'''
@author: HLA
@github: https://github.com/Kyouichirou
@version: 1.0
@description: mysql基础与进阶; 基础, 查询, 配置, 管理.
@license: MIT
-- make thing better and simpler.
'''
一. 前言
在MySQL更新到8.0之后, 很多内容发生较大的变化, 而搜索引擎/书籍查询到的大量信息还是基于5.x, 例如查询缓存这个机制在8.0就发生大的变化, 对于一些相对晦涩难懂的部分, 如日志, 锁, 事务, mvcc等更应注意, 这部分内容可查询到的信息相当混乱(陈旧, 错误), 大量混杂着各个时期MySQL的一些特性在其中, 遇到难以理解的部分应多查阅官方文档.
由于Typora会出现较为严重的卡顿在字数超过2万后, 部分内容拆出到其他文章中讨论.
1.1 使用环境
os: win10, 64bit pro
WSL2/VMware: ubuntu 22
MySQL version: 8.0.30
Windows下不建议直接使用压缩包, 解压添加环境变量, 手动逐个管理MySQL的组件. MySQL installer, 一站式的管理服务(组件选择, 安装, 升级, 卸载, 变更版本).
1.2 图形管理工具
-
MySQL Workbench
- 使用相对较少, 整体的界面布局偏向于管理员的操作平台.
- 免费,
os要求win10 or later.(win8.1 虽然可以安装, 但是会出现大量的闪退)
-
Navicat Premiumthe best software for mysql, maybe more databases.
- 付费.
- 交互界面简单易上手.
- 数据展示友好, 那怕是对于
nosql的mongodb的文档型数据的展示. 也相对好地解决了多层嵌套下的数据展示的问题. - 覆盖绝大部分的数据库, 不管是
sql型数据库还是nosql型, 不管是本地, 还是远程数据库. - 完备的功能支持, 从基础的代码辅助, 到数据库的设计, 用户/权限管理, 备份, 定时任务等等. 可将之视作数据库的瑞士军刀.
navicat也存在着一些问题:还不支持窗口函数的关键词的提示: 如
unbounded, following, preceding等# 假如存在一张`user`表 # 选择美化sql语句之后, 导致在linux上运行的MySQL出现问题 # linux下的MySQL默认对表是大小写敏感的 SELECT * FROM # 这里将小写改成大写, 假如和关键词相同 USER WHERE id = 1 LIMIT 10;
二. 基本概要
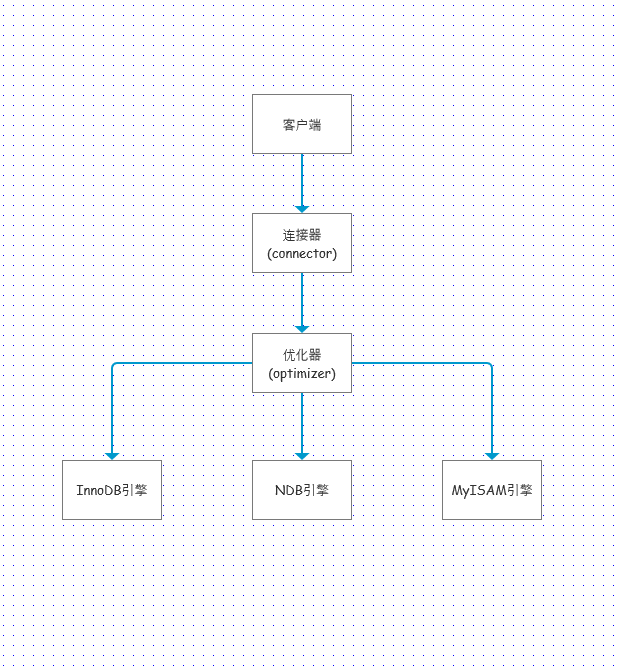
注意优化器的解析处理, 这将改变一些理论上的行为. 例如优化器认为走全表扫描比对索引来的更快, 也许并不会使用索引.
2.1 数据类型
2.1.1 数值型
| 类型 | 大小 | 范围( 有符号) | 范围( 无符号, unsigned) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 Bytes | (-128 127) | (0 255) | 小整数值 |
| SMALLINT | 2 Bytes | (-32 768 32 767) | (0 65 535) | 大整数值 |
| MEDIUMINT | 3 Bytes | (-8 388 608 8 388 607) | (0 16 777 215) | 大整数值 |
| INT或INTEGER | 4 Bytes | (-2 147 483 648 2 147 483 647) | (0 4 294 967 295) | 大整数值 |
| BIGINT | 8 Bytes | (-9,223,372,036,854,775,808 9 223 372 036 854 775 807) | (0 18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 Bytes | (-3.402 823 466 E+38 -1.175 494 351 E-38) 0 (1.175 494 351 E-38 3.402 823 466 351 E+38) | 0 (1.175 494 351 E-38 3.402 823 466 E+38) | 单精度 浮点数值 |
| DOUBLE | 8 Bytes | (-1.797 693 134 862 315 7 E+308 -2.225 073 858 507 201 4 E-308) 0 (2.225 073 858 507 201 4 E-308 1.797 693 134 862 315 7 E+308) | 0 (2.225 073 858 507 201 4 E-308 1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| DECIMAL | 对DECIMAL(M,D) 如果M>D 为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
# 指定数据的精度的设置, 在浮点数上也将被移除
# unsigned, 无符号, 针对浮点数, 也将移除
# int(11), float(10, 2), 这种写法
# 包括官方文档的示例种这种写法依然还还常见.
mysql> show warnings;
+---------+------+--------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message
|
+---------+------+--------------------------------------------------------------------------------------------------------------------------+
| Warning | 1681 | Specifying number of digits for floating point data types is deprecated and will be removed in a future release.
|
| Warning | 1681 | UNSIGNED for decimal and floating point data types is deprecated and support for it will be removed in a future release. |
| Warning | 1681 | Specifying number of digits for floating point data types is deprecated and will be removed in a future release.
|
| Warning | 1681 | UNSIGNED for decimal and floating point data types is deprecated and support for it will be removed in a future release. |
+---------+------+--------------------------------------------------------------------------------------------------------------------------+
4 rows in set (0.00 sec)
浮点数的处理是计算机中时一个相对麻烦的问题, 对于精度要求特别高的, 需要格外注意精度导致的数据不一致的问题, 高要求应当使用decimal类型的数据.

JavaScript

> 1 === 1.000000000000001;
false
> 1 === 1.0000000000000001
true
> '1.0000000000000001'.length;
18
python
# 长度和js部分的代码一致
print(1 == 1.000000000000001)
// False
print(1 == 1.0000000000000001)
// True
python-pandas

pandas只是展示数据修改精度, 底层还是完整保存读取数据的精度.
2.1.2 日期/时间
| 类型 | 大小 ( bytes) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | '1000-01-01 00:00:00' 到 '9999-12-31 23:59:59' | YYYY-MM-DD hh:mm:ss | 混合日期和时间值 |
| TIMESTAMP | 4 | '1970-01-01 00:00:01' UTC 到 '2038-01-19 03:14:07' UTC结束时间是第 2147483647 秒 北京时间 2038-1-19 11:14:07 格林尼治时间 2038年1月19日 凌晨 03:14:07 | YYYY-MM-DD hh:mm:ss | 混合日期和时间值 时间戳 |
# 时间戳的使用
# 对于核心表, 一般需要加上这两个字段, 以便于在出现问题时回溯
create table test_table(
-- 默认使用当前的时间戳
created_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
-- 设置当数据发生变化时, 更新时间戳
modified_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
);
2.1.3 字符串
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串 |
| VARCHAR | 0-65535 bytes | 变长字符串 |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
需要注意, char, varchar的存储情况.
mysql> create table ta (s char(3));
Query OK, 0 rows affected (0.07 sec)
mysql> insert into ta values ('a'), ('a ');
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
# 默认模式下, char类型对于结尾的空格数据会进行自动的移除操作
mysql> select length(s) from ta;
+-----------+
| length(s) |
+-----------+
| 1 |
| 1 |
+-----------+
2 rows in set (0.00 sec)
mysql> select concat(s, 'b') from ta;
+----------------+
| concat(s, 'b') |
+----------------+
| ab |
| ab |
+----------------+
2 rows in set (0.00 sec
set session sql_mode = 'pad_char_to_full_length';
# 不管你插入的数据的长度如何, 都全部拉宽到3的长度(剩余位置用空格填充)
mysql> set session sql_mode = 'pad_char_to_full_length';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> select length(s) from ta;
+-----------+
| length(s) |
+-----------+
| 3 |
| 3 |
+-----------+
2 rows in set (0.00 sec)
mysql> select concat(s, 'b') from ta;
+----------------+
| concat(s, 'b') |
+----------------+
| a b |
| a b |
+----------------+
2 rows in set (0.00 sec)
# 查看数据的存储
# 行格式有4种 分别是Dynamic Compact Redundant 和Compressed
SHOW VARIABLES LIKE "innodb_default_row_format";
/*
我们常见的 GBK UTF8 UTF8-MB4 这些都是多字节字符集
GBK : 一个字符最多占 2 个字节
UTF8: 一个字符最多占 3 个字节
UTF8MB4: 一个字符最多占 4 个字节
字符集设置为latin1,1个字符=1个字节,字段允许为null
*/
mysql> create table test ( address varchar(65536) default null ) charset=latin1;
ERROR 1074 (42000): Column length too big for column 'address' (max = 65535); use BLOB or TEXT instead
mysql> create table test ( address varchar(65535) not null ) charset=latin1;
ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535.
This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs
mysql> create table test2 ( address varchar(65533) not null ) charset=UTF8;
ERROR 1074 (42000): Column length too big for column 'address' (max = 21845); use BLOB or TEXT instead
mysql> create table test4 (name char(255) not null, address varchar(21590) not null ) charset=utf8;
ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535.
This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs
那么
varchar类型字段的最大字节数应该就是(utf-8)
65535 (行最大字节数) - 255*3 (一个字符最多占 3 个字节) = 64770
然后再减去 2 个长度前缀字节
64770 - 2 = 64768
最后再算出 varchar 最大字符数为 64768 / 3 = 21589.33.
简而言之, 就是varchar, 在存储数据时, 有部分空间用于存储标注字段长度, 以及考虑到null值得存在.
所以其最大的存储空间, 需要将这部分得内容纳入进去. 详细内容见下面两个参考链接.
2.2 内置的库
world,sakila 这两个数据库, 是示例数据库, 在使用MySQL installer安装时, 可以取消安装. 其他的安装方式一般不带有这两个数据库.
show databases;
-- 初始状态的数据库列表(mysql installer)
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sakila |
| sys |
| world |
+--------------------+
# wsl
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.00 sec)
-
information_schema: 提供了访问数据库元数据的方式. 其中保存着关于MySQL服务器所维护的所有其他数据库的信息 如数据库名 表名 列的数据类型 访问权限等. -
mysql: 这个是MySQL的核心数据库. 主要负责存储数据库的用户 权限设置 关键字以及MySQL自己需要使用的控制和管理信息等. -
performance_schema: 主要用于收集数据库服务器性能参数 如提供进程等待的详细信息 包括锁 互斥变量 文件信息; 保存历史的事件汇总信息 为提供MySQL服务器性能做出详细的判断; 对于新增和删除监控事件点都非常容易 并可以改变MySQL服务器的监控周期等. -
sys: 是MySQL5.7新增的系统数据库, 其在MySQL5.7中是默认存在的. 在MySQL5.6及以上版本可以手动导入.这个库通过视图的形式把information_schema和performance_schema结合起来, 查询出更加令人容易理解的数据. -
sakila样本数据库是MySQL官方提供的一个模拟DVD租赁信息管理的数据库 提供了一个标准模式 可作为书中例子,教程 文章 样品,等等 对学习测试来说是个不错的选择. -
world, 样本数据库, 世界城市信息, 如人口等.
2.3 JSON
mysql已经原生支持sql, xml等文档型的数据, 使用场景, 例如产品信息的录入, 假如其属性值不是相对固定的, 则单纯是sql结构存储, 在字段的创建上并不方便将其数据拆分出基础属性和扩展属性, 扩展属性以json的方式存储.(不存在的键值在mysql中并不会像python直接报错).
但是对于构造复杂, 且庞大的数据库, 是否值得引入json结构的字段还是需要谨慎考虑.(是否需要使用mongodb作为数据的补充部分)

CREATE TABLE test_json(
id int auto_increment primary key,
event_name varchar(255),
visitor varchar(255),
properties json,
browser json
);
INSERT INTO test_json(event_name, visitor,properties, browser)
VALUES (
'pageview',
'1',
'{ "page": "/" }',
'{ "name": "Safari", "os": "Mac", "resolution": { "x": 1920, "y": 1080 } }'
),
('pageview',
'2',
'{ "page": "/contact" }',
'{ "name": "Firefox", "os": "Windows", "resolution": { "x": 2560, "y": 1600 } }'
),
(
'pageview',
'1',
'{ "page": "/products" }',
'{ "name": "Safari", "os": "Mac", "resolution": { "x": 1920, "y": 1080 } }'
),
(
'purchase',
'3',
'{ "amount": 200 }',
'{ "name": "Firefox", "os": "Windows", "resolution": { "x": 1600, "y": 900 } }'
),
(
'purchase',
'4',
'{ "amount": 150 }',
'{ "name": "Firefox", "os": "Windows", "resolution": { "x": 1280, "y": 800 } }'
),
(
'purchase',
'4',
'{ "amount": 500 }',
'{ "name": "Chrome", "os": "Windows", "resolution": { "x": 1680, "y": 1050 } }'
);
实际上存储的是json结构的字符串, 也可以通过字符串的方式来检索数据.

insert into test_json (event_name, visitor,properties, browser) values ("test", "5", "test_a", "test_b");
-- error, 不满足json结构的字符串会直接报错

精确查找json结构中的数据, 使用$符号作为标注.
在python(mysql_connector)中, 返回的数据类型也是字符串格式而不是obj, 有别于mongodb(pymongo)的区别.
2.4 大小写
注意表的名称的大小写和字段内容的大小写的敏感差异.
-
Windows下# 查询的时候是不区分大小写的, 针对表名称 mysql> select * from Abc; Empty set (0.02 sec) mysql> show variables like 'lower_case_file_system'; +------------------------+-------+ | Variable_name | Value | +------------------------+-------+ | lower_case_file_system | ON | +------------------------+-------+ 1 row in set (0.01 sec) -
Linux# `Linux`下, 对于检索的`表的名称`是区分大小写的. mysql> select * from Next; ERROR 1146 (42S02): Table 'test_db.Next' doesn't exist mysql> show variables like 'lower_case_file_system'; +------------------------+-------+ | Variable_name | Value | +------------------------+-------+ | lower_case_file_system | OFF | +------------------------+-------+
# 默认状态下, 运算时, 不区分大小写, 不管是Windows还是Linux
mysql> select "a" = "A";
+-----------+
| "a" = "A" |
+-----------+
| 1 |
+-----------+
1 row in set (0.00 sec)
mysql> select ('a' = "A");
+-------------+
| ('a' = "A") |
+-------------+
| 1 |
+-------------+
1 row in set (0.02 sec)
mysql> select binary "a" = "A";
+------------------+
| binary "a" = "A" |
+------------------+
| 0 |
+------------------+
1 row in set, 1 warning (0.00 sec)
# utf8mb4_0900_ai_ci, ci (case insensitive)
mysql> show table status from test_db like 'test';
+------+--------+---------+------------+------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+-------------+------------+--------------------+----------+----------------+---------+
| Name | Engine | Version | Row_format | Rows | Avg_row_length | Data_length | Max_data_length | Index_length | Data_free | Auto_increment | Create_time | Update_time | Check_time | Collation | Checksum | Create_options | Comment |
+------+--------+---------+------------+------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+-------------+------------+--------------------+----------+----------------+---------+
| test | InnoDB | 10 | Dynamic | 2 | 24576 | 49152 | 0 | 0 |
0 | NULL | 2023-01-17 12:20:43 | NULL | NULL | utf8mb4_0900_ai_ci | NULL | partitioned | |
+------+--------+---------+------------+------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+-------------+------------+--------------------+----------+----------------+---------+
1 row in set (0.03 sec)
# 对字段的内容就进行控制, 强制对字段要求大小写敏感
mysql> create table test_k (name char(4) binary);
Query OK, 0 rows affected, 1 warning (0.11 sec)
mysql> insert into test_k values ('aA');
Query OK, 1 row affected (0.01 sec)
mysql> select * from test_k where name = 'aa';
Empty set (0.00 sec)
mysql> select * from test_k where name = 'aA';
+------+
| name |
+------+
| aA |
+------+
1 row in set (0.00 sec)
# utf8mb4_bin
mysql> show full columns from test_k;
+-------+---------+-------------+------+-----+---------+-------+---------------------------------+---------+
| Field | Type | Collation | Null | Key | Default | Extra | Privileges | Comment |
+-------+---------+-------------+------+-----+---------+-------+---------------------------------+---------+
| name | char(4) | utf8mb4_bin | YES | | NULL | | select,insert,update,references | |
+-------+---------+-------------+------+-----+---------+-------+---------------------------------+---------+
1 row in set (0.00 sec)
# 手动修改某个字段的大小写敏感
alter table test3 modify name varchar(20) collate utf8_bin;
2.5 sql_mode
mysql> show variables like 'sql_mode';
+---------------+-----------------------------------------------------------------------------------------------------------------------+
| Variable_name | Value |
+---------------+-----------------------------------------------------------------------------------------------------------------------+
| sql_mode | ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION |
+---------------+-----------------------------------------------------------------------------------------------------------------------+
1 row in set (0.02 sec)
| mode | 含义 | 作用 |
|---|---|---|
| ONLY_FULL_GROUP_BY | 对于GROUP BY聚合操作 如果在SELECT中的列 没有在GROUP BY中出现 那么将认为这个SQL是不合法的 因为列不在GROUP BY从句中 | 聚合操作相关 |
STRICT_TRANS_TABLES |
在该模式下 如果一个值不能插入到一个事务表中 则中断当前的操作 对非事务表不做任何限制.简而言之, 就是遇到错误回滚, 保持原数据的完整. | 插入数据控制 |
NO_ZERO_IN_DATE |
在严格模式 不接受月或日部分为0的日期. 如果使用IGNORE选项 我们为类似的日期插入'0000-00-00'. 在非严格模式 可以接受该日期 但会生成警告. | 日期相关 |
NO_ZERO_DATE |
在严格模式 不要将 '0000-00-00'做为合法日期. 你仍然可以用IGNORE选项插入零日期. 在非严格模式 可以接受该日期 但会生成警告 | 日期相关 |
ERROR_FOR_DIVISION_BY_ZERO |
在严格模式 在INSERT或UPDATE过程中 如果被零除(或MOD(X 0)) 则产生错误(否则为警告). 如果未给出该模式 被零除时MySQL返回NULL. 如果用到INSERT IGNORE或UPDATE IGNORE中 MySQL生成被零除警告 但操作结果为NULL. | 插入内容检查 |
NO_AUTO_CREATE_USER |
防止GRANT自动创建新用户 除非还指定了密码. | 创建用户 |
NO_ENGINE_SUBSTITUTION |
如果需要的存储引擎被禁用或未编译 那么抛出错误. 不设置此值时 用默认的存储引擎替代 并抛出一个异常. | |
pad_char_to_full_length |
控制char类型字段对于尾部空格的处理(As of MySQL 8.0.13, PAD_CHAR_TO_FULL_LENGTH is deprecated. Expect it to be removed in a future version of MySQL.) |
字段设置 |
2.6 分区
- 分区字段必须是整数类型或解析为整数的表达式.
- 分区字段建议设置为
NOT NULL, 若某行数据分区字段为null, 在RANGE分区中, 该行数据会划分到最小的分区里.MySQL分区中如果存在主键或唯一键, 则分区列必须包含在其中.Innodb分区表不支持外键.- 更改
sql_mode模式可能影响分区表的表现.- 分区表不影响自增列.
分区的使用场景:
这类表的特点是数据量大, 并且有冷热数据区分, 可以按照时间维度来进行数据归档. 这类表是比较适合使用分区表的, 因为分区表可以对单独的分区进行维护, 对于数据归档更方便
分区和外键约束从使用的角度来看(除非有足够的时间去测试性能, 使用等各种细节), 否则使用起来平添麻烦.
- 替代性强, 如可以直接建立新的表即可.
- 增加维护的成本, 和其他的表形成差异(还需要考虑进一步的延申, 如数据规模, 数据整体查询, 集群等的影响).
- 自身的优势并不明显.
分区表的主要分类
RANGE分区: 基于属于一个给定连续区间的列值 把多行分配给分区.
LIST分区: 类似于按RANGE分区 区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择.
HASH分区: 基于用户定义的表达式的返回值来进行选择的分区 该表达式使用将要插入到表中的这些行的列值进行计算. 这个函数可以包含MySQL 中有效的 产生非负整数值的任何表达式.
KEY分区: 类似于按HASH分区 区别在于KEY分区只支持计算一列或多列 且MySQL服务器提供其自身的哈希函数. 必须有一列或多列包含整数值.
复合分区: 在MySQL 5.6版本中 只支持RANGE和LIST的子分区 且子分区的类型只能为HASH和KEY.
create table test (id int, col varchar(16), c_year date)
PARTITION BY RANGE( YEAR(c_year) )(
PARTITION previous values less than (2000),
PARTITION middle values less than (2010)
);
mysql> desc test;
+--------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+-------------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| col | varchar(16) | YES | | NULL | |
| c_year | date | YES | | NULL | |
+--------+-------------+------+-----+---------+-------+
3 rows in set (0.01 sec)
# 插入数据直接报错, 假如没有对应的数据分区
mysql> insert into test values (1, 'a', '2011-01-02'), (2, 'b', '2022-11-04'), (3, 'c', '1991-1-2'), (4, 'd', '2004-01-1');
ERROR 1526 (HY000): Table has no partition for value 2011
# 变更为
create table test (id int, col varchar(16), c_year date)
PARTITION BY RANGE( YEAR(c_year) )(
PARTITION previous values less than (2000),
PARTITION middle values less than (2010),
PARTITION others values less than (2038)
);
mysql> select * from test;
+------+------+------------+
| id | col | c_year |
+------+------+------------+
| 3 | c | 1991-01-02 |
| 4 | d | 2004-01-01 |
| 1 | a | 2011-01-02 |
| 2 | b | 2022-11-04 |
+------+------+------------+
4 rows in set (0.00 sec)
mysql> select PARTITION_NAME as "分区",TABLE_ROWS as "行数" from information_schema.partitions where table_schema="test_db" and table_name="test";
+----------+--------+
| 分区 | 行数 |
+----------+--------+
| middle | 1 |
| others | 2 |
| previous | 1 |
+----------+--------+
3 rows in set (0.00 sec)
# 显然这里会问 为什么不直接select * from table_middle;
# 而需要间接访问
mysql> select * from test partition(middle);
+------+------+------------+
| id | col | c_year |
+------+------+------------+
| 4 | d | 2004-01-01 |
+------+------+------------+
1 row in set (0.00 sec)
# 新增分区
alter table test add partition (
pARTITION hot_data VALUES LESS THAN (2024)
);
# 拆分分区
alter table test reorganize partition other into(
pARTITION main_data VALUES LESS THAN (2020),
pARTITION hot_data VALUES LESS THAN (2024)
);
# 将分区合并到新的分区
alter table test reorganize partition previous, middle into
partition old_data values less than (2010)
);
# 清空分区
alter table test truncate partition middle;
# 删除分区
alter table test drop partition middle;
2.7 临时表/衍生表
# 通常情况下
select * from (select * from table) as t1 where t1.id = 1;
# 为了区分开来, 称t1作衍生表/派生表
(select * from table) as t1 习惯可能会将t1称作临时表.
但实际上MySQL有专门的临时表TEMPORARY.
用于作为诸如数据分析, 可能需要反复对特定的数据(在这期间不担心源数据发生改变)进行查询, 或者是其他的操作. 临时表相当于将数据缓存起来, 方便反复调用数据.
注意: 临时表的数据并不会随着源数据发生改变而改变.
mysql> CREATE TEMPORARY TABLE top10customers
-> SELECT p.customerNumber,
-> c.customerName,
-> ROUND(SUM(p.amount),2) sales
-> FROM payments p
R JOIN cust -> INNER JOIN customers c ON c.customerNumber = p.customerNumber
Y p.cus -> GROUP BY p.customerNumber
-> ORDER BY sales DESC
-> LIMIT 10;
Query OK, 10 rows affected (0.00 sec)
Records: 10 Duplicates: 0 Warnings: 0
mysql> select * from top10customers;
+----------------+------------------------------+-----------+
| customerNumber | customerName | sales |
+----------------+------------------------------+-----------+
| 141 | Euro+ Shopping Channel | 715738.98 |
| 124 | Mini Gifts Distributors Ltd. | 584188.24 |
| 114 | Australian Collectors, Co. | 180585.07 |
| 151 | Muscle Machine Inc | 177913.95 |
| 148 | Dragon Souveniers, Ltd. | 156251.03 |
| 323 | Down Under Souveniers, Inc | 154622.08 |
| 187 | AV Stores, Co. | 148410.09 |
| 276 | Anna's Decorations, Ltd | 137034.22 |
| 321 | Corporate Gift Ideas Co. | 132340.78 |
| 146 | Saveley & Henriot, Co. | 130305.35 |
+----------------+------------------------------+-----------+
10 rows in set (0.00 sec)
# 删除掉某个临时表
drop TEMPORARY TABLE temp_table_name;
2.8 衍生列
generated column, 衍生列, 可以根据条件(建立表时设置的条件)自动生成/更新数据.
mysql> create table test1(
-> col1 int primary key,
-> col2 int generated always as (col1+7) stored
-> );
Query OK, 0 rows affected (0.01 sec)
mysql> desc test1;
+-------+---------+------+-----+---------+------------------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+------------------+
| col1 | int(11) | NO | PRI | NULL | |
| col2 | int(11) | YES | | NULL | STORED GENERATED |
+-------+---------+------+-----+---------+------------------+
2 rows in set (0.00 sec)
mysql> insert into test1(col1) values (1);
Query OK, 1 row affected (0.01 sec)
mysql> select * from test1;
+------+------+
| col1 | col2 |
+------+------+
| 1 | 8 |
+------+------+
1 row in set (0.00 sec)

