入, 其他的插入失败的操作并不影响使用.
# 但是从理论的角度来看, 这种操作显得不是那么让人放心, 假如犯错了呢, 意外没有手动执行回滚.
# 相当于用不严谨换取了一定的自由
# 至于代价嘛, 看怎么平衡
1 row in set
Time: 0.009s
而在PostgreSQL上是自动回滚的.
test_db=# create table test_c (id int primary key);
CREATE TABLE
test_db=# begin;
BEGIN
test_db=*# insert into test_c values (1);
INSERT 0 1
test_db=*# insert into test_c values(1);
ERROR: duplicate key value violates unique constraint "test_c_pkey"
DETAIL: Key (id)=(1) already exists.
# 在执行提交时, pq是会自动判断事务中的行为是否全部执行成功, 假如不是, 那么自动执行回滚操作
test_db=!# commit;
ROLLBACK
test_db=# select * from test_c;
id
----
(0 rows)
事务具有以下四个标准属性,通常根据首字母缩写为
ACID:
- 原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
- 一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态的含义是数据库中的数据应满足完整性约束。
- 隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
- 持久性(Durability):已被提交的事务对数据库的修改应该永久保存在数据库中。
更多内容
...updating...
未完