2.9 用户管理
# 查看当前用户
mysql> select user();
+----------------+
| user() |
+----------------+
| root@localhost |
+----------------+
# wsl, 中MySQL预置的用户
mysql> select user from user;
+------------------+
| user |
+------------------+
| debian-sys-maint |
| mysql.infoschema |
| mysql.session |
| mysql.sys |
| root |
+------------------+
5 rows in set (0.00 sec)
2.9.1 2.9.1安全验证方式

mysql> select user,host,plugin from mysql.user;
+------------------+-----------+-----------------------+
| user | host | plugin |
+------------------+-----------+-----------------------+
| debian-sys-maint | localhost | caching_sha2_password |
| mysql.infoschema | localhost | caching_sha2_password |
| mysql.session | localhost | caching_sha2_password |
| mysql.sys | localhost | caching_sha2_password |
| root | localhost | mysql_native_password |
| test_user | localhost | caching_sha2_password |
+------------------+-----------+-----------------------+
6 rows in set (0.00 sec)
# wsl中刚装好的mysql
mysql> select user,host,plugin from mysql.user;
+------------------+-----------+-----------------------+
| user | host | plugin |
+------------------+-----------+-----------------------+
| debian-sys-maint | localhost | caching_sha2_password |
| mysql.infoschema | localhost | caching_sha2_password |
| mysql.session | localhost | caching_sha2_password |
| mysql.sys | localhost | caching_sha2_password |
| root | localhost | auth_socket |
+------------------+-----------+-----------------------+
5 rows in set (0.00 sec)
caching_sha2_password, 是MySQL8.x默认的身份验证方式, 兼容5.x的验证方式.mysql_native_password, 是MySQL5.x默认的身份验证方式, 不支持8.x的验证方式.
-- 默认
create user test_user@localhost identified by '789';
# 5.x, mysql_native_password
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '123456';
# 强制变更配置验证方式
[mysqld]
default-authentication-plugin=sha256_password
# 临时选择方式
mysql> CREATE USER 'sha256user'@'localhost' IDENTIFIED WITH sha256_password BY 'password';
Query OK, 0 rows affected (0.01 sec)
mysql> select user,host,plugin from mysql.user;
+------------------+-----------+-----------------------+
| user | host | plugin |
+------------------+-----------+-----------------------+
| debian-sys-maint | localhost | caching_sha2_password |
| mysql.infoschema | localhost | caching_sha2_password |
| mysql.session | localhost | caching_sha2_password |
| mysql.sys | localhost | caching_sha2_password |
| root | localhost | mysql_native_password |
| sha256user | localhost | sha256_password |
| test_user | localhost | caching_sha2_password |
+------------------+-----------+-----------------------+
7 rows in set (0.00 sec)
mysql> CREATE USER 'cache_user'@'localhost' IDENTIFIED WITH caching_sha2_password BY 'password';
Query OK, 0 rows affected (0.01 sec)
mysql> select user,host,plugin from mysql.user;
+------------------+-----------+-----------------------+
| user | host | plugin |
+------------------+-----------+-----------------------+
| cache_user | localhost | caching_sha2_password |
| debian-sys-maint | localhost | caching_sha2_password |
| mysql.infoschema | localhost | caching_sha2_password |
| mysql.session | localhost | caching_sha2_password |
| mysql.sys | localhost | caching_sha2_password |
| root | localhost | mysql_native_password |
| sha256user | localhost | sha256_password |
| test_user | localhost | caching_sha2_password |
+------------------+-----------+-----------------------+
8 rows in set (0.00 sec)
# 变更安全的验证方式
ALTER USER 'root'@'localhost' IDENTIFIED WITH caching_sha2_password BY '123456';
# 必须加上 with caching_sha2_password具体的方式
- MySQL :: MySQL 8.0 Reference Manual :: 6.4.1 Authentication Plugins
- MySQL新密码机制介绍caching_sha2_password - 懒睡的猫熊 - 博客园 (cnblogs.com)
2.9.2 2.9.2权限
默认状态下的root权限:
| Host | localhost |
|---|---|
| User | root |
| Select_priv | Y |
| Insert_priv | Y |
| Update_priv | Y |
| Delete_priv | Y |
| Create_priv | Y |
| Drop_priv | Y |
| Reload_priv | Y |
| Shutdown_priv | Y |
| Process_priv | Y |
| File_priv | Y |
| Grant_priv | Y |
| References_priv | Y |
| Index_priv | Y |
| Alter_priv | Y |
| Show_db_priv | Y |
| Super_priv | Y |
| Create_tmp_table_priv | Y |
| Lock_tables_priv | Y |
| Execute_priv | Y |
| Repl_slave_priv | Y |
| Repl_client_priv | Y |
| Create_view_priv | Y |
| Show_view_priv | Y |
| Create_routine_priv | Y |
| Alter_routine_priv | Y |
| Create_user_priv | Y |
| Event_priv | Y |
| Trigger_priv | Y |
| Create_tablespace_priv | Y |
| ssl_type | |
| ssl_cipher | |
| x509_issuer | |
| x509_subject | |
| max_questions | 0 |
| max_updates | 0 |
| max_connections | 0 |
| max_user_connections | 0 |
| plugin | mysql_native_password |
| authentication_string | *6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9 |
| password_expired | N |
| password_last_changed | ######## |
| password_lifetime | |
| account_locked | N |
| Create_role_priv | Y |
| Drop_role_priv | Y |
| Password_reuse_history | |
| Password_reuse_time | |
| Password_require_current | |
| User_attributes |
# 获取当前的用户权限.
mysql> show grants \G
*************************** 1. row ***************************
Grants for root@localhost: GRANT SELECT, INSERT, UPDATE, DELETE, CREATE, DROP, RELOAD, SHUTDOWN, PROCESS, FILE, REFERENCES, INDEX, ALTER, SHOW DATABASES, SUPER, CREATE TEMPORARY TABLES, LOCK TABLES, EXECUTE, REPLICATION SLAVE, REPLICATION CLIENT, CREATE VIEW, SHOW VIEW, CREATE ROUTINE, ALTER ROUTINE, CREATE USER, EVENT, TRIGGER, CREATE TABLESPACE, CREATE ROLE, DROP ROLE ON *.* TO `root`@`localhost` WITH GRANT OPTION
*************************** 2. row ***************************
Grants for root@localhost: GRANT APPLICATION_PASSWORD_ADMIN,AUDIT_ABORT_EXEMPT,AUDIT_ADMIN,AUTHENTICATION_POLICY_ADMIN,BACKUP_ADMIN,BINLOG_ADMIN,BINLOG_ENCRYPTION_ADMIN,CLONE_ADMIN,CONNECTION_ADMIN,ENCRYPTION_KEY_ADMIN,FIREWALL_EXEMPT,FLUSH_OPTIMIZER_COSTS,FLUSH_STATUS,FLUSH_TABLES,FLUSH_USER_RESOURCES,GROUP_REPLICATION_ADMIN,GROUP_REPLICATION_STREAM,INNODB_REDO_LOG_ARCHIVE,INNODB_REDO_LOG_ENABLE,PASSWORDLESS_USER_ADMIN,PERSIST_RO_VARIABLES_ADMIN,REPLICATION_APPLIER,REPLICATION_SLAVE_ADMIN,RESOURCE_GROUP_ADMIN,RESOURCE_GROUP_USER,ROLE_ADMIN,SENSITIVE_VARIABLES_OBSERVER,SERVICE_CONNECTION_ADMIN,SESSION_VARIABLES_ADMIN,SET_USER_ID,SHOW_ROUTINE,SYSTEM_USER,SYSTEM_VARIABLES_ADMIN,TABLE_ENCRYPTION_ADMIN,XA_RECOVER_ADMIN ON *.*
TO `root`@`localhost` WITH GRANT OPTION
*************************** 3. row ***************************
Grants for root@localhost: GRANT PROXY ON ``@`` TO `root`@`localhost` WITH GRANT OPTION
3 rows in set (0.00 sec)
# 查看支持的权限
mysql> show privileges;
+------------------------------+---------------------------------------+-------------------------------------------------------+
| Privilege | Context | Comment |
+------------------------------+---------------------------------------+-------------------------------------------------------+
| Alter(修改表(结构)) | Tables | To alter the table |
| Alter routine(修改或者删除函数/存储过程) | Functions,Procedures | To alter or drop stored functions/procedures |
| Create(数据库, 表, 索引) | Databases,Tables,Indexes | To create new databases and tables |
| Create routine(函数/存储过程) | Databases | To use CREATE FUNCTION/PROCEDURE |
| Create role(创建角色) | Server Admin | To create new roles |
| Create temporary tables(创建临时表) | Databases | To use CREATE TEMPORARY TABLE |
| Create view(创建视图) | Tables | To create new views |
| Create user(创建用户) | Server Admin | To create new users |
| Delete(删除表行) | Tables | To delete existing rows |
| Drop(删除数据库, 表) | Databases,Tables | To drop databases, tables, and views |
| Drop role(删除角色) | Server Admin | To drop roles |
| Event(删除或者创建时间) | Server Admin | To create, alter, drop and execute events |
| Execute(执行函数或者存储过程) | Functions,Procedures | To execute stored routines |
| File(读取或者写入文件) | File access on server | To read and write files on the server |
| Grant option(批准权限给其他的用户) | Databases,Tables,Functions,Procedures | To give to other users those privileges you possess |
| Index(创建或者删除索引) | Tables | To create or drop indexes |
| Insert(插入数据) | Tables | To insert data into tables |
| Lock tables(锁定表格) | Databases | To use LOCK TABLES (together with SELECT privilege) |
| Process | Server Admin | To view the plain text of currently executing queries |
| Proxy(代理相关) | Server Admin | To make proxy user possible |
| References | Databases,Tables | To have references on tables |
| Reload(重载/刷新表, 日志/权限) | Server Admin | To reload or refresh tables, logs and privileges |
| Replication client(主从相关) | Server Admin | To ask where the slave or master servers are |
| Replication slave | Server Admin | To read binary log events from the master |
| Select(查询) | Tables | To retrieve rows from table |
| Show databases(查看数据库) | Server Admin | To see all databases with SHOW DATABASES |
| Show view(查看视图) | Tables | To see views with SHOW CREATE VIEW |
| Shutdown(关闭服务器) | Server Admin | To shut down the server |
| Super(超级权限, 例如关闭线程) | Server Admin | To use KILL thread, SET GLOBAL, CHANGE MASTER, etc. |
| Trigger(使用触发器) | Tables | To use triggers |
| Create tablespace(创建/删除/修改表空间) | Server Admin | To create/alter/drop tablespaces |
| Update(更新表行) | Tables | To update existing rows |
| Usage(基础权限, 仅限于连接) | Server Admin | No privileges - allow connect only |
| FIREWALL_EXEMPT | Server Admin | |
| AUDIT_ABORT_EXEMPT | Server Admin | |
| XA_RECOVER_ADMIN | Server Admin | |
| TABLE_ENCRYPTION_ADMIN | Server Admin | |
| SYSTEM_VARIABLES_ADMIN | Server Admin | |
| FLUSH_STATUS | Server Admin | |
| CONNECTION_ADMIN | Server Admin | |
| ENCRYPTION_KEY_ADMIN | Server Admin | |
| INNODB_REDO_LOG_ARCHIVE | Server Admin | |
| CLONE_ADMIN | Server Admin | |
| BINLOG_ENCRYPTION_ADMIN | Server Admin | |
| FLUSH_TABLES | Server Admin | |
| BACKUP_ADMIN | Server Admin | |
| AUTHENTICATION_POLICY_ADMIN | Server Admin | |
| REPLICATION_APPLIER | Server Admin | |
| GROUP_REPLICATION_STREAM | Server Admin | |
| REPLICATION_SLAVE_ADMIN | Server Admin | |
| FLUSH_OPTIMIZER_COSTS | Server Admin | |
| SESSION_VARIABLES_ADMIN | Server Admin | |
| APPLICATION_PASSWORD_ADMIN | Server Admin | |
| SYSTEM_USER | Server Admin | |
| RESOURCE_GROUP_ADMIN | Server Admin | |
| AUDIT_ADMIN | Server Admin | |
| FLUSH_USER_RESOURCES | Server Admin | |
| GROUP_REPLICATION_ADMIN | Server Admin | |
| INNODB_REDO_LOG_ENABLE | Server Admin | |
| PASSWORDLESS_USER_ADMIN | Server Admin | |
| ROLE_ADMIN | Server Admin | |
| BINLOG_ADMIN | Server Admin | |
| PERSIST_RO_VARIABLES_ADMIN | Server Admin | |
| RESOURCE_GROUP_USER | Server Admin | |
| SENSITIVE_VARIABLES_OBSERVER | Server Admin | |
| SERVICE_CONNECTION_ADMIN | Server Admin | |
| SHOW_ROUTINE | Server Admin | |
| SET_USER_ID | Server Admin | |
+------------------------------+---------------------------------------+-------------------------------------------------------+
68 rows in set (0.00 sec)
由于权限非常多, 主要看非Server Admin 级别的权限.
2.9.3 2.9.3用户管理
用户名的完整构成:
'test_user'@'%'
# 用户名 @ ip地址(%, 表示全部)
mysql> create user test_user@localhost identified by '789';
Query OK, 0 rows affected (0.02 sec)
mysql> select user from mysql.user;
+------------------+
| user |
+------------------+
| debian-sys-maint |
| mysql.infoschema |
| mysql.session |
| mysql.sys |
| root |
| test_user |
+------------------+
6 rows in set (0.00 sec)
# 默认创建, 只有连接登录MySQL的权限
mysql> SHOW GRANTS FOR 'test_user'@'localhost';
+-----------------------------------------------+
| Grants for test_user@localhost |
+-----------------------------------------------+
| GRANT USAGE ON *.* TO `test_user`@`localhost` |
+-----------------------------------------------+
1 row in set (0.00 sec)
# 查看具体的用户权限
select * from mysql.user where user='test_db_user';
or
mysql> show grants for 'sha256user'@'localhost';
+---------------------------------------------------------------------------------------------------------+
| Grants for sha256user@localhost |
+---------------------------------------------------------------------------------------------------------+
| GRANT USAGE ON *.* TO `sha256user`@`localhost` |
| GRANT SELECT, INSERT, UPDATE, DELETE, CREATE, ALTER, EXECUTE ON `test_db`.* TO `sha256user`@`localhost` |
+---------------------------------------------------------------------------------------------------------+
2 rows in set (0.00 sec)
# 刷新权限
FLUSH PRIVILEGES;
由于权限选项较多, 在sql语句中并不好管理和设置.
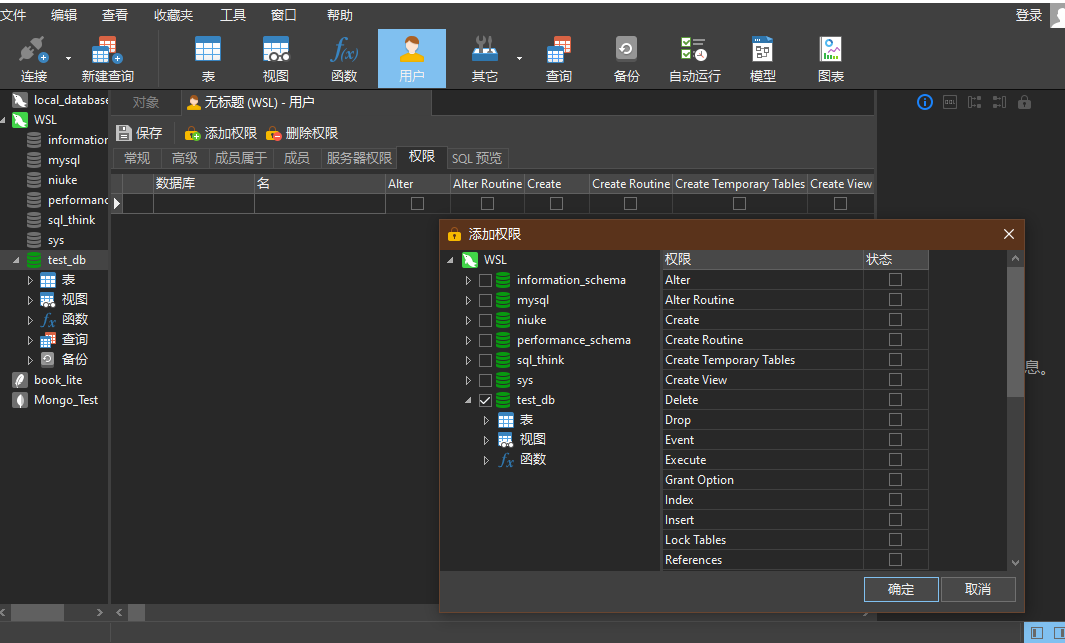
navicat提供更为直观的图形界面设置
上述设置:
- 创建一个只针对数据库
test_db的用户 - 允许这个用户可以在test_db中进行任意的操作
- 不允许访问其他的数据库.
同步自动生成sql语句.
# 在test_db用户之下, 能够查看的数据库
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| performance_schema |
| test_db |
+--------------------+
3 rows in set (0.00 sec)
# 创建数据库
mysql> create database test_db_a;
ERROR 1044 (42000): Access denied for user 'test_db_user'@'localhost' to database 'test_db_a'
# 删除用户
mysql> DROP USER IF EXISTS test_user;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> show warnings;
+-------+------+--------------------------------------------------+
| Level | Code | Message |
+-------+------+--------------------------------------------------+
| Note | 3162 | Authorization ID 'test_user'@'%' does not exist. |
+-------+------+--------------------------------------------------+
1 row in set (0.00 sec)
mysql> DROP USER IF EXISTS test_user@localhost;
Query OK, 0 rows affected (0.01 sec)
-
赋予权限
# 赋予root的权限 grant all privileges on *.* to 'alex'@'localhost'; # 在wsl/linux下, 将直接以用户名进行登录 (base) alex@DESKTOP-F6VO5U4:/mnt/c/Users/Lian$ mysql -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 18 Server version: 8.0.31-0ubuntu0.20.04.2 (Ubuntu) Copyright (c) 2000, 2022, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> #全局权限 GRANT super,select on *.* to 'sha256user'@'localhost'; #库权限 GRANT select,insert,update,delete,create,alter,execute on `test_db`.* to 'sha256user'@'localhost'; #表权限 GRANT select,insert on `testdb`.test_table to 'sha256user'@'localhost'; #列权限 GRANT select (col1), insert (col1, col2) ON `test_db`.test_table to 'sha256user'@'localhost'; -
撤销权限
# 撤销部分的权限 REVOKE priv_type [(column_list)] [, priv_type [(column_list)]] ... ON [object_type] priv_level FROM user [, user] ... # 撤销全部的 REVOKE ALL [PRIVILEGES], GRANT OPTION FROM user [, user] ...mysql> show grants for 'sha256user'@'localhost'; +---------------------------------------------------------------------------------------------------------+ | Grants for sha256user@localhost | +---------------------------------------------------------------------------------------------------------+ | GRANT USAGE ON *.* TO `sha256user`@`localhost` | | GRANT SELECT, INSERT, UPDATE, DELETE, CREATE, ALTER, EXECUTE ON `test_db`.* TO `sha256user`@`localhost` | +---------------------------------------------------------------------------------------------------------+ 2 rows in set (0.00 sec) # 撤销掉 select 权限从数据库test_db mysql> revoke select on `test_db`.* from 'sha256user'@'localhost'; Query OK, 0 rows affected (0.01 sec) mysql> show grants for 'sha256user'@'localhost'; +-------------------------------------------------------------------------------------------------+ | Grants for sha256user@localhost | +-------------------------------------------------------------------------------------------------+ | GRANT USAGE ON *.* TO `sha256user`@`localhost` | | GRANT INSERT, UPDATE, DELETE, CREATE, ALTER, EXECUTE ON `test_db`.* TO `sha256user`@`localhost` | +-------------------------------------------------------------------------------------------------+ 2 rows in set (0.00 sec)
2.10 查询缓存
从各种资料来看, 查询缓存已经名存实亡.
Although MySQL Query Cache was meant to improve performance, it has serious scalability issues and it can easily become a severe bottleneck
mysql> show variables like '%query_cache%';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| have_query_cache | NO |
+------------------+-------+
1 row in set (0.00 sec)
2.11 视图
MySQL supports views, including updatable views. Views are stored queries that when invoked produce a result set. A view acts as a virtual table.
虚拟表的角色
视图的一个明显的好处在于控制数据的可访问范围, 将这种控制精确到每个细节, 如字段.
mysql> create view test_j_v as select * from test_j limit 100;
Query OK, 0 rows affected (0.02 sec)
# 视图也出现表中
mysql> show tables;
+-------------------+
| Tables_in_test_db |
+-------------------+
| sales |
| t1 |
| t2 |
| test |
| test_a |
| test_b |
| test_d |
| test_e |
| test_f |
| test_g |
| test_h |
| test_i |
| test_j | #
| test_j_v | # 创建的基于test_j的视图
| test_k |
| test_table |
| user_trade |
+-------------------+
17 rows in set (0.00 sec)
# 和表一样, 查看结构
# 但是需要注意原表有索引, 在视图上是没有这个的
mysql> desc test_j_v;
+---------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+----------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| name | char(4) | YES | | NULL | |
| address | char(64) | YES | | NULL | |
+---------+----------+------+-----+---------+-------+
3 rows in set (0.00 sec)
# 查看创建的语句
mysql> show create view test_j_v;
+----------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------+----------------------+
| View | Create View
| character_set_client | collation_connection |
+----------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------+----------------------+
| test_j_v | CREATE ALGORITHM=UNDEFINED DEFINER=`alex`@`localhost` SQL SECURITY DEFINER VIEW `test_j_v` AS select `test_j`.`id` AS `id`,`test_j`.`name` AS `name`,`test_j`.`address` AS `address` from `test_j` limit 100 | utf8mb4
| utf8mb4_0900_ai_ci |
+----------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------+----------------------+
1 row in set (0.00 sec)
mysql> select * from test_j_v limit 1;
+------+-----------+---------------------------------------------+
| id | name | address |
+------+-----------+---------------------------------------------+
| 433 | 顾宇宁 | 中国北京市房山区岳琉路992号1室 |
+------+-----------+---------------------------------------------+
1 row in set (0.00 sec)
# 更新数据源表, 数据会自动更新到视图上
mysql> update test_j set name = '顾先生' where id = '433';
mysql> select * from test_j limit 1;
+------+-----------+---------------------------------------------+
| id | name | address |
+------+-----------+---------------------------------------------+
| 433 | 顾先生 | 中国北京市房山区岳琉路992号1室 |
+------+-----------+---------------------------------------------+
1 row in set (0.00 sec)
mysql> select * from test_j_v limit 1;
+------+-----------+---------------------------------------------+
| id | name | address |
+------+-----------+---------------------------------------------+
| 433 | 顾先生 | 中国北京市房山区岳琉路992号1室 |
+------+-----------+---------------------------------------------+
1 row in set (0.00 sec)
# 为源数据表增加索引
mysql> create index index_id on test_j (id);
Query OK, 0 rows affected (0.10 sec)
Records: 0 Duplicates: 0 Warnings:
mysql> desc test_j;
+---------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+----------+------+-----+---------+-------+
| id | int | YES | MUL | NULL | |
| name | char(4) | YES | | NULL | |
| address | char(64) | YES | | NULL | |
+---------+----------+------+-----+---------+-------+
3 rows in set (0.00 sec)
# 试图无索引
mysql> desc test_j_v;
+---------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+----------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| name | char(4) | YES | | NULL | |
| address | char(64) | YES | | NULL | |
+---------+----------+------+-----+---------+-------+
3 rows in set (0.01 sec)
# 对视图进行更新操作的限制
# 假如视图是可允许更新的, 在视图上的操作会同步到源表中
mysql> create view test_m_v as select * from test_m where id < 100;
Query OK, 0 rows affected (0.01 sec)
mysql> delete from test_m_v where id = 3;
Query OK, 1 row affected (0.00 sec)
mysql> create view test_m_v_a as select * from test_m limit 100;
Query OK, 0 rows affected (0.01 sec)
mysql> delete from test_m_v_a where id = 3;
ERROR 1288 (HY000): The target table test_m_v_a of the DELETE is not updatable
# 但是需要注意创建索引, 无法创建, 不是基础表
mysql> create index j_v_index on test_j_v (name);
ERROR 1347 (HY000): 'test_db.test_j_v' is not BASE TABLE
# 删除操作针对视图
mysql> delete from test_j_v where id =433;
ERROR 1288 (HY000): The target table test_j_v of the DELETE is not updatable
# 删除视图
drop view test_j_v;
在MySQL中 视图不仅可查询 还可以更新. 这意味着您可以使用INSERT或 UPDATE语句通过可更新视图插入或更新基表的行. 此外 您可以使用DELETE语句通过视图删除基础表的行.
三. 基本命令
基本情况查询和管理.
-- 查看帮助
help
-- 查看具体的项的帮助
help show
-- ------------------------------------- 查看帮助文档
mysql> help in;
Name: 'IN'
Description:
Syntax:
expr IN (value,...)
Returns 1 (true) if expr is equal to any of the values in the IN()
list, else returns 0 (false).
Type conversion takes place according to the rules described in
https://dev.mysql.com/doc/refman/8.0/en/type-conversion.html, applied
to all the arguments. If no type conversion is needed for the values in
the IN() list, they are all non-JSON constants of the same type, and
expr can be compared to each of them as a value of the same type
(possibly after type conversion), an optimization takes place. The
values the list are sorted and the search for expr is done using a
binary search, which makes the IN() operation very quick.
URL: https://dev.mysql.com/doc/refman/8.0/en/comparison-operators.html
Examples:
mysql> SELECT 2 IN (0,3,5,7);
-> 0
mysql> SELECT 'wefwf' IN ('wee','wefwf','weg');
-> 1
-- ---------------------------------------------------------------
-- dual, mysql中的虚拟表
SELECT VERSION() from DUAL;
-- 二者是等价的, 都是查看mysql版本
SELECT VERSION();
-- 查看所有的表
show tables;
-- 查看数据库中表的情况, 表的数据大小, 索引大小等
show table status from db_name;
-- 查看表的创建sql语句, 将包含engine等信息
show create table table_name;
# 注意, 返回的内容不支持中文内容显示?
# 查看所有的表行数
select count(*) from table_name;
-- count(*), 包含null的行也会计算进来, 有别于count(col_name)
desc table_name;
# 查看表字段
show columns from table_name;
# 更详细
show full columns from table_name;
# 查看数据库, 索引等存储大小情况
show table status from test_db;
-- 修改数据库登录密码
mysqladmin -uroot -pOld_pwd password new_pwd;
-- 查看用户的连接情况
show processlist;
# 强制杀死某个进程
kill process_id;
SELECT user, host, db, command FROM information_schema.processlist;
# 查看所有的用户
SELECT user FROM mysql.user;
# 查看当前用户
select user();
-- 等价
SELECT current_user();
# 查看用户的具体权限
select * from mysql.user where user=user_name \G
# 查看变量, 这里查找带有cache的变量
show variables like '%cache%';
# 查看主从
show slave status\G
四. 四. 日志
- 重做日志(
redo log) - 回滚日志(
undo log) - 二进制日志(
binlog) - 错误日志(
errorlog) - 慢查询日志(
slow query log) - 一般查询日志(
general log) - 中继日志(
relay log)
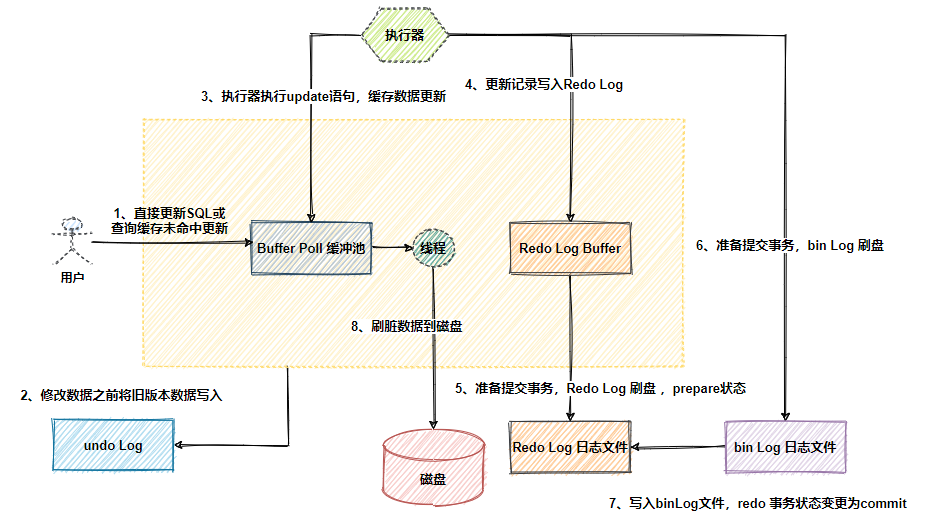
redo log, undo log, binlog三大日志构成了MySQL保障数据在完整性, 容灾处理, 安全等方面核心部分.
注意: 并不是所有的引擎都会启用上述的日志.
-- 产看日志的情况
show master logs;
mysql> show master logs;
+---------------+-----------+-----------+
| Log_name | File_size | Encrypted |
+---------------+-----------+-----------+
| binlog.000001 | 140126119 | No |
| binlog.000002 | 157 | No |
| binlog.000003 | 6837022 | No |
+---------------+-----------+-----------+
3 rows in set (0.00 sec)
-- 查看日志的具体内容
show binlog event in '{日志的名称}';
-- 删除日志, 全部执行
reset master;
-- 执行删除日志
purge binary logs to '{日志名称}';
-- 根据时间
purge binary logs before '2019-04-02 22:46:26';
-- 查看命令行的帮助
help purge binary logs;
mysql> show global variables like '%general_log%';
+------------------+------------------------------------+
| Variable_name | Value |
+------------------+------------------------------------+
| general_log | OFF |
| general_log_file | /var/lib/mysql/DESKTOP-F6VO5U4.log |
+------------------+------------------------------------+
2 rows in set (0.01 sec)
mysql> SHOW GLOBAL VARIABLES LIKE '%slow%';
+-----------------------------+-----------------------------------------+
| Variable_name | Value |
+-----------------------------+-----------------------------------------+
| log_slow_admin_statements | OFF |
| log_slow_extra | OFF |
| log_slow_replica_statements | OFF |
| log_slow_slave_statements | OFF |
| slow_launch_time | 2 |
| slow_query_log | OFF |
| slow_query_log_file | /var/lib/mysql/DESKTOP-F6VO5U4-slow.log |
+-----------------------------+-----------------------------------------+
7 rows in set (0.00 sec)
SHOW GLOBAL VARIABLES LIKE '%log%';
+------------------------------------------------+------------------------------------------------+
| Variable_name | Value |
+------------------------------------------------+------------------------------------------------+
| activate_all_roles_on_login | OFF |
| back_log | 151 |
| binlog_cache_size | 32768 |
| binlog_checksum | CRC32 |
| binlog_direct_non_transactional_updates | OFF |
| binlog_encryption | OFF |
| binlog_error_action | ABORT_SERVER |
| binlog_expire_logs_auto_purge | ON |
| binlog_expire_logs_seconds | 2592000 |
| binlog_format | ROW |
| binlog_group_commit_sync_delay | 0 |
| binlog_group_commit_sync_no_delay_count | 0 |
| binlog_gtid_simple_recovery | ON |
| binlog_max_flush_queue_time | 0 |
| binlog_order_commits | ON |
| binlog_rotate_encryption_master_key_at_startup | OFF |
| binlog_row_event_max_size | 8192 |
| binlog_row_image | FULL |
| binlog_row_metadata | MINIMAL |
| binlog_row_value_options | |
| binlog_rows_query_log_events | OFF |
| binlog_stmt_cache_size | 32768 |
| binlog_transaction_compression | OFF |
| binlog_transaction_compression_level_zstd | 3 |
| binlog_transaction_dependency_history_size | 25000 |
| binlog_transaction_dependency_tracking | COMMIT_ORDER |
| expire_logs_days | 0 |
| general_log | OFF |
| general_log_file | /var/lib/mysql/DESKTOP-F6VO5U4.log |
| innodb_api_enable_binlog | OFF |
| innodb_flush_log_at_timeout | 1 |
| innodb_flush_log_at_trx_commit | 1 |
| innodb_log_buffer_size | 16777216 |
| innodb_log_checksums | ON |
| innodb_log_compressed_pages | ON |
| innodb_log_file_size | 50331648 |
| innodb_log_files_in_group | 2 |
| innodb_log_group_home_dir | ./ |
| innodb_log_spin_cpu_abs_lwm | 80 |
| innodb_log_spin_cpu_pct_hwm | 50 |
| innodb_log_wait_for_flush_spin_hwm | 400 |
| innodb_log_write_ahead_size | 8192 |
| innodb_log_writer_threads | ON |
| innodb_max_undo_log_size | 1073741824 |
| innodb_online_alter_log_max_size | 134217728 |
| innodb_print_ddl_logs | OFF |
| innodb_redo_log_archive_dirs | |
| innodb_redo_log_capacity | 104857600 |
| innodb_redo_log_encrypt | OFF |
| innodb_undo_log_encrypt | OFF |
| innodb_undo_log_truncate | ON |
| log_bin | ON |
| log_bin_basename | /var/lib/mysql/binlog |
| log_bin_index | /var/lib/mysql/binlog.index |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
| log_error | /var/log/mysql/error.log |
| log_error_services | log_filter_internal; log_sink_internal |
| log_error_suppression_list | |
| log_error_verbosity | 2 |
| log_output | FILE |
| log_queries_not_using_indexes | OFF |
| log_raw | OFF |
| log_replica_updates | ON |
| log_slave_updates | ON |
| log_slow_admin_statements | OFF |
| log_slow_extra | OFF |
| log_slow_replica_statements | OFF |
| log_slow_slave_statements | OFF |
| log_statements_unsafe_for_binlog | ON |
| log_throttle_queries_not_using_indexes | 0 |
| log_timestamps | UTC |
| max_binlog_cache_size | 18446744073709547520 |
| max_binlog_size | 104857600 |
| max_binlog_stmt_cache_size | 18446744073709547520 |
| max_relay_log_size | 0 |
| relay_log | DESKTOP-F6VO5U4-relay-bin |
| relay_log_basename | /var/lib/mysql/DESKTOP-F6VO5U4-relay-bin |
| relay_log_index | /var/lib/mysql/DESKTOP-F6VO5U4-relay-bin.index |
| relay_log_info_file | relay-log.info |
| relay_log_info_repository | TABLE |
| relay_log_purge | ON |
| relay_log_recovery | OFF |
| relay_log_space_limit | 0 |
| slow_query_log | OFF |
| slow_query_log_file | /var/lib/mysql/DESKTOP-F6VO5U4-slow.log |
| sql_log_off | OFF |
| sync_binlog | 1 |
| sync_relay_log | 10000 |
| sync_relay_log_info | 10000 |
| terminology_use_previous | NONE |
+------------------------------------------------+------------------------------------------------+
91 rows in set (0.01 sec)
4.1 重做日志(redo log)
注意: redo log属于MySQL存储引擎InnoDB的事务日志.
作用: 确保事务的持久性, redo日志记录事务执行后的状态 用来恢复未写入data file的已成功事务更新的数据. 防止在发生故障的时间点 尚有脏页未写入磁盘 在重启MySQL服务的时候 根据redo log进行重做 从而达到事务的持久性这一特性.
内容: 记录的是物理数据页面的修改的信息, 其redo log是顺序写入redo log file的物理文件中去的.
什么时候产生: 事务开始之后就产生redo log, redo log的落盘并不是随着事务的提交才写入的, 而是在事务的执行过程中 便已经开始写入redo log文件中. 重做日志是在事务开始之后逐步写入重做日志文件, 而不一定是事务提交才写入重做日志缓存 重做日志有一个缓存区Innodb_log_buffer, Innodb_log_buffer的默认大小为8M, Innodb存储引擎先将重做日志写入innodb_log_buffef中.
InnoDB 提供了 innodb_flush_log_at_trx_commit 参数 它有三种可能取值: 参考
mysql> show variables like 'innodb_flush_log_at_trx_commit';
+--------------------------------+-------+
| Variable_name | Value |
+--------------------------------+-------+
| innodb_flush_log_at_trx_commit | 1 |
+--------------------------------+-------+
1 row in set (0.00 sec)
- 设置为 0 的时候 表示每次事务提交时都只是把
redo log留在redo log buffer中 . - 设置为 1 的时候 表示每次事务提交时都将
redo log直接持久化到磁盘. - 设置为 2 的时候 表示每次事务提交时都只是把
redo log写到page cache.
什么时候释放: 当对应事务的脏页写入到磁盘之后, redo log的使命也就完成了, 重做日志占用的空间就可以重用( 被覆盖).
对应的物理文件: 默认情况下 对应的物理文件位于数据库的data目录下的ib_logfile1&ib_logfile2.....
参数设置:
-
innodb_log_group_home_dir指定日志文件组所在的路径 默认./表示在数据库的数据目录.mysql> show variables like 'innodb_log_group_home_dir'; +---------------------------+-------+ | Variable_name | Value | +---------------------------+-------+ | innodb_log_group_home_dir | ./ | +---------------------------+-------+ 1 row in set (0.00 sec) -
innodb_log_files_in_group指定重做日志文件组中文件的数量 默认2.
关于文件的大小和数量 由以下两个参数配置:
innodb_log_file_size, 重做日志文件的大小innodb_mirrored_log_groups, 指定了日志镜像文件组的数量 默认1.
4.2 回滚日志(undo log)
作用: 保证数据的原子性 保存了事务发生之前的数据的一个版本 可以用于回滚 同时可以提供多版本并发( MVCC)控制下的读, 也即非锁定读
内容: 逻辑格式的日志 在执行undo的时候 仅仅是将数据从逻辑上恢复至事务之前的状态 而不是从物理页面上操作实现的 这一点是不同于redo log的.
什么时候产生: 事务开始之前 将当前是的版本生成undo log, undo 也会产生 redo 来保证undo log的可靠性.
什么时候释放: 当事务提交之后 undo log并不能立马被删除 而是放入待清理的链表 由purge线程判断是否由其他事务在使用undo段中表的上一个事务之前的版本信息 决定是否可以清理undo log的日志空间.
对应的物理文件: MySQL5.6之前 undo表空间位于共享表空间的回滚段中 共享表空间的默认的名称是ibdata 位于数据文件目录中. MySQL5.6之后 undo表空间可以配置成独立的文件 但是提前需要在配置文件中配置 完成数据库初始化后生效且不可改变undo log文件的个数. 如果初始化数据库之前没有进行相关配置 那么就无法配置成独立的表空间了.
关于MySQL5.7之后的独立undo 表空间配置参数如下:
innodb_undo_directory = /data/undospace/–undo独立表空间的存放目录innodb_undo_logs = 128–回滚段为128KB innodb_undo_tablespaces = 4–指定有4个undo log文件, 如果undo使用的共享表空间 这个共享表空间中又不仅仅是存储了undo的信息 共享表空间的默认为与MySQL的数据目录下面 其属性由参数innodb_data_file_path配置.
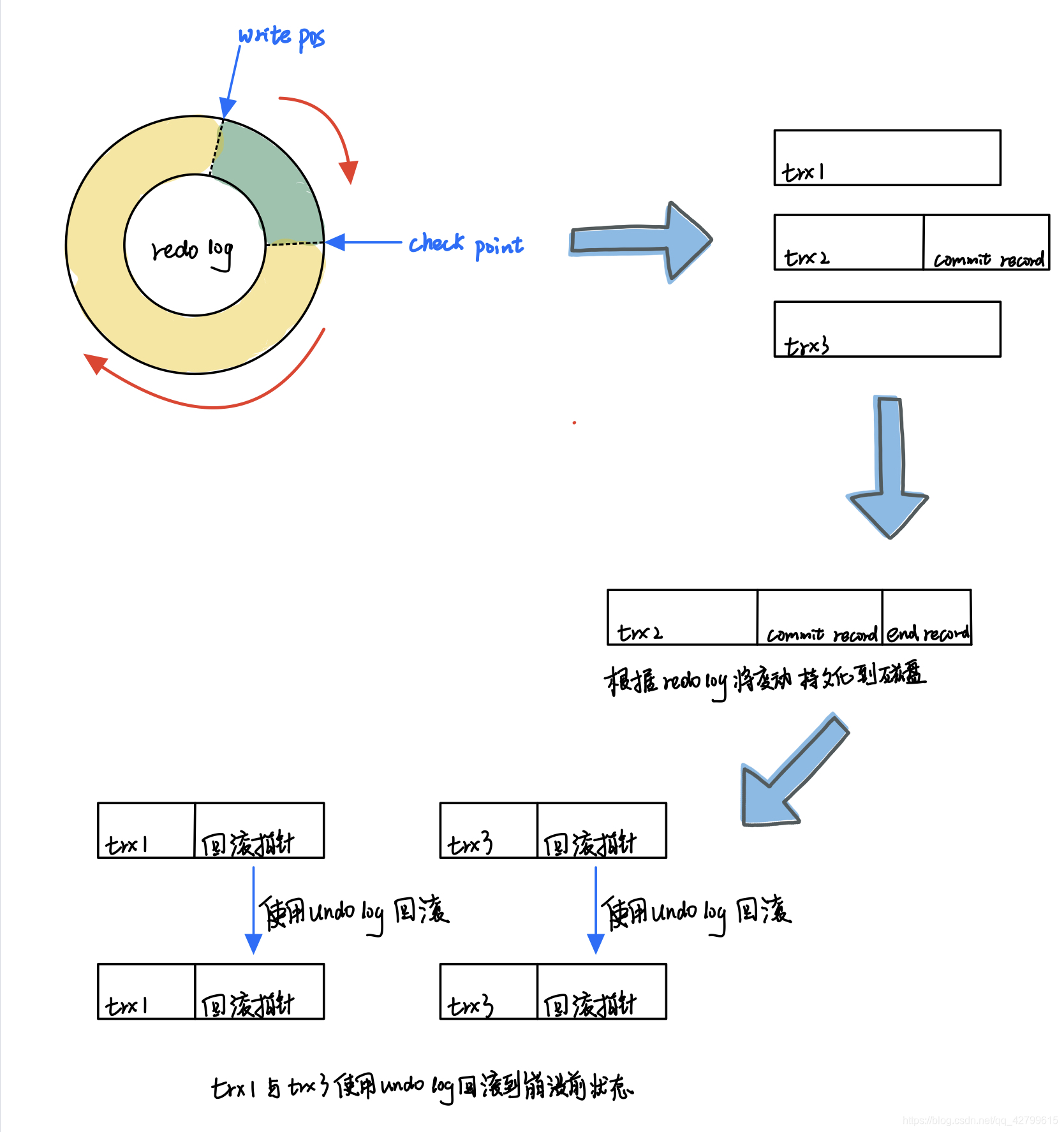
当执行事务的过程中遇到了崩溃, 一般会会经历如下几个阶段来进行恢复:
- 分析阶段(
Analysis) : 该阶段从undo log的最后一次检查点(check point可理解为在这个点之前所有应该持久化的变动都已安全落盘) 开始扫描日志 找出所有没有End Record( 当事务的日志落盘 数据也落盘 则处于End Record状态) 的事务 组成待恢复的事务集合( 一般包括Transaction Table和Dirty Page Table) . - 重做阶段(
Redo) : 该阶段依据分析阶段中, 产生的待恢复的事务集合来重演历史(Repeat History) 找出所有包含Commit Record( 事务的日志落盘, 但是数据没有落盘 则处于Commit Record状态) 的日志 将它们写入磁盘 写入完成后增加一条 End Record, 然后移除出待恢复事务集合. - 回滚阶段(
Undo) : 该阶段处理经过分析 重做阶段后剩余的恢复事务集合 此时剩下的都是需要回滚的事务( 被称为 Loser) 根据Undo Log中的信息回滚这些事务.
4.3 二进制日志(binlog)
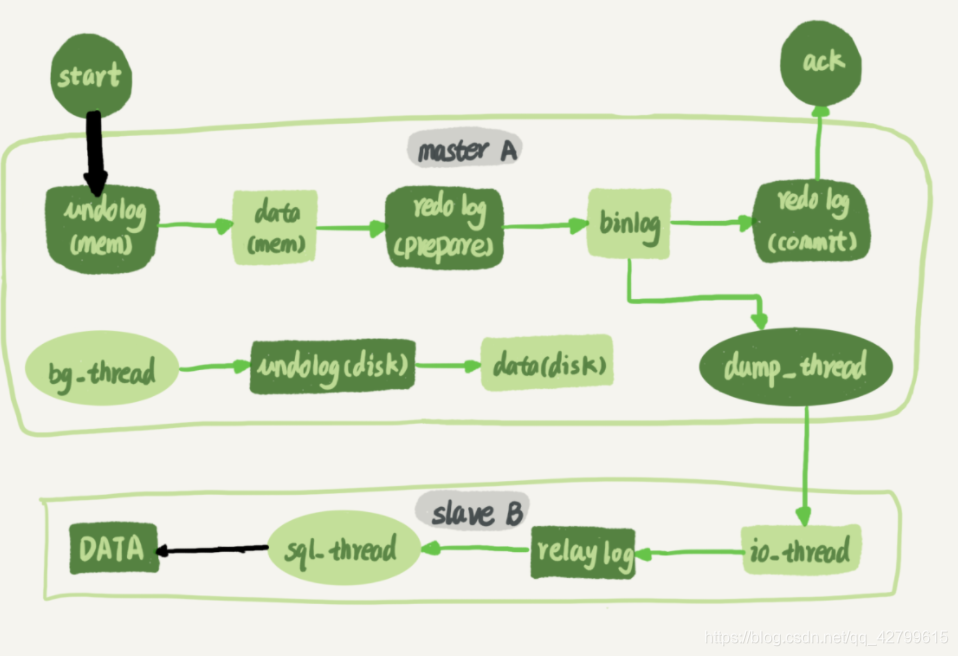
作用: 主要用于保障主从复制, 从库利用主库上的binlog进行重播, 实现主从同步, 以及数据库的基于时间点的还原.
内容: 逻辑格式的日志 可以简单认为就是执行过的事务中的sql语句. 但又不完全是sql语句这么简单 而是包括了执行的sql语句( 增删改) 反向的信息 也就意味着delete对应着delete本身和其反向的insert; update对应着update执行前后的版本的信息; insert对应着delete和insert本身的信息. 在使用mysqlbinlog解析binlog之后一些都会真相大白. 因此可以基于binlog做到类似于oracle的闪回功能 其实都是依赖于binlog中的日志记录.
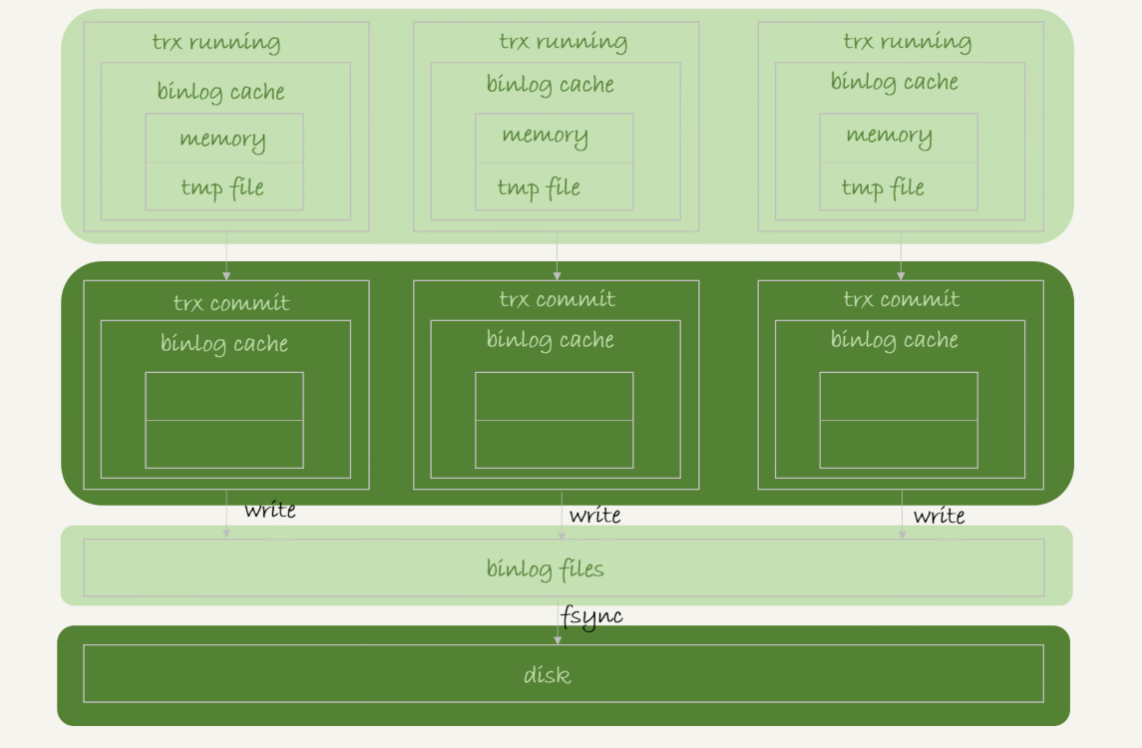
图中的 write, 指的就是指把日志写入到文件系统的 page cache, 并没有把数据持久化到磁盘, 所以速度比较快.
图中的 fsync, 才是将数据持久化到磁盘的操作. 一般情况下 我们认为 fsync 才占磁盘的 IOPS.
write 和 fsync 的时机 是由参数 sync_binlog 控制的:
mysql> show variables like 'sync_binlog';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| sync_binlog | 1 |
+---------------+-------+
1 row in set (0.00 sec)
sync_binlog=0的时候 表示每次提交事务都只write不fsync;sync_binlog=1的时候 表示每次提交事务都会执行fsync;sync_binlog=N(N>1)的时候 表示每次提交事务都write但累积N个事务后才fsync.
什么时候产生:事务提交的时候 一次性将事务中的sql语句( 一个事务可能对应多个sql语句) 按照一定的格式记录到binlog中. 这里与redo log很明显的差异就是redo log并不一定是在事务提交的时候刷新到磁盘 redo log是在事务开始之后就开始逐步写入磁盘. 因此对于事务的提交 即便是较大的事务 提交(commit)都是很快的 但是在开启了bin_log的情况下 对于较大事务的提交 可能会变得比较慢一些. 这是因为binlog是在事务提交的时候一次性写入的造成的, 这些可以通过测试验证.
什么时候释放: binlog的默认是保持时间由参数expire_logs_days配置 也就是说对于非活动的日志文件 在生成时间超过expire_logs_days配置的天数之后 会被自动删除.
4.4 错误日志(errorlog)
debug类型日志
顾名思义, 错误日志记录着mysqld启动和停止,以及服务器在运行过程中发生的错误的相关信息. 在默认情况下 系统记录错误日志的功能是关闭的, 错误信息被输出到标准错误输出.
4.5 慢查询日志(slow query log)
debug类型日志
慢日志记录执行时间过长和没有使用索引的查询语句, 报错select, update, delete以及insert语句, 慢日志只会记录执行成功的语句.
4.6 一般查询日志(general log)
debug类型日志.
记录了服务器接收到的每一个查询或是命令 无论这些查询或是命令是否正确甚至是否包含语法错误 general log 都会将其记录下来 记录的格式为{Time Id Command Argument}也正因为mysql服务器需要不断地记录日志 开启General log会产生不小的系统开销. 因此 Mysql默认是把General log关闭的.
4.7 中继日志(relay log)
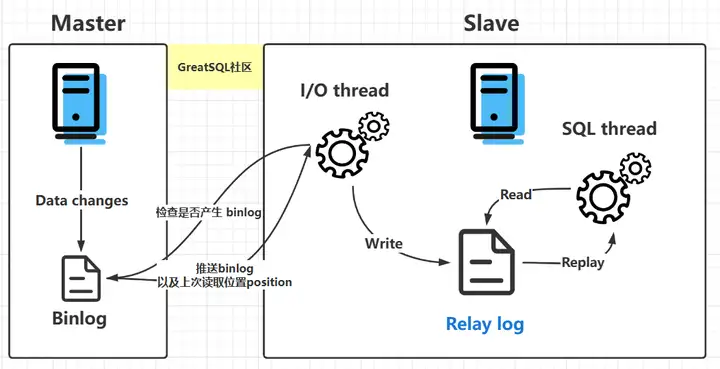
中继日志(relay log)只在主从服务器架构的从服务器上存在. 从服务器(slave)为了与主服务器(Master)保持一致, 要从主服务器读取二进制日志的内容, 并且把读取到的信息写入本地的日志文件中, 这个从服务器本地的日志文件就叫中继日志. 然后, 从服务器读取中继日志, 并根据中继日志的内容对从服务器的数据进行更新, 完成主从服务器的数据同步.
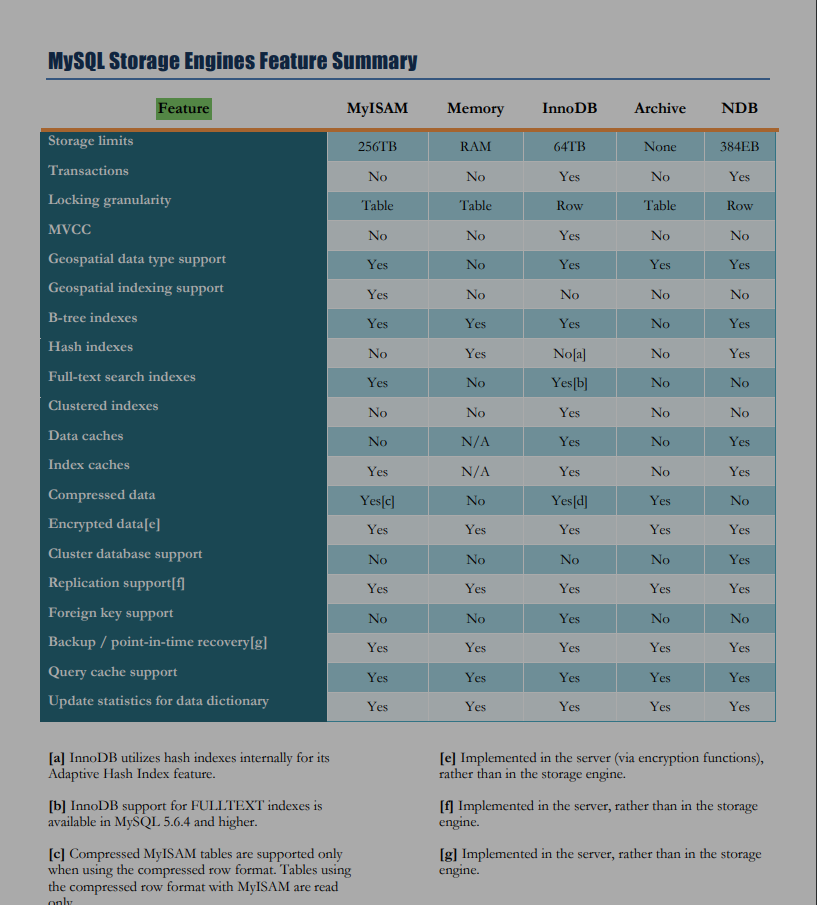
五. 引擎
引擎是一个容易被忽略的关键点, 大量关于事务, mvcc, 锁的诸般介绍文章, 大多没提及是在什么引擎之下的.
# 查看所有的引擎
show engines;
show engines \G
# 查看引擎的详情
show engine innodb status\G
mysqld --default-storage-engine=MyISAM
-- 修改表的引擎
ALTER TABLE table_name ENGINE = engine_name;
-- 创建表时, 指定引擎
create table test(
id int primary key
) engine = MyISAM;
| Engine | Support | Comment | Transactions | XA | Savepoints |
|---|---|---|---|---|---|
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |

几个主要的引擎之间的差异, 注意只有InnoDB引擎支持事务, 行级锁, 和外键.
六. 事务
select @@transaction_isolation;
-- 查看事务的隔离等级
show variables like 'transaction_isolation';
-- 查看正在运行的事务
select * from information_schema.innodb_trx;
mysql> select * from information_schema.innodb_trx;
+-----------------+-----------+---------------------+-----------------------+------------------+------------+---------------------+---------------------------------------------+---------------------+-------------------+-------------------+------------------+-----------------------+-----------------+-------------------+-------------------------+---------------------+-------------------+------------------------+----------------------------+---------------------------+---------------------------+------------------+----------------------------+---------------------+
| trx_id | trx_state | trx_started | trx_requested_lock_id | trx_wait_started | trx_weight | trx_mysql_thread_id | trx_query | trx_operation_state | trx_tables_in_use | trx_tables_locked | trx_lock_structs | trx_lock_memory_bytes | trx_rows_locked | trx_rows_modified | trx_concurrency_tickets | trx_isolation_level | trx_unique_checks | trx_foreign_key_checks | trx_last_foreign_key_error | trx_adaptive_hash_latched | trx_adaptive_hash_timeout | trx_is_read_only | trx_autocommit_non_locking | trx_schedule_weight |
+-----------------+-----------+---------------------+-----------------------+------------------+------------+---------------------+---------------------------------------------+---------------------+-------------------+-------------------+------------------+-----------------------+-----------------+-------------------+-------------------------+---------------------+-------------------+------------------------+----------------------------+---------------------------+---------------------------+------------------+----------------------------+---------------------+
| 17877 | RUNNING | 2023-01-06 16:20:13 | NULL | NULL | 5 |
51 | NULL | NULL | 0 |
1 | 2 | 1128 | 3 | 3 | 0 | READ COMMITTED | 1 | 1 | NULL |
0 | 0 | 0 | 0 | NULL |
| 283946307949064 | RUNNING | 2023-01-06 16:19:30 | NULL | NULL | 0 |
49 | select * from information_schema.innodb_trx | NULL | 0 |
0 | 0 | 1128 | 0 | 0 | 0 | READ COMMITTED | 1 | 1 | NULL |
0 | 0 | 0 | 0 | NULL |
+-----------------+-----------+---------------------+-----------------------+------------------+------------+---------------------+---------------------------------------------+---------------------+-------------------+-------------------+------------------+-----------------------+-----------------+-------------------+-------------------------+---------------------+-------------------+------------------------+----------------------------+---------------------------+---------------------------+------------------+----------------------------+---------------------+
| 字段 | 说明 |
|---|---|
trx_id |
事务id |
trx_state |
事务状态 LOCK WAIT代表发生了锁等待 |
trx_started |
事务开始时间 |
trx_requested_lock_id |
请求锁id, 事务当前正在等待锁的标识 可以join关联INNODB_LOCKS.lock_id |
trx_wait_started |
事务开始锁等待的时间 |
trx_weight |
事务的权重 |
trx_mysql_thread_id |
事务线程 ID 可以join关联PROCESSLIST.ID |
trx_query |
事务正在执行的 SQL 语句 |
trx_operation_state |
事务当前操作状态 |
trx_isolation_level |
当前事务的隔离级别 |
一般来说 事务是必须满足4个条件(
ACID) : : 原子性( Atomicity 或称不可分割性) 一致性( Consistency) 隔离性( Isolation 又称独立性) 持久性( Durability) .
- 原子性: 指处于同一个事务中的多条语句是不可分割的.
- 一致性: 事务必须使数据库从一个一致性状态变换到另外一个一致性状态. 比如转账, 转账前两个账户余额之和为2k, 转账之后也应该是2K.
- 隔离性: 指多线程环境下, 一个线程中的事务不能被其他线程中的事务打扰.
- 持久性: 事务一旦提交(
commit) 就应该被永久保存起来.
事务控制语句:
BEGIN或START TRANSACTION显式地开启一个事务;COMMIT也可以使用COMMIT WORK不过二者是等价的.COMMIT会提交事务 并使已对数据库进行的所有修改成为永久性的;ROLLBACK也可以使用ROLLBACK WORK不过二者是等价的. 回滚会结束用户的事务 并撤销正在进行的所有未提交的修改;SAVEPOINT identifierSAVEPOINT允许在事务中创建一个保存点 一个事务中可以有多个 SAVEPOINT;RELEASE SAVEPOINT identifier删除一个事务的保存点 当没有指定的保存点时 执行该语句会抛出一个异常;ROLLBACK TO identifier把事务回滚到标记点;SET TRANSACTION用来设置事务的隔离级别.InnoDB存储引擎提供事务的隔离级别有READ UNCOMMITTEDREAD COMMITTEDREPEATABLE READ和SERIALIZABLE.
MySQL 事务处理主要有两种方法:
注意: python的中的mysql_connnector默认状态是处于事务中执行的, 必须commit后才能写入数据库.
1 用BEGIN, ROLLBACK, COMMIT来实现
BEGIN, 开始一个事务ROLLBACK, 事务回滚COMMIT, 事务确认
2 直接用 SET 来改变 MySQL 的自动提交模式:
SET AUTOCOMMIT=0, 禁止自动提交,SET AUTOCOMMIT=1, 开启自动提交,
6.1 隔离等级
mysql> set autocommit = 0;
mysql> select @@transaction_isolation;
+-------------------------+
| @@transaction_isolation |
+-------------------------+
| REPEATABLE-READ |
+-------------------------+
1 row in set (0.00 sec)
# REPEATABLE-READ, MySQL 的默认级别
set global transaction isolation level read committed;
-- 修改隔离等级
| 隔离级别 | 脏读( Dirty Read) | 不可重复读( NonRepeatable Read) | 幻读( Phantom Read) |
|---|---|---|---|
| 未提交读( Read uncommitted) | 可能 | 可能 | 可能 |
| **已提交读( Read committed) ** | 不可能 | 可能 | 可能 |
| 可重复读( Repeatable read) | 不可能 | 不可能 | 可能 |
| **可串行化( Serializable ) ** | 不可能 | 不可能 | 不可能 |
从上往下, 隔离强度逐渐增强, 性能逐渐变差. 可串行化( Serializable ) , 解决了所有的问题, 但是是以单线程依次执行对应的事务的低效率换取而来.
MySQL的InnoDB引擎才支持事务, 其中可重复读是默认的隔离级别.读未提交和串行化基本上是不需要考虑的隔离级别, 前者不加锁限制, 后者相当于单线程执行, 效率太差.
读提交解决了脏读问题, 行锁解决了并发更新的问题. 并且
MySQL在可重复读级别解决了幻读问题, 是通过行锁和间隙锁的组合Next-Key锁实现的.
6.1.1 Read uncommitted
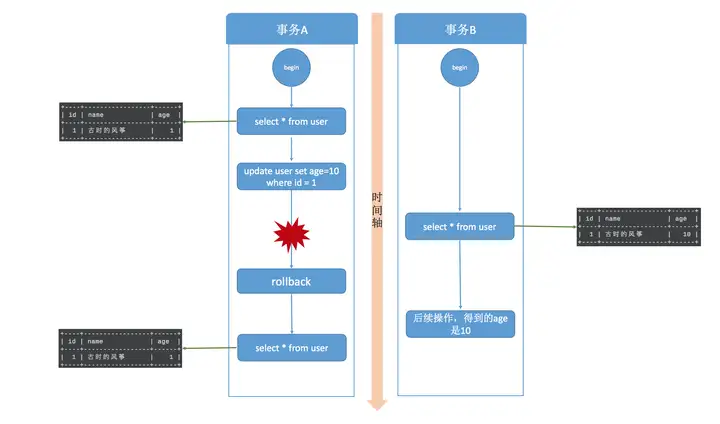
# session a
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(30) DEFAULT NULL,
`age` tinyint(4) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
insert into user values (1, 'test', 1)
# 变更事务等级
set global transaction isolation level read uncommitted;
# 登录session_b
# session_a
BEGIN;
update user set age = 10;
# session_b
select * from user;
# age = 10
# session_a
rollback;
# 这就一位着session_b这个时候拿到的数据是脏数据, a数据已经复原
脏读, 指的是读到了其他事务未提交的数据, 未提交意味着这些数据可能会回滚, 也就是可能最终不会存到数据库中, 也就是不存在的数据. 读到了并一定最终存在的数据, 这就是脏读.
6.1.2 Read committed
mysql默认的事务隔离等级.
| 顺序 | 事务A | 事务B |
|---|---|---|
| 1 | SET TRANSACTION ISOLATION LEVEL READ COMMITTED; | SET TRANSACTION ISOLATION LEVEL READ COMMITTED; |
| 2 | BEGIN; | BEGIN; |
| 3 | SELECT * FROM students WHERE id = 1; -- Alice | |
| 4 | UPDATE students SET name = 'Bob' WHERE id = 1; | |
| 5 | COMMIT; | |
| 6 | SELECT * FROM students WHERE id = 1; -- Bob | |
| 7 | COMMIT; |
在Read Committed隔离级别下 一个事务可能会遇到不可重复读( Non Repeatable Read) 的问题.
不可重复读 在一个事务内 多次读同一数据 在这个事务还没有结束时 如果另一个事务恰好修改了这个数据 那么 在第一个事务中 两次读取的数据就可能不一致.
6.1.3 Repeatable Read
| 顺序 | 事务A | 事务B |
|---|---|---|
| 1 | SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; | SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; |
| 2 | BEGIN; | BEGIN; |
| 3 | SELECT * FROM students WHERE id = 99; -- empty | |
| 4 | INSERT INTO students (id, name) VALUES (99, 'Bob'); | |
| 5 | COMMIT; | |
| 6 | SELECT * FROM students WHERE id = 99; -- empty | |
| 7 | UPDATE students SET name = 'Alice' WHERE id = 99; -- 1 row affected | |
| 8 | SELECT * FROM students WHERE id = 99; -- Alice | |
| 9 | COMMIT; |
在Repeatable Read隔离级别下 一个事务可能会遇到幻读( Phantom Read) 的问题.
幻读 在一个事务中 第一次查询某条记录 发现没有 但是 当试图更新这条不存在的记录时 竟然能成功 并且 再次读取同一条记录 它就神奇地出现了.
6.2 autocommit
# 返回当前会话的自动事务提交的状态
select @@session.autocommit;
select @@autocommit;
注意在set autocommit = 0;强制事务的情况.
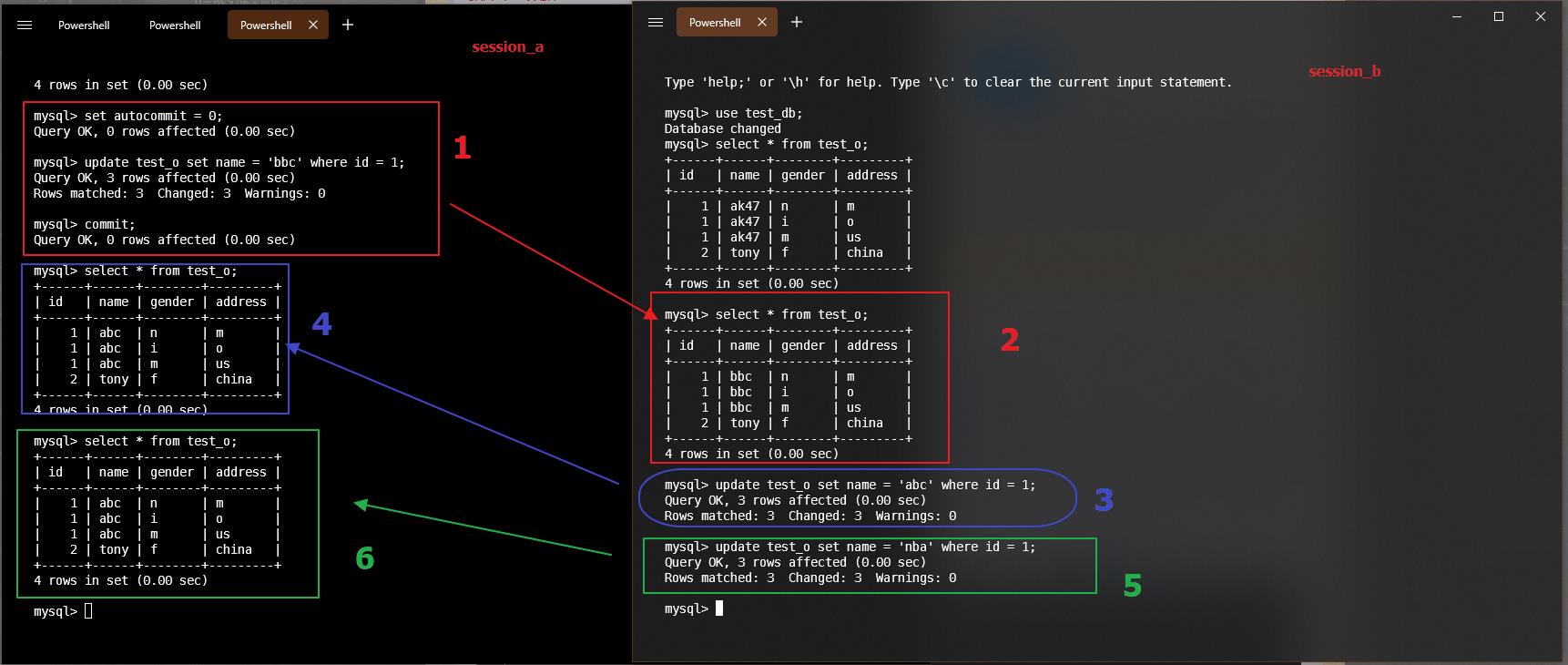
# session_a
# 将autocommit设置为0, 不主动提交事务
mysql> select * from test_o;
+------+------+--------+---------+
| id | name | gender | address |
+------+------+--------+---------+
| 1 | tes | n | m |
| 1 | test | i | o |
| 1 | test | m | us |
| 2 | tony | f | china |
+------+------+--------+---------+
4 rows in set (0.00 sec)
mysql> set autocommit = 0;
Query OK, 0 rows affected (0.00 sec)
mysql> update test_o set name = 'alex' where id = 1;
Query OK, 3 rows affected (0.00 sec)
Rows matched: 3 Changed: 3 Warnings: 0
# session_b, 进行同样的操作, 由于session_a中的操作尚未提交事务, 处于锁定的状态, session_b无法执行操作.
mysql> update test_o set name = 'jam' where id = 1;
# 等待超时
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
# 然后在session_a执行commit操作
commit;
# session_b, 重新执行此命令
mysql> update test_o set name = 'jam' where id = 1;
# session_a, session_a无法看到
mysql> select * from test_o;
+------+------+--------+---------+
| id | name | gender | address |
+------+------+--------+---------+
| 1 | alex | n | m |
| 1 | alex | i | o |
| 1 | alex | m | us |
| 2 | tony | f | china |
+------+------+--------+---------+
# 新登录进来的, session_c
mysql> select * from test_o;
+------+------+--------+---------+
| id | name | gender | address |
+------+------+--------+---------+
| 1 | jam | n | m |
| 1 | jam | i | o |
| 1 | jam | m | us |
| 2 | tony | f | china |
+------+------+--------+---------+
# session_b
mysql> select * from test_o;
+------+------+--------+---------+
| id | name | gender | address |
+------+------+--------+---------+
| 1 | jam | n | m |
| 1 | jam | i | o |
| 1 | jam | m | us |
| 2 | tony | f | china |
+------+------+--------+---------+
# 需要将set autocommit = 1;之后, session_a才能看到改变的数据
# session_a 再继续执行commit之后
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from test_o;
+------+------+--------+---------+
| id | name | gender | address |
+------+------+--------+---------+
| 1 | jam | n | m |
| 1 | jam | i | o |
| 1 | jam | m | us |
| 2 | tony | f | china |
+------+------+--------+---------+
# 继续在session_b执行update操作
# session_a依然无法直接看到变化, 需要commit之后才能看到变化
# 暂不清楚上述的执行逻辑
6.3 MVCC
The so-called
MVCCinmysqlrefers to the process of accessing the version chain while executing ordinarySELECToperations usingRCandRRtransactions with two isolation levels, which enables read/write and write-write operations of different transactions to be executed concurrently, thus improving system performance, and their biggest difference lies in the different timing of generatingReadView.
MVCC( Multi-Version Concurrent Control)即多版本并发控制协议 它的目标是在保证数据一致性的前提下 提供一种高并发的访问性能. 在MVCC协议中 每个用户在连接数据库时看到的是一个具有一致性状态的镜像 每个事务在提交到数据库之前对其他用户均是不可见的. 当事务需要更新数据时 不会直接覆盖以前的数据 而是生成一个新的版本的数据 因此一条数据会有多个版本存储 但是同一时刻只有最新的版本号是有效的. 因此 读的时候就可以保证总是以当前时刻的版本的数据可以被读到 不论这条数据后来是否被修改或删除.
MVCC 在 MySQL InnoDB 中的实现主要是为了提高数据库并发性能. 一般是在使用读已提交( READ COMMITTED) 和可重复读( Repeatable Read) 隔离级别的事务中实现.
当前读
像 select in share mode( 共享锁) select for update update insert delete( 排它锁) 这些操作都是一种当前读 当前读就是它读取的是记录的最新版本的数据. 读取时还要保证其他并发事务不能修改当前的记录 会对读取的记录进行加锁.
快照读
就像不加锁的select操作就是快照读 即不加锁的非阻塞读;
快照读的前提就是隔离级别不是串行级别 串行级别下的快照读会退化成当前读;
之所以出现快照读的情况 是基于提高并发性能的考虑 快照读的实现是基于多版本并发控制 即MVCC 可以认为MVCC是行锁的一个变种 但它在很多情况下都避免了加锁操作 降低了开销;
既然是基于多版本 即快照读可能读到的并不一定是数据的最新版本 而有可能是之前的历史版本.
6.3.1 MVCC解决的问题
数据库并发场景有三种 分别为:
- 读读(r-r): 不存在任何问题(不涉及到数据的变化) 也不需要并发控制
- 读写(r-w): 有线程安全问题 可能会造成事务隔离性问题 可能遇到脏读 幻读 不可重复读
- 写写(w-w): 有线程安全问题 可能存在更新丢失问题(如何判断到底那次写入的信息是可信的, 或者是被认为是最终的版本的?)
MVCC是一种用来解决读写冲突的无锁并发控制 也就是为事务分配单项增长的时间戳 为每个修改保存一个版本 版本与事务时间戳关联 读操作只读该事务开始前的数据库的快照 所以MVCC可以为数据库解决以下问题:
- 在并发读写数据库时 可以做到在读操作时不用阻塞写操作 写操作也不用阻塞读操作 提高了数据库并发读写的性能
- 解决脏读 幻读 不可重复读等事务隔离问题 但是不能解决更新丢失问题
多数情况下, 写入数据相对于读取数据, 其次数是相对较少的, 不能因为写入数据长期锁表导致需求量更高的读取数据出现问题, 读写冲突是优先解决的问题.
七. 锁
show open tables;
-- 查看表的锁情况
show status like 'innodb_row_lock%';
mysql> show status like 'table%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Table_locks_immediate | 5 |
| Table_locks_waited | 0 |
| Table_open_cache_hits | 823 |
| Table_open_cache_misses | 29 |
| Table_open_cache_overflows | 0 |
+----------------------------+-------+
# 1. table_locks_waited
# 出现表级锁定争用而发生等待的次数( 不能立即获取锁的次数 每等待一次值加1) 此值高说明存在着较严重的表级锁争用情况
# 2. table_locks_immediate
# 产生表级锁定次数 不是可以立即获取锁的查询次数 每立即获取锁加1
mysql> show status like 'innodb_row_lock%';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| Innodb_row_lock_current_waits | 0 |
| Innodb_row_lock_time | 0 |
| Innodb_row_lock_time_avg | 0 |
| Innodb_row_lock_time_max | 0 |
| Innodb_row_lock_waits | 0 |
+-------------------------------+-------+
# 1. innodb_row_lock_current_waits //当前正在等待锁定的数量
# 2. innodb_row_lock_time //从系统启动到现在锁定总时间长度
# 3. innodb_row_lock_time_avg //每次等待所花平均时间
# 4. innodb_row_lock_time_max //从系统启动到现在等待最长的一次所花时间
# 5. innodb_row_lock_waits //系统启动后到现在总共等待的次数

锁机制用于管理对共享资源的并发访问 是对数据库的一种保护机制 也是数据库在事务操作中保证事务数据一致性和完整性的一种机制. 当有多个用户并发的去存取数据时 在数据库中就可能会产生多个事务同时去操作一行数据的情况 如果我们不对此类并发操作不加以控制的话 就可能会读取和存储不正确的数据 最终破坏了数据的一致性.
注意不同的锁在有index和无index的差异
This section describes lock types used by
InnoDB.
- Shared and Exclusive Locks, 共享和排他锁
- Intention Locks, 意向锁
- Record Locks, 记录锁
- Gap Locks, 间隙锁
- Next-Key Locks, 临键锁
- Insert Intention Locks, 插入意向锁
- AUTO-INC Locks, 自增锁
- Predicate Locks for Spatial Indexes, 预测锁
-
对于
insert, update, delete, InnoDB会自动给涉及的数据加排他锁(X), 只有查询select需要我们手动设置排他锁. -
对于一般的
select语句InnoDB不会加任何锁 也就是可以多个并发去进行select的操作 不会有任何的锁冲突 因为根本没有锁.
7.1 行锁(record lock)
注意索引
A record lock is a lock on an index record. For example,
SELECT c1 FROM t WHERE c1 = 10 FOR UPDATE;prevents any other transaction from inserting, updating, or deleting rows where the value oft.c1is10.
mysql> select * from next;
+----+------+
| id | name |
+----+------+
| 1 | ok |
| 2 | cx |
| 3 | ciy |
| 5 | a |
| 6 | p |
| 7 | b |
+----+------+
6 rows in set (0.00 sec)
# session a
set autocommit = 0;
update next set name = 'cx' where id = 2;
# 更新id为2的项
# session b
# 更新其他行则没问题
mysql> update next set name = 'ok' where id = 1;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
# 更新相同的id的数据, 就会被阻止
mysql> update next set name = 'ok' where id = 2;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
7.2 间隙锁(gap lock)
注意索引
A gap lock is a lock on a gap between index records, or a lock on the gap before the first or after the last index record. For example,
SELECT c1 FROM t WHERE c1 BETWEEN 10 and 20 FOR UPDATE;prevents other transactions from inserting a value of15into columnt.c1, whether or not there was already any such value in the column, because the gaps between all existing values in the range are locked.
- 有索引, 扫描到的项锁上
- 无索引, 可能扫全表(即行锁升级为表锁)
select ... for update类似的, 也是间隙锁.
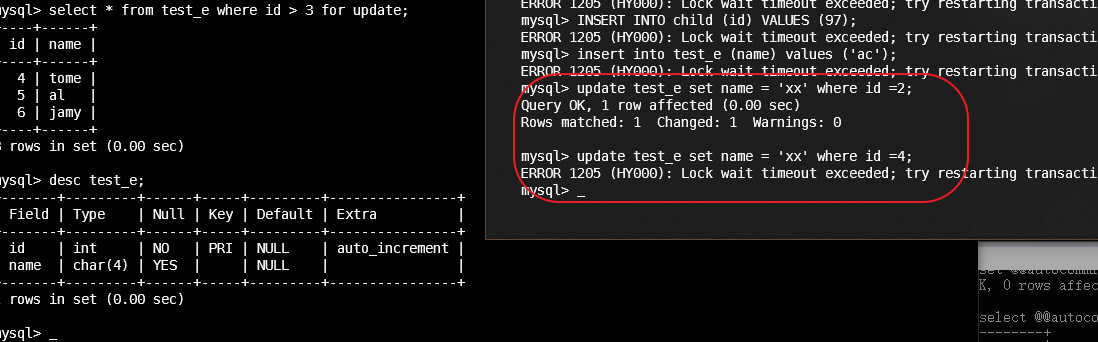
# 无索引
# session a
mysql> update next set name = 'abc' where id> 1 and id < 6;
Query OK, 2 rows affected (0.00 sec)
Rows matched: 2 Changed: 2 Warnings: 0
mysql> select * from next;
+----+------+
| id | name |
+----+------+
| 1 | ok |
| 3 | abc |
| 9 | cx |
| 5 | abc |
| 6 | p |
| 9 | b |
+----+------+
6 rows in set (0.00 sec
# id的列内容是混乱的
# session b
mysql> update next set name = 'cs' where id = 1;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> update next set name = 'cs' where id = 3;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> update next set name = 'cs' where id = 9;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
# 有索引
mysql> select * from next;
+----+------+
| id | name |
+----+------+
| 1 | ok |
| 3 | abc |
| 5 | abc |
| 6 | p |
| 7 | cx |
| 9 | b |
+----+------+
6 rows in set (0.00 sec)
mysql> update next set name = 'dc' where id> 1 and id < 6;
Query OK, 2 rows affected (0.00 sec)
Rows matched: 2 Changed: 2 Warnings: 0
# session b
# id = 1, 没有纳入
mysql> update next set name = 'cs' where id = 1;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
# 3, 在其中
mysql> update next set name = 'cs' where id = 3;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
7.3 临键锁(next-key lock)
注意索引
A next-key lock is a combination of a record lock on the index record and a gap lock on the gap before the index record.
这是行锁和间隙锁结合的变种.
7.4 自增锁(auto-inc lock)
An
AUTO-INClock is a special table-level lock taken by transactions inserting into tables withAUTO_INCREMENTcolumns. In the simplest case, if one transaction is inserting values into the table, any other transactions must wait to do their own inserts into that table, so that rows inserted by the first transaction receive consecutive primary key values.
专属于自增主键操作的锁.
mysql> show variables like 'innodb_autoinc_lock_mode';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_autoinc_lock_mode | 2 |
+--------------------------+-------+
1 row in set (0.01 sec)
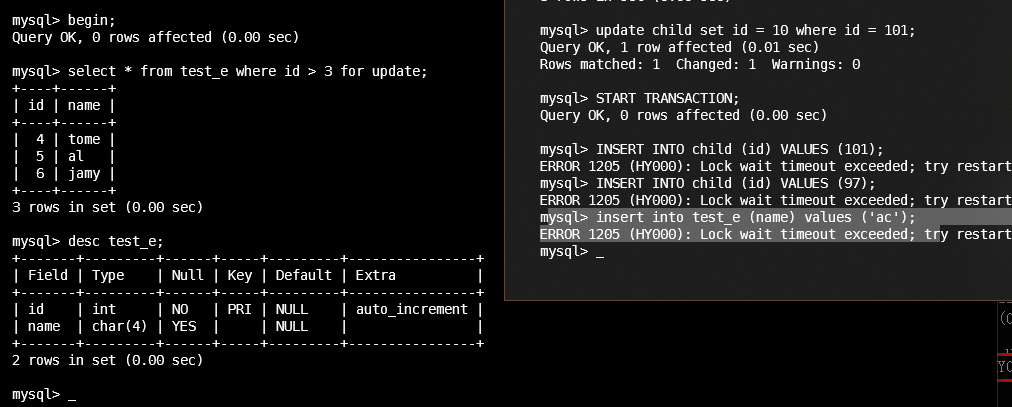
| Command-Line Format | --innodb-autoinc-lock-mode=# |
|---|---|
| System Variable | innodb_autoinc_lock_mode |
| Scope | Global |
| Dynamic | No |
SET_VAR Hint Applies |
No |
| Type | Integer |
| Default Value | 2 |
| Valid Values | 0``1``2 |
The lock mode to use for generating auto-increment values. Permissible values are 0, 1, or 2, for traditional, consecutive, or interleaved, respectively.
The default setting is 2 (interleaved) as of MySQL 8.0, and 1 (consecutive) before that. The change to interleaved lock mode as the default setting reflects the change from statement-based to row-based replication as the default replication type, which occurred in MySQL 5.7. Statement-based replication requires the consecutive auto-increment lock mode to ensure that auto-increment values are assigned in a predictable and repeatable order for a given sequence of SQL statements, whereas row-based replication is not sensitive to the execution order of SQL statements.
For the characteristics of each lock mode, see InnoDB AUTO_INCREMENT Lock Modes.
7.5 排他锁(exclusive lock)/共享锁(shared lock)
-
排他锁, 即
X. -
共享锁, 即
S.
共享锁, A加锁不影响B中的数据读取, 但是阻止B中的数据更新.

对A加共享锁, 对B加共享锁, 对C加排他锁(for update).
共享锁之间不受影响, 但是加共享锁后, 加入排他锁, 则会冲突. 注意索引的存在.
InnoDBimplements standard row-level locking where there are two types of locks, shared (S) locks and exclusive (X) locks.
- A shared (
S) lock permits the transaction that holds the lock to read a row.- 共享锁允许事务在读取行数据时执行加锁
- An exclusive (
X) lock permits the transaction that holds the lock to update or delete a row.- 排他共享
If transaction
T1holds a shared (S) lock on rowr, then requests from some distinct transactionT2for a lock on rowrare handled as follows:
- A request by
T2for anSlock can be granted immediately. As a result, bothT1andT2hold anSlock onr.- A request by
T2for anXlock cannot be granted immediately.If a transaction
T1holds an exclusive (X) lock on rowr, a request from some distinct transactionT2for a lock of either type onrcannot be granted immediately. Instead, transactionT2has to wait for transactionT1to release its lock on rowr.
记录锁 间隙锁 临键锁都是排它锁 而记录锁的使用方法跟排它锁介绍一致.
| 兼容性 | 加锁方式 | |
|---|---|---|
| S锁: 共享锁 | 加了S锁的记录 允许其他事务再加S锁 不允许其他事务再加X锁 | select…lock in share mode |
| X锁: 排他锁 | 加了X锁的记录 不允许其他事务再加S锁或者X锁 | select…for update |
7.6 意向锁
InnoDB自动执行.
- 意向共享锁, 即
IS - 意向排他锁, 即
Ix
InnoDBsupports multiple granularity locking which permits coexistence of row locks and table locks. For example, a statement such asLOCK TABLES ... WRITEtakes an exclusive lock (anXlock) on the specified table. To make locking at multiple granularity levels practical,InnoDBuses intention locks. Intention locks are table-level locks that indicate which type of lock (shared or exclusive) a transaction requires later for a row in a table. There are two types of intention locks:InnoDB支持不同锁粒度, 允许表锁和行锁实现共存.例如 lock 语句是排他锁针对特定的表. 为了实现不同锁粒度, InnoDB支持意向锁, 意向锁是表层级的锁, 用于标记事务需要对表中的一行需要什么类型的锁.
- An intention shared lock (
IS) indicates that a transaction intends to set a shared lock on individual rows in a table.- 意向共享锁, 意味着事务准备对单独行进行设置共享锁在一个表中.
- An intention exclusive lock (
IX) indicates that a transaction intends to set an exclusive lock on individual rows in a table.- 意向共享锁, 意味着事务准备对单独行进行设置排他锁在一个表中.
Table-level lock type compatibility is summarized in the following matrix.
表级别的锁之间的相关兼容情况.
注意这里指的是表级别的锁.
X |
IX |
S |
IS |
|
|---|---|---|---|---|
X |
Conflict | Conflict | Conflict | Conflict |
IX |
Conflict | Compatible | Conflict | Compatible |
S |
Conflict | Conflict | Compatible | Compatible |
IS |
Conflict | Compatible | Compatible | Compatible |
意向锁的存在是为了协调行锁和表锁的关系 支持多粒度( 表锁与行锁) 的锁并存.
- 意向共享锁( IS锁) : 事务在请求S锁前 要先获得IS锁.
- 意向排他锁( IX锁) : 事务在请求X锁前 要先获得IX锁.
例子: 事务A修改user表的记录r 会给记录r上一把行级的排他锁( X) 同时会给user表上一把意向排他锁( IX) 这时事务B要给user表上一个表级的排他锁就会被阻塞. 意向锁通过这种方式实现了行锁和表锁共存且满足事务隔离性的要求.
为什么意向锁是表级锁呢?
当我们需要加一个排他锁时 需要根据意向锁去判断表中有没有数据行被锁定(行锁).
-
如果意向锁是行锁 则需要遍历每一行数据去确认
-
如果意向锁是表锁 则只需要判断一次即可知道有没数据行被锁定 提升性能.
意向锁怎么支持表锁和行锁并存?
- 首先明确并存的概念是指数据库同时支持表 行锁 而不是任何情况都支持一个表中同时有一个事务A持有行锁 又有一个事务B持有表锁 因为表一旦被上了一个表级的写锁 肯定不能再上一个行级的锁.
- 如果事务A对某一行上锁 其他事务就不可能修改这一行. 这与" 事务B锁住整个表就能修改表中的任意一行" 形成了冲突. 所以 没有意向锁的时候 让行锁与表锁共存 就会带来很多问题. 于是有了意向锁的出现 如q1的答案中 数据库不需要在检查每一行数据是否有锁 而是直接判断一次意向锁是否存在即可 能提升很多性能.
MySQL的共享锁(S) 排他锁(X) 意向共享锁(IS) 意向排他锁(IX)的关系
7.7 插入意向锁
An insert intention lock is a type of gap lock set by
INSERToperations prior to row insertion. This lock signals the intent to insert in such a way that multiple transactions inserting into the same index gap need not wait for each other if they are not inserting at the same position within the gap. Suppose that there are index records with values of 4 and 7. Separate transactions that attempt to insert values of 5 and 6, respectively, each lock the gap between 4 and 7 with insert intention locks prior to obtaining the exclusive lock on the inserted row, but do not block each other because the rows are nonconflicting.
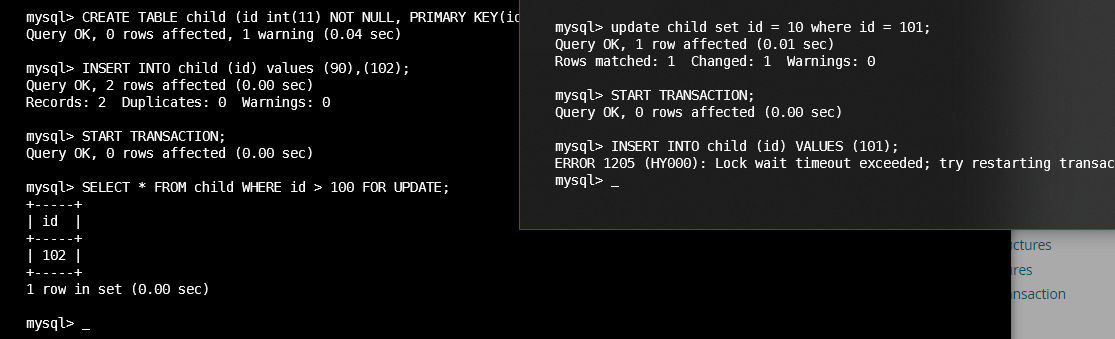
在A执行事务, 使用select .. for update锁定, B执行插入操作.
7.8 表锁
-- 主动对表进行锁定
lock tables test_o read [write];
-- 遵循, 谁加锁, 谁解锁, 其他的线程不能解锁
-- read, 阻止写入
-- write, 阻止读取
-- 会导致update等操作一直处于等待的状态
unlock tables;
7.9 乐观锁
简而言之, 就是人为通过简单的状态字段来判断数据的变化情况.
乐观锁是相对悲观锁而言的 乐观锁假设数据一般情况下不会造成冲突 所以在数据进行提交更新的时候 才会正式对数据的冲突与否进行检测 如果发现冲突了 则返回给用户错误的信息 让用户决定如何去做.
应用场景, 适用于读多写少 因为如果出现大量的写操作, 写冲突的可能性就会增大 业务层需要不断重试 会大大降低系统性能.
实现方式, 一般使用数据版本(version)记录机制实现 在数据库表中增加一个数字类型的version字段来实现. 当读取数据时 将version字段的值一同读出 数据每更新一次 对此version值加一. 当我们提交更新的时候 判断数据库表对应记录的当前版本信息与第一次取出来的version值进行比对 如果数据库表当前版本号与第一次取出来的version值相等 则予以更新 否则认为是过期数据.
7.10 悲观锁
悲观锁 正如其名 具有强烈的独占和排他特性 每次去拿数据的时候都认为别人会修改 对数据被外界( 包括本系统当前的其他事务 以及来自外部系统的事务处理) 修改持保守态度 因此 在整个数据处理过程中 将数据处于锁定状态.
应用场景, 适用于并发量不大, 写入操作比较频繁, 数据一致性比较高的场景.
在MySQL中使用悲观锁, 必须关闭MySQL的自动提交 set autocommit=0. 共享锁和排它锁是悲观锁的不同的实现, 都属于悲观锁的范畴.
八. 索引
# 查看索引
show index from table_name;
show keys from table_name;
-- 二者返回的结果是一致的
-- 不能直接看
show full columns from table_name;
# 这里返回的数据不准确
# 后期创建主键
ALTER TABLE `table_name` ADD PRIMARY KEY ( `column_name` );
# 各种写法上的差异, 效果一致
CREATE TABLE test_2(id INT NOT NULL,
c1 INT,
CONSTRAINT pk2 PRIMARY KEY(id));
# 等价? 下面的语句实际创建的也是primary key?
# 在只有unique时, 显示的primary
# 但是二者共存时, PRI 和 UNI才会区分开来
create table cbs (
id int unsigned not null primary key,
name char(4) not null,
unique index index_name (name)
);
mysql> create table cbsi (
-> id int unsigned not null,
-> name char(4) not null,
-> unique index index_name (name)
-> );
Query OK, 0 rows affected (0.01 sec)
-- 注意这里的显示问题, 并没有显示UNI, 而是显示PRI
mysql> desc cbsi;
+-------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+-------+
| id | int unsigned | NO | | NULL | |
| name | char(4) | NO | PRI | NULL | |
+-------+--------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
-- 实际上是index
mysql> show index from cbsi;
+-------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null
| Index_type | Comment | Index_comment | Visible | Expression |
+-------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| cbsi | 0 | index_name | 1 | name | A | 0 | NULL | NULL |
| BTREE | | | YES | NULL |
+-------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
alter table `table_name` add unique (`column_name`);
# 默认使用colum_name作为index_name
alter table bbc drop index id_name;
-- 注意这里的创建方式创建的键应当不是primary key
# 创建唯一索引
create unique index index_name on abc (name);
# 创建索引
CREATE INDEX indexName ON table_name (column_name);
# 创建联合索引
alter table bbc add unique key `id_name` (id, name);
create table test_table (
-- 建表时创建主键
id int unsigned not null primary key,
name char(4) not null,
address varchar(32) not null,
-- 在创建表时创建index
index index_name (name),
-- 创建多个索引
index index_addr (address)
);
create table fox (
id int unsigned not null primary key,
name char(4) not null,
address varchar(32) not null,
index index_addr (address),
unique index index_name (name)
);
create table test_k (
id int unsigned,
-- 等价
name char(4) unique,
gender char(1),
address varchar(32) not null
);
create table test_l (
id int unsigned,
-- 等价
name char(4) unique key,
gender char(1),
address varchar(32) not null
);
create table test_m (
id int unsigned,
name char(4),
gender char(1),
address varchar(32) not null,
-- 等价
unique key key_name (name)
);
create table test_n (
id int unsigned,
name char(4),
gender char(1),
address varchar(32) not null,
-- 等价
unique index key_name (name)
);
-- 不支持 column + unique index
create table test_p (
id int unsigned,
name char(4) unique index,
gender char(1),
address varchar(32) not null
);
-- key/index, 创建, 效果一样
create table dpi (
id int unsigned not null primary key,
name char(4) not null,
address varchar(32) not null,
index index_addr (address),
unique key index_name (name)
);
create table test_c (
id int unsigned not null,
name char(4) not null,
gender char(1),
address varchar(32) not null,
-- name, 这里被纳入联合主键
primary key (id, name),
index index_addr (address),
-- 这里name 被添加到唯一主键
-- 最终显示的PRI, name
unique key index_name (name),
# 同一个数据库不允许存在同名的 约束检查?
# ERROR 3822 (HY000): Duplicate check constraint name 'check_gender'.
constraint check_gender check (gender in ('男', '女'))
);
# 删除索引
alter table bbc drop index id_name;
# 删除主键
alter table abc drop primary key;
create table test_o (
id int unsigned,
name char(4),
gender char(1),
address varchar(32) not null,
# 注意这里, 联合索引
unique index id_name (id, name)
);
# 插入id_name 相同的数据
mysql> insert into test_o values (1, 'test', 'n', 'm'), (1, 'test', 'i', 'o');
ERROR 1062 (23000): Duplicate entry '1-test' for key 'test_o.id_name'
mysql> select * from test_o;
+------+------+--------+---------+
| id | name | gender | address |
+------+------+--------+---------+
| 1 | tes | n | m |
| 1 | test | i | o |
+------+------+--------+---------+
2 rows in set (0.00 sec)
# 遵循最左原则
mysql> explain select * from test_o where name = 'test';
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra
|
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | test_o | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 50.00 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from test_o where id = 2;
+----+-------------+--------+------------+------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | test_o | NULL | ref | id_name | id_name | 5 | const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
mysql> desc test_o;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | int unsigned | YES | MUL | NULL | |
| name | char(4) | YES | | NULL | |
| gender | char(1) | YES | | NULL | |
| address | varchar(32) | NO | | NULL | |
+---------+--------------+------+-----+---------+-------+
4 rows in set (0.00 sec)
mysql> show index from test_o;
+--------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+--------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| test_o | 0 | id_name | 1 | id | A | 0 | NULL | NULL | YES | BTREE | | | YES | NULL |
| test_o | 0 | id_name | 2 | name | A | 0 | NULL | NULL | YES | BTREE | | | YES | NULL |
+--------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
2 rows in set (0.00 sec)
mysql> show full columns from test_o;
+---------+--------------+--------------------+------+-----+---------+-------+---------------------------------+---------+
| Field | Type | Collation | Null | Key | Default | Extra | Privileges | Comment |
+---------+--------------+--------------------+------+-----+---------+-------+---------------------------------+---------+
| id | int unsigned | NULL | YES | MUL | NULL | | select,insert,update,references |
|
| name | char(4) | utf8mb4_0900_ai_ci | YES | | NULL | | select,insert,update,references |
|
| gender | char(1) | utf8mb4_0900_ai_ci | YES | | NULL | | select,insert,update,references |
|
| address | varchar(32) | utf8mb4_0900_ai_ci | NO | | NULL | | select,insert,update,references |
|
+---------+--------------+--------------------+------+-----+---------+-------+---------------------------------+---------+
4 rows in set (0.00 sec)
8.1 index和key
二者在不少方面是相似的. Index, 顾名思义, 起到的是索引的作用, 并不对数据进行约束; Key, 除了起到索引左右的同时还起到约束数据的作用, 如primary key, 除了作为索引, 其还约束每一行的唯一性.
primary key(主键) 和 unique keys/indexs(唯一键约束), 注意这二者的区别.
mysql> select * from next;
+----+------+
| id | name |
+----+------+
| 1 | ok |
| 2 | cx |
| 3 | ciy |
| 5 | a |
| 6 | p |
| 7 | b |
+----+------+
6 rows in set (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
# id为primary key
# 当修改数据, 导致位置错乱, 会自动调整成顺序
mysql> update next set id = 4 where id =2;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from next;
+----+------+
| id | name |
+----+------+
| 1 | ok |
| 3 | ciy |
| 4 | cx |
| 5 | a |
| 6 | p |
| 7 | b |
+----+------+
6 rows in set (0.00 sec)
主键, 每张表只允许存在1个(不是字段, 是主键); 唯一约束, 每张表可以存在多个, 二者对于数据的要求都是唯一性; index, 数据索引, 可以存在重复项, 一张表可以存在多个index.
不适合索引的字段/情况:
- 重复数据多, 如性别
- 更新频繁, 需要反复维护索引
- 表数据偏少.
8.2 约束

-
非空约束(
NOT NULL),用于确保字段不会出现空值. 例如学生信息表中, 学生的姓名, 出生日期, 性别等一定要有数据.create table test_table ( -- 主键约束 id int unsigned not null primary key, -- 非空约束 name char(4) not null ); -
唯一约束(
UNIQUE)用于确保字段中的值不会重复. 例如每个学生的身份证, 手机号等需要唯一. -
主键约束(
Primary Key)用于 唯一标识表中的每一行数据. 例如学生信息表中, 学号通常作为主键. 主键字段不能为空并且唯一 每个表可以有且只能有一个主键. -
外键约束(
Foreign Key)用于建立两个表之间的参照完整性. 例如学生属于班级, 学生信息表中的班级字段是一个外键 引用了班级表的主键. 对于外键引用 被引用的数据必须存在; 学生不可能属于一个不存在的班级.CREATE TABLE dept ( department_id INTEGER NOT NULL PRIMARY KEY , department_name CHARACTER VARYING(30) NOT NULL ); # 需要进行外键约束的主表必须先创建 CREATE TABLE emp ( employee_id INTEGER NOT NULL PRIMARY KEY , first_name CHARACTER VARYING(20) , last_name CHARACTER VARYING(25) NOT NULL , salary NUMERIC(8,2) , manager_id INTEGER , department_id INTEGER , CONSTRAINT fk_emp_dept FOREIGN KEY (department_id) REFERENCES dept(department_id) ); -
检查约束(
CHECK)可以定义更多的业务规则. 例如, 性别的取值只能为 "男" 或 "女", 用户名必须大写等;CREATE TABLE t_check( id INT PRIMARY KEY, c1 INT CHECK (c1 IS NOT NULL), c2 VARCHAR(10), c3 INT, c4 INT, -- 限制c2的内容必须是 ('START', 'CLOSE'), 不允许为空 CONSTRAINT check_c2 CHECK (c2 IN ('START', 'CLOSE')) ); # 变更检查约束 ALTER TABLE t_check ADD CONSTRAINT check_c3c4 CHECK ( c3 > c4 ); -
默认值(
DEFAULT) 用于为字段提供默认的数据. 例如, 玩家注册时的级别默认为1级.
8.3 索引的设计
三星索引, 可能是对于一个查询语句最好的索引.
三星索引, 顾名思义, 是满足了三个星级的索引.
★☆☆
定义: 如果与一个查询相关的索引行是相邻的, 或者至少相距足够靠近的话, 那这个索引就可以标记上一颗星.
收益: 它最小化了必须扫描的索引片的宽度.
实现: 把 WHERE 后的等值条件列作为索引最开头的列, 如此, 必须扫描的索引片宽度就会缩至最短.
★★☆
定义: 如果索引行的顺序与查询语句的需求一致, 则索引可以标记上第二颗星.
收益: 它排除了排序操作.
实现: 将 ORDER BY 列加入到索引中, 保持列的顺序
★★★
定义: 如果索引行中包含查询语句中的所有列, 那么这个索引就可以标记上第三颗星.
收益: 这避免了访问表的操作(避免了回表操作), 只访问索引就可以满足了.
实现: 将查询语句中剩余的列都加入到索引中.
8.4 联合索引
- 最左侧原则

联合主键使用sales_employee和fiscal_year组成主键, 当检索的是最左侧的项时使用索引, 其他的则不会使用索引.
EXPLAIN SELECT * from sales WHERE sales_employee = '2016' and fiscal_year=2015;
-- 也不会使用索引, 那怕是遵循最左侧的原则

注意: 当语句中的like不加"%"符号.
但是需要注意的是, 引擎的差异.
create table ttp (
id int unsigned not null,
name char(4) not null,
gender char(1),
primary key (id, name),
address varchar(32) not null,
index index_addr (address)
) engine=MyISAM;
create table gps (
id int unsigned not null,
name char(4) not null,
gender char(1),
primary key (id, name),
address varchar(32) not null,
index index_addr (address)
);
ttp table使用了MyISAM引擎, gps table,使用默认的InnoDB.
mysql> explain select * from ttp where name = 'alex';
+----+-------------+-------+------------+--------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | ttp | NULL | system | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
+----+-------------+-------+------------+--------+---------------+------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from gps where name = 'alex';
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | gps | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
使用MyISAM引擎的情况下, 尽管不遵循最左侧的原则, 但是并没有执行全表扫描.
8.5 自增主键
create table test_d (
id int unsigned primary key auto_increment,
name char(4) not null,
gender char(1),
address varchar(32) not null,
index index_addr (address)
);
insert into test_d (name, gender, address) values
('alex', '男', 'china'), ('tony', '男', 'us');
create table test_e (
id int unsigned primary key auto_increment,
name char(4) not null,
gender char(1),
address varchar(32) not null,
index index_addr (address)
) auto_increment = 10;
-- 设置自增从10开始
insert into test_e (name, gender, address) values
('alex', '男', 'china'), ('tony', '男', 'us');
insert into test_e (name, gender, address) values
('piel', '男', 'us');
delete from test_e where id = 12;
insert into test_e (name, gender, address) values
('piel', '男', 'us');
mysql> select * from test_e;
+----+------+--------+---------+
| id | name | gender | address |
+----+------+--------+---------+
| 10 | alex | 男 | china |
| 11 | tony | 男 | us |
| 13 | piel | 男 | us |
+----+------+--------+---------+
-- 删除原有的不连续的lid
ALTER TABLE test_e DROP COLUMN id;
-- 重建新的id列
ALTER TABLE article ADD article_id TINYINT(4) PRIMARY KEY NOT NULL AUTO_INCREMENT FIRST;
-- 不清楚这种删除重建的资源的消耗
-- 亦或者手动将自增重新设置
-- 需要在删除数据后进行
alter table test_e auto_increment = 12;
需要注意假如自增的主键同时是作为外键使用时的情形.
8.6 前缀索引
前缀索引顾名思义, 只使用作为索引的字段的部分数据作为索引, 以减少索引的资源占用.
# 创建一个存储过程, 插入测试数据
delimiter $$
CREATE PROCEDURE rand_test_data (in i_many int)
BEGIN
DECLARE ic int DEFAULT 0;
drop table if EXISTS test_table;
CREATE TABLE test_table (id int not null, col varchar(32));
set @autocommit = 0;
REPEAT
insert into test_table (id, col) VALUES (ic, LEFT ( concat(rand() * 1000000000000, 'ajkshxm' ), 18 ));
set ic = ic + 1;
UNTIL
ic = i_many
END REPEAT;
COMMIT;
set @autocommit = 1;
end $$
delimiter ;
# 插入十万条数据
call rand_test_data(100000);
# 无索引状态
mysql> select * from test_table where col = '4413703861.100324c';
Empty set (0.05 sec)
# 前缀占比长度, 独一无二的行占总行数的比例
mysql> select
count(d -> count(distinct left(col, 3)) / count(*) as c3,
-> count(distinct left(col, 4)) / count(*) as c4,
-> count(distinct left(col, 5)) / count(*) as c5,
(distin -> count(distinct left(col, 5)) / count(*) as c6,
distinct -> count(distinct left(col, 7)) / count(*) as c7,
-> count(distinct left(col, 8)) / count(*) as c8,
-> count(distinct left(col, 9)) / count(*) as c9,
-> count(distinct left(col, 10)) / count(*) as c10,
-> count(distinct left(col, 11)) / count(*) as c11,
(distin -> count(distinct left(col, 12)) / count(*) as c12
-> from test_table;
+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+
| c3 | c4 | c5 | c6 | c7 | c8 | c9 | c10 | c11 | c12 |
+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+
| 0.0090 | 0.0900 | 0.6024 | 0.6024 | 0.9929 | 0.9976 | 0.9980 | 0.9980 | 0.9980 | 0.9980 |
+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+
1 row in set (0.93 sec)
# 可以明显看到数据到了 c7, 时, 再提升长度, 比例已经趋于平缓
mysql> alter table test_table add index (col(7));
Query OK, 0 rows affected (0.67 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> desc test_table;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int | NO | | NULL | |
| col | varchar(32) | YES | MUL | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
# 在进行测试时, 时间消耗巨幅减少
mysql> select * from test_table where col = '4413703861.100324c';
Empty set (0.00 sec)
mysql> explain analyze select * from test_table where col = '4413703861.100324c';
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN
|
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Filter: (test_table.col = '4413703861.100324c') (cost=0.35 rows=1) (actual time=0.023..0.023 rows=0 loops=1)
-> Index lookup on test_table using col (col='4413703861.100324c') (cost=0.35 rows=1) (actual time=0.022..0.022 rows=0 loops=1)
|
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)
8.7 主键的选择
- 自增主键, 这是相对好的选择, 除了自增中断的弊端之外, 没有相对明显的缺点. 整数占用的资源少, 检索的速度极快.
UUID, 长度过长, 资源消耗较大.snowflake,twitter开源的分布式主键, 或者基于其基础上进行修改的衍生算法.nanoid, 一个开销较小的不重复主键.
8.8 BTREE
- 聚簇索引: 数据存储和索引放在了一块 找到索引也就找到了数据, 在
InnoDB聚簇索引的叶子节点存储行记录 因此InnoDB必须要有且只有一个聚簇索引.- 如果表定义了主键, 则
Primary Key就是聚簇索引. - 如果表没有定义主键, 则第一个非空唯一索引(
Not NULL Unique)列是聚簇索引. - 否则,
InnoDB会创建一个隐藏的row-id作为聚集索引.
- 如果表定义了主键, 则
- 非聚簇索引: 数据与索引分开储存 索引的叶子节点指向数据的对应行.
- 辅助索引:
InnoDB中在聚簇索引之上创建的索引为辅助索引存的是搜索列为key, 主键为value, 比如说找到身份证 再找到id然后根据id找到姓名.
聚簇索引的优势
物理顺序和索引顺序一致 所以找到数据的时候 把页也加载了到了buffer中.
聚簇索引的缺点
维护索引非常昂贵 特别是插入新行或者分页的时候
什么时候用聚簇索引:
-
当事务要搜索排序的时候.
-
取出一定范围数据的时候

8.9 Null值的影响
MySql难以优化引用可空列查询 它会使索引 索引统计和值更加复杂. 可空列需要更多的存储空间 还需要mysql内部进行特殊处理. 可空列被索引后 每条记录都需要一个额外的字节 还能导致MyISAM中固定大小的索引变成可变大小的索引.
- 出自< 高性能mysql第二版>
mysql> create index name_index on test_g (name);
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> explain select * from test_g where name = 'tong';
+----+-------------+--------+------------+------+---------------+------------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | test_g | NULL | ref | name_index | name_index | 17 | const | 1 | 100.00 | Using index condition |
+----+-------------+--------+------------+------+---------------+------------+---------+-------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
mysql> show index from test_g;
+--------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+--------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| test_g | 0 | PRIMARY | 1 | id | A | 2 | NULL | NULL | | BTREE | |
| YES | NULL |
| test_g | 1 | index_addr | 1 | address | A | 2 | NULL | NULL | | BTREE | |
| YES | NULL |
| test_g | 1 | name_index | 1 | name | A | 2 | NULL | NULL | YES | BTREE | |
| YES | NULL |
+--------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
3 rows in set (0.01 sec)
mysql> show full columns from test_g;
+---------+--------------+--------------------+------+-----+---------+-------+---------------------------------+---------+
| Field | Type | Collation | Null | Key | Default | Extra | Privileges | Comment |
+---------+--------------+--------------------+------+-----+---------+-------+---------------------------------+---------+
| id | int unsigned | NULL | NO | PRI | NULL | | select,insert,update,references | |
| name | char(4) | utf8mb4_0900_ai_ci | YES | MUL | NULL | | select,insert,update,references | |
| gender | char(1) | utf8mb4_0900_ai_ci | YES | | NULL | | select,insert,update,references | |
| address | varchar(32) | utf8mb4_0900_ai_ci | NO | MUL | NULL | | select,insert,update,references | |
+---------+--------------+--------------------+------+-----+---------+-------+---------------------------------+---------+
# 直接执行 is null, 索引依然没有失效
mysql> explain select * from test_g where name is null;
+----+-------------+--------+------------+------+---------------+------------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | test_g | NULL | ref | name_index | name_index | 17 | const | 1 | 100.00 | Using index condition |
+----+-------------+--------+------------+------+---------------+------------+---------+-------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
null可能导致索引的失效, 但是不是一定会导致索引失效.(注意这只是局部的测试, 使用环境还需要考虑例如不同的引擎的影响等各类因素.)
MySQL can perform the same optimization on
col_nameIS NULLthat it can use forcol_name=constant_value. For example, MySQL can use indexes and ranges to search forNULLwithIS NULL.
-
所有使用
NULL值的情况 都可以通过一个有意义的值的表示 这样有利于代码的可读性和可维护性 并能从约束上增强业务数据的规范性. -
NULL值到非NULL的更新无法做到原地更新 更容易发生索引分裂 从而影响性能. (注意: 但把NULL列改为NOT NULL带来的性能提示很小 除非确定它带来了问题 否则不要把它当成优先的优化措施 最重要的是使用的列的类型的适当性.) -
NULL值在timestamp类型下容易出问题 特别是没有启用参数explicit_defaults_for_timestamp -
NOT IN !=等负向条件查询在有NULL值的情况下返回永远为空结果 查询容易出错.
8.10 索引失效的场景
注意: 部分情形可能实际中并非如此, 在实际环境中应该多使用explain语句来检查索引的使用情况.
-
查询条件包含
or可能导致索引失效.(多条件可转为union all和间接实现) -
字段类型是字符串
where时一定用引号括起来 否则索引失效(数字/字符串, 不加与区分, 也能返回正确的结果, 但是在使用索引上有所差异). -
like通配符可能导致索引失效. -
联合索引 查询时的条件列不是联合索引中的第一个列 索引失效.
-
在索引列上使用
mysql的内置函数, 索引失效. -
对索引列
运算(如 + - * /), 索引可能失效.mysql> explain select id from next where id + 1 > 4; +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+ | 1 | SIMPLE | next | NULL | index | NULL | PRIMARY | 4 | NULL | 6 | 100.00 | Using where; Using index | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+ 1 row in set, 1 warning (0.01 sec) -
索引字段上使用( ! = 或者 < > not in) 时, 可能会导致索引失效.
-
索引字段上使用
is null,is not null可能导致索引失效. -
左连接查询或者右连接查询查询关联的字段编码格式不一样 可能导致索引失效.
-
mysql估计使用全表扫描要比使用索引快,则不使用索引.
九. explain解析
# format
# json
mysql> explain format=json select * from user_trade limit 10\G
*************************** 1. row ***************************
EXPLAIN: {
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "80.85"
},
"table": {
"table_name": "user_trade",
"access_type": "ALL",
"rows_examined_per_scan": 796,
"rows_produced_per_join": 796,
"filtered": "100.00",
"cost_info": {
"read_cost": "1.25",
"eval_cost": "79.60",
"prefix_cost": "80.85",
"data_read_per_join": "118K"
},
"used_columns": [
"user_name",
"piece",
"price",
"pay_amount",
"goods_category",
"pay_time"
]
}
}
}
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from gps where name = 'alex' and id=1;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------------+------+----------+-------+
| 1 | SIMPLE | gps | NULL | const | PRIMARY | PRIMARY | 20 | const,const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
| 列名 | 说明 |
|---|---|
| id | 执行编号 标识select所属的行. 如果在语句中没子查询或关联查询 只有唯一的select 每行都将显示1. 否则, 内层的select语句一般会顺序编号, 对应于其在原始语句中的位置. |
| select_type | 显示本行是简单或复杂select. 如果查询有任何复杂的子查询 则最外层标记为PRIMARY( DERIVED, UNION, UNION RESUlT) |
| table | 访问引用哪个表( 引用某个查询 如"gps") |
| type | 数据访问/读取操作类型( ALL index range ref eq_ref const/system NULL) |
| possible_keys | 哪一些索引可能有利于高效的查找 |
| key | 显示mysql决定采用哪个索引来优化查询 |
| key_len | 显示mysql在索引里使用的字节数 |
| ref | 显示了之前的表在key列记录的索引中查找值所用的列或常量 |
| rows | 为了找到所需的行而需要读取的行数 估算值 不精确. 通过把所有rows列值相乘 可粗略估算整个查询会检查的行数 |
| Extra | 额外信息 如using index filesort等 |
9.1 id
id是用来顺序标识整个查询中SELELCT 语句的 在嵌套查询中id越大的语句越先执行. 该值可能为NULL. 如果这一行用来说明的是其他行的联合结果.
9.2 select_type
表示查询的类型
| 类型 | 说明 |
|---|---|
simple |
简单子查询 不包含子查询和union |
primary |
包含union或者子查询 最外层的部分标记为primary |
subquery |
一般子查询中的子查询被标记为subquery 也就是位于select列表中的查询 |
derived |
派生表, 该临时表是从子查询派生出来的 位于form中的子查询 |
union |
位于union中第二个及其以后的子查询被标记为union 第一个就被标记为primary如果是union位于from中则标记为derived |
union result |
用来从匿名临时表里检索结果的select被标记为union result |
dependent union |
顾名思义 首先需要满足UNION的条件 及UNION中第二个以及后面的SELECT语句 同时该语句依赖外部的查询 |
subquery |
子查询中第一个SELECT语句 |
dependent subquery |
和DEPENDENT UNION相对UNION一样 |
9.3 table
对应行正在访问哪一个表 表名或者别名
- 关联优化器会为查询选择关联顺序 左侧深度优先
- 当
from中有子查询的时候 表名是derivedN的形式N指向子查询 也就是explain结果中的下一列 - 当有
union result的时候 表名是union 1,2等的形式 1,2表示参与union的query id
注意: MySQL对待这些表和普通表一样 但是这些 "临时表" 是没有任何索引的.
9.4 type
type显示的是访问类型 是较为重要的一个指标 结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL , 一般来说 得保证查询至少达到range级别 最好能达到ref.
| 类型 | 说明 |
|---|---|
| All | 最坏的情况,全表扫描 |
| index | 和全表扫描一样. 只是扫描表的时候按照索引次序进行而不是行. 主要优点就是避免了排序, 但是开销仍然非常大. 如在Extra列看到Using index 说明正在使用覆盖索引 只扫描索引的数据 它比按索引次序全表扫描的开销要小很多 |
| range | 范围扫描 一个有限制的索引扫描. key 列显示使用了哪个索引. 当使用= <> > >= < <= IS NULL <=> BETWEEN 或者 IN 操作符,用常量比较关键字列时,可以使用 range |
| ref | 一种索引访问 它返回所有匹配某个单个值的行. 此类索引访问只有当使用非唯一性索引或唯一性索引非唯一性前缀时才会发生. 这个类型跟eq_ref不同的是 它用在关联操作只使用了索引的最左前缀 或者索引不是UNIQUE和PRIMARY KEY. ref可以用于使用=或<=>操作符的带索引的列. |
| eq_ref | 最多只返回一条符合条件的记录. 使用唯一性索引或主键查找时会发生 ( 高效) |
| const | 当确定最多只会有一行匹配的时候 MySQL优化器会在查询前读取它而且只读取一次 因此非常快. 当主键放入where子句时 mysql把这个查询转为一个常量( 高效) |
| system | 这是const连接类型的一种特例 表仅有一行满足条件. |
| Null | 意味说mysql能在优化阶段分解查询语句 在执行阶段甚至用不到访问表或索引( 高效) |
9.5 possible_keys
显示查询使用了哪些索引 表示该索引可以进行高效地查找 但是列出来的索引对于后续优化过程可能是没有用的
9.6 key
key列显示MySQL实际决定使用的键( 索引) . 如果没有选择索引 键是NULL. 要想强制MySQL使用或忽视possible_keys列中的索引 在查询中使用FORCE INDEX USE INDEX或者IGNORE INDEX.
9.7 key_len
key_len列显示MySQL决定使用的键长度. 如果键是NULL 则长度为NULL. 使用的索引的长度. 在不损失精确性的情况下 长度越短越好 .
9.8 ref
ref列显示使用哪个列或常数与key一起从表中选择行.
9.9 rows
rows列显示MySQL认为它执行查询时必须检查的行数. 注意这是一个预估值.
9.10 Extra
Extra是EXPLAIN输出中另外一个很重要的列 该列显示MySQL在查询过程中的一些详细信息 MySQL查询优化器执行查询的过程中对查询计划的重要补充信息.
| 类型 | 说明 |
|---|---|
| Using filesort | MySQL有两种方式可以生成有序的结果 通过排序操作或者使用索引 当Extra中出现了Using filesort 说明MySQL使用了后者 但注意虽然叫filesort但并不是说明就是用了文件来进行排序 只要可能排序都是在内存里完成的. 大部分情况下利用索引排序更快 所以一般这时也要考虑优化查询了. 使用文件完成排序操作 这是可能是ordery by group by语句的结果 这可能是一个CPU密集型的过程 可以通过选择合适的索引来改进性能 用索引来为查询结果排序. |
| Using temporary | 用临时表保存中间结果 常用于GROUP BY 和 ORDER BY操作中 一般看到它说明查询需要优化了 就算避免不了临时表的使用也要尽量避免硬盘临时表的使用. |
| Not exists | MYSQL优化了LEFT JOIN 一旦它找到了匹配LEFT JOIN标准的行 就不再搜索了. |
| Using index | 说明查询是覆盖了索引的 不需要读取数据文件 从索引树( 索引文件) 中即可获得信息. 如果同时出现using where 表明索引被用来执行索引键值的查找 没有using where 表明索引用来读取数据而非执行查找动作. 这是MySQL服务层完成的 但无需再回表查询记录. |
| Using index condition | 这是MySQL 5.6出来的新特性 叫做" 索引条件推送" . 简单说一点就是MySQL原来在索引上是不能执行如like这样的操作的 但是现在可以了 这样减少了不必要的IO操作 但是只能用在二级索引上. |
| Using where | 使用了WHERE从句来限制哪些行将与下一张表匹配或者是返回给用户. 注意: Extra列出现Using where表示MySQL服务器将存储引擎返回服务层以后再应用WHERE条件过滤. |
| Using join buffer | 使用了连接缓存: Block Nested Loop 连接算法是块嵌套循环连接;Batched Key Access 连接算法是批量索引连接 |
| impossible where | where子句的值总是false 不能用来获取任何元组 |
| select tables optimized away | 在没有GROUP BY子句的情况下 基于索引优化MIN/MAX操作 或者对于MyISAM存储引擎优化COUNT(*)操作 不必等到执行阶段再进行计算 查询执行计划生成的阶段即完成优化. |
| distinct | 优化distinct操作 在找到第一匹配的元组后即停止找同样值的动作 |
9.11 1 查看性能
# profile
# 开启检测
SET SESSION profiling = 1;
# do something
select * from test;
# 查看执行的速度
mysql> SHOW PROFILES;
+----------+------------+-----------------------------------------------------------------------------------------------------+
| Query_ID | Duration | Query
|
+----------+------------+-----------------------------------------------------------------------------------------------------+
| 1 | 0.00107400 | SELECT DATABASE()
|
| 2 | 0.00329250 | show databases
|
| 3 | 0.00131350 | show tables
|
| 4 | 0.00120475 | show tables
|
| 5 | 0.00488875 | select count(*) from tb_emp_bigdata
|
| 6 | 0.00027975 | select * from tb_emp_bigdata limit 20
|
| 7 | 0.03996850 | select *from tb_emp_bigdata A where A.deptno in (select B.deptno from tb_dept_bigdata B)
|
| 8 | 0.04442800 | select *from tb_emp_bigdata A where exists(select 1 from tb_dept_bigdata B where B.deptno=A.deptno) |
+----------+------------+-----------------------------------------------------------------------------------------------------+
# --- 单条语句可以使用
mysql> explain analyze select * from test_table where exists (select 1 from test_a where test_a.col = test_table.col);
| EXPLAIN
| -> Inner hash join (test_table.col = `<subquery2>`.col) (cost=5008925664.64 rows=5008894001) (actual time=952.272..952.272 rows=0 loops=1)
-> Table scan on test_table (cost=30976.71 rows=997152) (actual time=0.018..395.888 rows=1000000 loops=1)
-> Hash
-> Table scan on <subquery2> (cost=10102.66..10733.05 rows=50232) (actual time=39.797..43.171 rows=49865 loops=1)
-> Materialize with deduplication (cost=10102.65..10102.65 rows=50232) (actual time=39.796..39.796 rows=49865 loops=1)
-> Filter: (test_a.col is not null) (cost=5079.45 rows=50232) (actual time=0.019..24.711 rows=50000 loops=1)
-> Table scan on test_a (cost=5079.45 rows=50232) (actual time=0.018..22.378 rows=50000 loops=1)
1 row in set, 1 warning (0.96 sec)
mysql> show warnings;
+-------+------+------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+------------------------------------------------------------------------------------+
| Note | 1276 | Field or reference 'test_db.test_table.col' of SELECT #2 was resolved in SELECT #1 |
+-------+------+------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
这种方法已经被废弃, 等待删除. 将使用Performance Schema替代这个功能.
十. 基本使用
-
DDL, data definition language, 数据定义语言
主要用于维护存储数据的结构, 这种结构包括数据库, 表, 视图, 索引, 聚簇等.
常用命令:
create创建数据库和数据库的一些对象drop删除数据库/表, 索引, 条件约束以及数据表的权限等alter修改数据库表的定义及数据属性
-
DML, data management language, 数据管理语言
主要用于对数据库对象中包含的数据进行操作
常用命令:
insert向数据库中插入一条数据delete删除表中的一条或者多条记录updata修改表中的数据
-
DQL, data query language, 数查询语言
主要用于查询数据库当中的数据
常用命令
selete查询表中的数据from查询哪张表 视图where约束条件
-
DCL, data control language, 数据库控制语言
主要控制数据库对象的用户管理, 权限管理 事务和实时监视.
常用命令:
grant分配权限给用户revoke撤回数据库中某用户的权限rollback回滚commit事务提交
注意: commit
在数据库的插入 删除和修改操作时 只有当事务在提交到数据库时才算完成. 在事务提交前 只有操作数据库的这个人才能有权看到所做的事情 别人只有在最后提交完成后才可以看到. 提交数据有三种类型: 显式提交 隐式提交及自动提交.
-
显式提交
用commit命令直接完成的提交为显式提交.commit; -
隐式提交
用SQL命令间接完成的提交为隐式提交, 这些命令有:alterauditcommentconnectcreatedisconnectdropexitgrantnoauditquitrevokerename.# session a set autocommit = 0; # 删除掉主键 alter table next drop primary key; # session b mysql> desc next; +-------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+--------------+------+-----+---------+-------+ | id | int unsigned | NO | | NULL | | | name | char(4) | NO | | NULL | | +-------+--------------+------+-----+---------+-------+ 2 rows in set (0.00 sec) -
自动提交
若把autocommit设置为on(1)则在插入 修改 删除语句执行后 系统将自动进行提交.set autocommit on;
10.1 增
-
数据库
-- 创建数据库, 一般情况下默认database的创建参数即可, 如字符集, 引擎等. CREATE DATABASE [IF NOT EXISTS] database_name; create database db_name; -
表
-- 创建表 create table tb_name (column_name column_type); create table [IF NOT EXISTS] tb_name (column_name column_type); # 复制表的结构方式进行创建表 mysql> desc next; +-------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+--------------+------+-----+---------+-------+ | id | int unsigned | NO | PRI | NULL | | | name | char(4) | NO | | NULL | | +-------+--------------+------+-----+---------+-------+ 2 rows in set (0.00 sec) mysql> create table copy_t as select * from next where 1 <> 1; Query OK, 0 rows affected (0.11 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc copy_t; +-------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+--------------+------+-----+---------+-------+ | id | int unsigned | NO | | NULL | | | name | char(4) | NO | | NULL | | +-------+--------------+------+-----+---------+-------+ 2 rows in set (0.00 sec) -
字段
alter table test_s add address varchar(10) not null; # 等价 alter table test_s add column gender char(1) not null; # 将心增加的列添加到第一列 alter table test_s add country char(10) not null first; # 将新增的列添加到id列之后 alter table test_s add school char(10) not null after id; -
行
INSERT INTO table_name ( field1, field2,...fieldN ) VALUES ( value1, value2,...valueN ); # 当插入的内容和字段完全对应时, 可以省略字段名称 INSERT INTO table_name VALUES ( value1, value2,...valueN ); # 插入时忽视错误 INSERT IGNORE INTO table_name ( field1, field2,...fieldN ) VALUES ( value1, value2,...valueN ); # 查看错误 show warnings; mysql> insert ignore into test_s values (1, 't'); Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> show warnings; +---------+------+----------------------------------------------+ | Level | Code | Message | +---------+------+----------------------------------------------+ | Warning | 1062 | Duplicate entry '1' for key 'test_s.PRIMARY' | +---------+------+----------------------------------------------+ 1 row in set (0.00 sec) # 插入多条数据 INSERT INTO employee(emp_id, emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email) VALUES ( 27, '李四', '女', 5, 18, current_date, 10, 6000, NULL, 'lisi@shuguo.com'), ( 28, '王五', '男', 5, 18, current_date, 10, 6500, NULL, 'wangwu@shuguo.com'), ( 29, '赵六', '女', 5, 18, current_date, 10, 6700, NULL, 'zhaoliu@shuguo.com'); # 使用replace into 也能插入数据 replace into test_s (id,name) values(5,'aa'),(6,'bb');
10.2 删
-
数据库
drop database db_name; -
表
drop table table_name; -
字段
alter table drop col_name; -
行
DELETE FROM table_name [WHERE Clause] -- delete, 大批量的数据删除, 会导致缓存表占用超出缓存大小. -- truncate, 将整个表的数据清空, 实际上是复制表结构, 将原来的整个表删掉.
10.3 改
-
数据库
-- 不支持直接修改名称之类的操作 -- 将数据导出来 -- 将数据添加到新的数据库 -- 操作见数据备份 -
表
-- 重命名表名称 RENAME TABLE old_table_name TO new_table_name; -
字段
-- change, 改名称, 改数据类型 -- modify, 改数据类型 # 修改字段的数据类型 alter table test_s modify gender char(2); # 修改字段的名称和数据类型 alter table test_s change country nation varchar(5); -
行
-- update -- on duplicate key update -- replace UPDATE table_name SET field1=new-value1, field2=new-value2 [WHERE Clause] -- REPLACE(string, from_string, new_string) -- 修改name字段的所有内容, 将'te' 全部改成 'ab' UPDATE test_s SET name=replace(name, 'te', 'ab'); # 没有数据, 则插入数据, 有, 则变更 replace into test_s (id,name) values(5,'cc'),(6,'ee'); mysql> select * from test_s; +----+------+ | id | name | +----+------+ | 1 | alex | | 1 | abst | | 2 | tony | | 3 | abs | | 5 | aa | | 6 | bb | +----+------+ 6 rows in set (0.00 sec) # mysql> replace into test_s (id,name) values(5,'cc'),(6,'ee'); Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> select * from test_s; +----+------+ | id | name | +----+------+ | 1 | alex | | 1 | abst | | 2 | tony | | 3 | abs | | 5 | aa | | 6 | bb | | 5 | cc | | 6 | ee | +----+------+ 8 rows in set (0.00 sec mysql> desc test_s; +-------+---------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+---------+------+-----+---------+----------------+ | id | int | NO | PRI | NULL | auto_increment | | name | char(4) | YES | | NULL | | +-------+---------+------+-----+---------+----------------+ mysql> select * from test_s; +----+------+ | id | name | +----+------+ | 1 | alex | | 2 | abst | | 3 | to | | 4 | abs | | 5 | aa | | 6 | bb | | 7 | cc | | 8 | ee | +----+------+ # 注意这里的插入, name, char(4), 但是没办法插入数据, 尽管后面的if语句返回的数据长度为4 mysql> INSERT INTO test_s (id, name) -> VALUES (3, 'jupyter') -> ON DUPLICATE KEY UPDATE name = if(length(values(name)) > 4, substring(values(name), 1, 4), values(name)); ERROR 1406 (22001): Data too long for column 'name' at row 1 # 将name的长度改为7, 则可以修改 # -> 推测修改, 是先进行values的数据的校检, 才会执行后续, 由于jupyter的长度大于4, 则先执行报错, 而不是先执行if语句的数据返回再进行校检. # 索引没有使用? mysql> explain INSERT INTO test_s (id, name) -> VALUES (3, 'jupyter') -> ON DUPLICATE KEY UPDATE name = if(length(values(name)) > 4, substring(values(name), 1, 4), values(name)); +----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------+ | 1 | INSERT | test_s | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
十一. 关键字
11.1 change/modify
- modify, 只能修改字段的数据类型
- change, 既能改数据类型, 也能改字段的名称.
# 修改字段的数据类型
alter table test_s modify gender char(2);
# 修改字段的名称和数据类型
alter table test_s change country nation varchar(5);
11.2 between
mysql> select * from next where id between 1 and 3;
+----+------+
| id | name |
+----+------+
| 1 | alex |
| 3 | ciy |
| 2 | tom |
+----+------+
# where column_name between a and b, include a and b(包括两个条件端点)
# 索引的使用
mysql> explain select id from next where id between 3 and 7;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra
|
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | next | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 4 | 100.00 | Using
where; Using index |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select id from next where id > 3 and id < 7;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra
|
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | next | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 2 | 100.00 | Using
where; Using index |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
11.3 in/exists
当列表中的值都是常量时
MySQL执行以下步骤:
- 首先 评估基于所述值类型的的
column_1所述的或expr表达的结果 .- 其次 对值进行排序.
- 第三 使用二进制搜索算法搜索值. 因此 使用
IN运算符查询执行带有常量列表的速度非常快.
exists用于对外表记录做筛选. exists会遍历外表 将外查询表的每一行 代入内查询进行判断. 当exists里的条件语句能够返回记录行时 条件就为真 返回外表当前记录. 反之如果exists里的条件语句不能返回记录行 条件为假 则外表当前记录被丢弃.
select a.* from A a where exists(select 1 from B b where a.id=b.id)
in是先把后边的语句查出来放到临时表中, 然后遍历临时表 将临时表的每一行, 代入外查询去查找.
select * from Awhere id in(select id from B);
子查询的表比较大的时候 使用exists可以有效减少总的循环次数来提升速度; 当外查询的表比较大的时候 使用in可以有效减少对外查询表循环遍历来提升速度.
mysql> select * from next where name in ('alex', 'ciy');
+----+------+
| id | name |
+----+------+
| 1 | alex |
| 3 | ciy |
+----+------+
2 rows in set (0.01 sec)
# 反之, NOT IN
# 索引的使用
mysql> explain select id from next where id in (1, 7);
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra
|
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | next | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 2 | 100.00 | Using
where; Using index |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
注意当 in (condition/条件) 中存在 null 值时出现的异常现象
create table t4(c1 int,c2 int);
create table t5 (c1 int,c2 int);
insert into t4 values(1,2);
insert into t4 values(1,3);
insert into t5 values(1,2);
insert into t5 values(1,null);
# 当null存在
select * from t4 where c2 not in(select c2 from t5);
# empty set
mysql> select * from t5;
+------+------+
| c1 | c2 |
+------+------+
| 1 | 2 |
| 1 | NULL |
+------+------+
2 rows in set (0.00 sec)
# 将这里的 null 去掉
mysql> update t5 set c2 = 4 where c2 is null;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from t5;
+------+------+
| c1 | c2 |
+------+------+
| 1 | 2 |
| 1 | 4 |
+------+------+
2 rows in set (0.00 sec)
mysql> select * from t4 where t4.c2 not in(select t5.c2 from t5);
+------+------+
| c1 | c2 |
+------+------+
| 1 | 3 |
+------+------+
1 row in set (0.00 sec)
# ----------------------------------------------------------------------------------
select * from t4 where not exists(select 1 from t5 where t5.c2=t4.c2);
+------+------+
| c1 | c2 |
+------+------+
| 1 | 3 |
+------+------+
1 row in set (0.00 sec)
# -------------------------------------
select * from employees where hire_date in (select distinct hire_date from employees order by hire_date limit 3, 1);
ERROR 1235 (42000): This version of MySQL doesn't yet support 'LIMIT & IN/ALL/ANY/SOME subquery'
11.4 and/or
mysql> explain select * from next where id = 7 or (id = 3 and id = 5);
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | next | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
11.5 having/where
having解决where无法和聚合函数一exit起使用的问题.
mysql> select count(*) as c from sales group by sales_employee;
+---+
| c |
+---+
| 3 |
| 3 |
| 3 |
+---+
3 rows in set (0.00 sec)
mysql> select count(*) as c from sales group by sales_employee having c > 1;
+---+
| c |
+---+
| 3 |
| 3 |
| 3 |
+---+
3 rows in set (0.00 sec)
mysql> select count(*) as c from sales group by sales_employee where c > 1;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use
near 'where c > 1' at line 1
11.6 group by/rollup
rollup, 相当于增加一个小计和合计的扩展.
mysql> SELECT year, country, product, SUM(profit) AS profit
-> FROM sales_a
-> GROUP BY year, country, product;
+------+---------+------------+--------+
| year | country | product | profit |
+------+---------+------------+--------+
| 2000 | Finland | Computer | 1500 |
| 2000 | India | Calculator | 150 |
| 2000 | India | Computer | 1200 |
| 2000 | Finland | Phone | 100 |
| 2001 | USA | Calculator | 50 |
| 2001 | USA | Computer | 2700 |
| 2001 | USA | TV | 250 |
| 2000 | USA | Calculator | 75 |
| 2000 | USA | Computer | 1500 |
| 2001 | Finland | Phone | 10 |
+------+---------+------------+--------+
10 rows in set (0.00 sec)
# rollup 进一步扩展和合并的数据类型
mysql> SELECT year, country, product, SUM(profit) AS profit
-> FROM sales_A
-> GROUP BY year, country, product WITH ROLLUP;
ERROR 1146 (42S02): Table 'test_db.sales_A' doesn't exist
mysql> SELECT year, country, product, SUM(profit) AS profit
-> FROM sales_a
-> GROUP BY year, country, product WITH ROLLUP;
+------+---------+------------+--------+
| year | country | product | profit |
+------+---------+------------+--------+
| 2000 | Finland | Computer | 1500 |
| 2000 | Finland | Phone | 100 |
| 2000 | Finland | NULL | 1600 |
| 2000 | India | Calculator | 150 |
| 2000 | India | Computer | 1200 |
| 2000 | India | NULL | 1350 |
| 2000 | USA | Calculator | 75 |
| 2000 | USA | Computer | 1500 |
| 2000 | USA | NULL | 1575 |
| 2000 | NULL | NULL | 4525 |
| 2001 | Finland | Phone | 10 |
| 2001 | Finland | NULL | 10 |
| 2001 | USA | Calculator | 50 |
| 2001 | USA | Computer | 2700 |
| 2001 | USA | TV | 250 |
| 2001 | USA | NULL | 3000 |
| 2001 | NULL | NULL | 3010 |
| NULL | NULL | NULL | 7535 |
+------+---------+------------+--------+
18 rows in set (0.00 sec)
| 2000 | Finland | NULL | 1600
# 芬兰 2000 年的总和
| 2000 | NULL | NULL | 4525 |
# 所有项的 2000 年的总和
| NULL | NULL | NULL | 7535 |
# 全部的总和
11.7 delete/truncate
删除表格内容, 注意这里的删除在InnoDB下, 实际上并不执行真真意义上的删除操作, 而是采用标记的方式, 标记要删除的位置, 当有新的数据插入到相应的位置时, 直接使用标记的位置, 复用, 减少对表格结构的影响.
-- 删除表格的全部数据
-- 假如表特别大, 会导致超出临时表大小错误
delete from table [where ...];
要想回收这部分被标记删除的表空间可以使用:
ALTER TABLE table_name ENGINE=INNODB;
# 或者是
OPTIMIZE TABLE table_name;
二者的区别, 简单理解, 在于, ALTER是recreate, 而optimize是recreate + analyze.
OPTIMIZE TABLEworks forInnoDB,MyISAM, andARCHIVEtables.OPTIMIZE TABLEis also supported for dynamic columns of in-memoryNDBtables. It does not work for fixed-width columns of in-memory tables, nor does it work for Disk Data tables. The performance ofOPTIMIZEon NDB Cluster tables can be tuned using--ndb-optimization-delay, which controls the length of time to wait between processing batches of rows byOPTIMIZE TABLE. For more information, see Previous NDB Cluster Issues Resolved in NDB Cluster 8.0.针对的引擎
实际上并不是逐行删除数据, 而是直接删除表格, 然后重建新的表格, 不支持事务(应该理解为自动执行commit).
truncate 和 delete 的区别
从逻辑上说 TRUNCATE 语句与 DELETE 语句作用相同 但是在某些情况下 两者在使用上有所区别.
DELETE是DML类型的语句;TRUNCATE是DDL类型的语句. 它们都用来清空表中的数据.DELETE是逐行一条一条删除记录的;TRUNCATE则是直接删除原来的表 再重新创建一个一模一样的新表 而不是逐行删除表中的数据 执行数据比DELETE快. 因此需要删除表中全部的数据行时 尽量使用TRUNCATE语句 可以缩短执行时间.DELETE删除数据后 配合事件回滚可以找回数据;TRUNCATE不支持事务的回滚 数据删除后无法找回.DELETE删除数据后 系统不会重新设置自增字段的计数器;TRUNCATE清空表记录后 系统会重新设置自增字段的计数器.DELETE的使用范围更广 因为它可以通过WHERE子句指定条件来删除部分数据; 而TRUNCATE不支持WHERE子句 只能删除整体.DELETE会返回删除数据的行数 但是TRUNCATE只会返回 0 没有任何意义.
11.8 collate
这个关键字在涉及到数据库排序上, 需要注意, 如大小写, 中英文等.
MySQL collation是一系列的rules, 用来在特定character set中比较字符.MySQL中支持很多字符集, 而每种字符集会存在多种collation, 并默认选择一种. 字符串比较作用于字符串类型的列, 如VARCHAR,CHAR,TEXT.Collation会影响到ORDER BY, Where, distinct, group by, having以及字符串索引.
collation中一般以"_ci", "_cs","_bin"结尾, 其中, ci表示case insensitive,cs表示case sensitive,bin表示binary. 项目中使用charset utf8并使用其collation utf8_unicode_ci, 所以, 字符串比较是大小写不敏感.
-- 默认的字符集和collation之间的关联
show CHARACTER SET;

show collation;

优先级顺序是 SQL语句 > 列级别设置 > 表级别设置 > 库级别设置 > 实例级别设置.也就是说列上所指定的COLLATE可以覆盖表上指定的COLLATE 表上指定的COLLATE可以覆盖库级别的COLLATE. 如果没有指定 则继承下一级的设置. 即列上面没有指定COLLATE 则该列的COLLATE和表上设置的一样.
SELECT k
FROM t1
ORDER BY k COLLATE latin1_german2_ci;
# 优先使用语句中的collation
在指定的语句下使用相应的collation.
11.9 prepare/execute/deallocate
预编译处理
-
PREPARE
-
EXECUTE
EXECUTE stmt_name [USING @var_name [, @var_name] ...] # 后面传入参数必须事变量名称 -
DEALLOCATE PREPARE
# 动态执行, 需要使用到变量
delimiter $$
CREATE PROCEDURE rand_test_data (in table_name VARCHAR(32), in i_many int)
BEGIN
select i_many as data_count, table_name as 'table_name';
# 注意这里不能使用 declare cmd varchar(64);
set @d_cmd = concat('drop table if EXISTS ', table_name, ';');
# 将字符串编译为sql的实际可执行的语句
PREPARE drop_table_cmd from @d_cmd;
# 执行
EXECUTE drop_table_cmd;
# 删除
DEALLOCATE PREPARE drop_table_cmd;
set @c_cmd = CONCAT('CREATE table ', table_name, ' (id int not null PRIMARY KEY auto_increment, col varchar(32));');
PREPARE create_table_cmd from @c_cmd;
EXECUTE create_table_cmd;
DEALLOCATE PREPARE create_table_cmd;
end $$
delimiter ;
A statement prepared in stored program context cannot refer to stored procedure or function parameters or local variables because they go out of scope when the program ends and would be unavailable were the statement to be executed later outside the program. As a workaround, refer instead to user-defined variables, which also have session scope;
mysql> select * from test_table;
+----+--------------------+
| id | col |
+----+--------------------+
| 0 | 441053925492.851aj |
| 1 | 327509761161.6456a |
| 2 | 314387060063.3203a |
| 3 | 589406047565.3093a |
| 4 | 3869088370.2310624 |
| 5 | 251127329888.87216 |
| 6 | 244029415067.31268 |
| 7 | 466765116403.5919a |
| 8 | 601737367549.6665a |
| 9 | 608391519271.2019a |
+----+--------------------+
10 rows in set (0.00 sec)
# 预编译 - 带有参数的语句
mysql> PREPARE cmd from 'select * from test_table where id = ?;';
Query OK, 0 rows affected (0.01 sec)
Statement prepared
mysql> SET @test_id = 1;
Query OK, 0 rows affected (0.00 sec)
# 传入参数
mysql> EXECUTE cmd USING @test_id;
+----+--------------------+
| id | col |
+----+--------------------+
| 1 | 327509761161.6456a |
+----+--------------------+
1 row in set (0.00 sec)
mysql> EXECUTE cmd using 1;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use
near '1' at line 1
mysql> DEALLOCATE PREPARE cmd;
Query OK, 0 rows affected (0.00 sec)
十二. 函数/存储过程
对于VBA有所了解, 这二者的区别就相对容易区分.
sub, 类似于PROCEDUREfunction, 则对应function
sub t_sub()
debug.print t_func()
end sub
function t_func() as string
test = 'test'
end function
sub test()
t_sub
end sub
'假如 sub t_sub 需要返回数据, 需要通过byref(按引用传递参数), 参数可以被修改, 在原函数/sub中得到这个发生变化的函数, 作为返回值.
sub t_sub(byref i as long)
end sub
返回值的区别.
- 函数有1个返回值,而存储过程是通过参数返回的,可以有多个或者没有
调用的区别,函数可以在查询语句中直接调用,而存储过程必须单独调用.
- 函数: 一般情况下是用来计算并返回一个计算结果;
- 存储过程: 一般是用来完成特定的数据操作( 比如修改 插入数据库表或执行某些DDL语句等等)
| 存储过程 | 函数 |
|---|---|
| 用于在数据库中完成特定的操作或者任务(如插入 删除) | 执行特定的任务, 返回数据. |
程序头部声明用procedure |
程序头部声明用function |
| 程序头部声明时不需要描述返回类型 | 程序头部声明要描述返回类型 而且PL/SQL块中至少要包括一个有效的return语句 |
| 以编译后的形式存放在数据库中 | 以编译后的形式存放在数据库中 |
可以使用in/out/in out三种模式的参数 |
不支持三种模式的参数 |
| 可以作为一个独立的PL/SQL语句来执行 | 不能独立执行 必须作为表达式的一部分调用 |
可以通过out /in out返回零个或者多个值 |
通过return语句返回一个值 且该值要与申明部分一致. |
SQL语句(DML或SELECT)中不可调用存储过程 |
SQL语句(DML或SELECT)中可以调用函数 |
-- shell 中查看内容很混乱, 在navicat中, 查看
show FUNCTION STATUS;
show PROCEDURE STATUS;
12.1 @和@@
@是用户变量 @@是系统变量
一般情况下, 变量前不加 @, 则默认为
session变量
set赋值方式, 注意性能的影响
set @test_int = 1;
set @test_int := 1;
-- 二者是等价的
set @test_int = @test_int + 1;
select @test_int;
# 2
-- 设置系统层的变量
SET GLOBAL varname = some_value;
-- 查看全局变量
SHOW GLOBAL VARIABLES;
select @test_int := 1;
-- 只允许这种方式
-- =, 标识比较符号在select语句
和declare声明变量的主要区别
declare声明的变量只能在存储过程中使用, 而set则不受限制.- 变量的声明周期,
declare相当于vba中的本地变量(JavaScript中的let/const), 用完就扔.set,session相当于模块级别的变量,global相当于public的全局变量, 这些变量可以一直存活, 直到session或者数据库退出才销毁.
12.2 delimiter
delimiter $$
create procedure test()
select * from table;
set i = 1;
.....
end $$
delimiter ;
delimiter, 间隔符, 实际上起到的作用就是将mysql默认的 ";" 符号修改为其他的符号, 如 "$", 来阻止带有";"符号的语句的立即执行.
默认情况下, mysql的间隔符为;, 当语句中包含这个符号, 这个语句就会马上被mysql执行.
修改之后, 就可以输入带有";"的子语句, 而不会马上执行, 只有当语句中包含 delimiter指定的符号才会被执行.
-- 默认状态下";"被视作语句的结尾, 也是执行命令的标识
select * from table;
delimiter主要应用场景为各类复杂语句的创建, 如自定义函数, 事件等.
同时MySQL提供一个\G作为结尾执行的标志, 用于针对多字段的长内容提供更好的阅读体验, 而不是乱糟糟的一堆文字.
character_set_client: utf8mb4
collation_connection: utf8mb4_0900_ai_ci
Database Collation: utf8mb4_0900_ai_ci
*************************** 27. row ***************************
Db: test_db
Name: rand_test_a_data
Type: PROCEDURE
Definer: alex@localhost
Modified: 2023-01-16 21:29:41
Created: 2023-01-16 21:29:41
Security_type: DEFINER
Comment:
character_set_client: utf8mb4
collation_connection: utf8mb4_0900_ai_ci
Database Collation: utf8mb4_0900_ai_ci
*************************** 28. row ***************************
Db: test_db
Name: rand_test_data
Type: PROCEDURE
Definer: root@localhost
Modified: 2023-01-16 19:16:49
Created: 2023-01-16 19:16:49
Security_type: DEFINER
Comment:
character_set_client: utf8mb4
collation_connection: utf8mb4_0900_ai_ci
Database Collation: utf8mb4_0900_ai_ci
28 rows in set (0.00 sec)
12.3 declare
DECLARE var_name[,...] type [DEFAULT value]
DECLAREis permitted only inside aBEGIN ... ENDcompound statement and must be at its start, before any other statements.DECLARE 关键字声明的变量 只能在存储过程(begin...end)中使用, 最开始的行.
The
DECLAREstatement is used to define various items local to a program:
- Local variables. See Section 13.6.4, " Variables in Stored Programs" .
- Conditions and handlers. See Section 13.6.7, " Condition Handling" .
- Cursors. See Section 13.6.6, " Cursors" .
Declarations must follow a certain order. Cursor declarations must appear before handler declarations. Variable and condition declarations must appear before cursor or handler declarations.
声明的先后顺序.
作用:
- 本地变量
- 条件和错误处理
- 游标
-- 用declare定义一个名字为name的字符串类型的变量 变量前面需要加@
-- 常见varchar(MAX), 不限定字符串的长度
declare @name varchar(20);
delimiter $$
drop function if exists rand_string;
create function rand_string(n int) returns varchar(255)
begin
declare chars_str varchar(52) default 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i<n do
set return_str=concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i=i+1;
end while;
return return_str;
end $$
12.4 function
CREATE [AGGREGATE] FUNCTION *function_name* RETURNS {STRING|INTEGER|REAL|DECIMAL} SONAME *shared_library_name*
# 假如出现以下错误
ERROR 1418 (HY000): This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary
logging is enabled ( you * might* want to use the less safe log_bin_trust_function_creators variable)
--------
# 设置mysql
set global log_bin_trust_function_creators = 1;
set log_bin_trust_function_creators = 1
> 1229 - Variable 'log_bin_trust_function_creators' is a GLOBAL variable and should be set with SET GLOBAL
> 时间: 0s
delimiter $$
CREATE function rand_str2(max_len int) returns VARCHAR(20)
BEGIN
if ( max_len > 10) then
set max_len = 10;
ELSEIF (max_len < 2) then
set max_len = 2;
end if;
RETURN substring( rand(), 3, max_len );
END $$
delimiter;
set @r = rand_str2(11);
SELECT @r;
-----------
set @r = rand_str2(1);
SELECT @r;
# 删除func
# 响应的func, 将存储在数据库中
drop function func_name;
12.5 procedure
-
in, 输入参数delimiter $$ create PROCEDURE test_p2 (in i int) BEGIN SELECT * from next where id = i; end $$ delimiter ; call test_p2(1); id name 1 alex # 等价的 set @a = 1; call test_p2(@a); # 直接传入变量 call test_p2(@b); ------------------------------ delimiter $$ create PROCEDURE test_p3 (in i int) BEGIN set i = 3; SELECT * from next where id = i; # 3 end $$ delimiter ; set @o = 1; call test_p3(@o); SELECT @o; # 1 -
inout, 输入/输出参数delimiter $$ create PROCEDURE test_p4 (inout i int) BEGIN set i = 3; SELECT * from next where id = i; # 3 end $$ delimiter ; set @o = 1; call test_p4(@o); SELECT @o; # 3 -
out, 输出参数, 类似于vba的byrefdelimiter $$ create PROCEDURE test_p (out i int) BEGIN # 由于这一步, 传入的是null SELECT i; # null set i = 2; # 对变量进行修改 SELECT i; # 2 end $$ delimiter ; # 相当于 set @a = 0;, 或者之类的生命变量 # 传入参数 @a call test_p(@a); SELECT @a; # 2 # 由于变量在test_p进行赋值2 # 假如直接传入数据 call test_p(0); > 1414 - OUT or INOUT argument 1 for routine test_db.test_p is not a variable or NEW pseudo-variable in BEFORE trigger
# 删除pro
drop PROCEDURE p_name;
十三. 语句
13.1 判断语句
13.1.1 case
SELECT CASE 1
WHEN 1 THEN '男'
WHEN 2 THEN '女'
ELSE '未知'
END
as ages;
13.1.2 if
# if 不带 else
select *, if(age=1,"男","女") as ages from user;
# if 带 else
create procedure dbname.proc_getGrade (stu_no varchar(20),cour_no varchar(10))
BEGIN
# 声明变量
declare stu_grade float;
# 对变量进行赋值
select grade into stu_grade from grade where student_no=stu_no and course_no=cour_no;
# 条件语句
if stu_grade >= 90 then
select stu_grade,'A';
elseif stu_grade < 90 and stu_grade >= 80 then
select stu_grade,'B';
elseif stu_grade < 80 and stu_grade >= 70 then
select stu_grade,'C';
elseif stu_grade < 70 and stu_grade >= 60 then
select stu_grade,'D';
else
select stu_grade,'E';
end if;
end
13.2 循环语句
13.2.1 while
DELIMITER $$
DROP PROCEDURE IF EXISTS test_mysql_while_loop$$
CREATE PROCEDURE test_mysql_while_loop()
BEGIN
DECLARE x INT;
DECLARE str VARCHAR(255);
SET x = 1;
SET str = '';
WHILE x <= 5 DO
SET str = CONCAT(str, x, ',');
SET x = x + 1;
END WHILE;
SELECT str;
END$$
DELIMITER ;
13.2.2 loop
[begin_label:] LOOP
statement_list
END LOOP [end_label]
CREATE PROCEDURE doiterate(p1 INT)
BEGIN
label1: LOOP
SET p1 = p1 + 1;
IF p1 < 10 THEN
ITERATE label1;
END IF;
LEAVE label1;
END LOOP label1;
SET @x = p1;
END;
-- 计算从1到n的值
DELIMITER $$
create procedure pro_test10(n int)
begin
declare total int default 0;
c:loop
set total = total + n;
set n = n -1;
if n <= 0 then
leave c;
end if;
end loop c;
select total;
end$
DELIMITER ;
13.2.3 repeat
REPEAT
statement_list
UNTIL search_condition END REPEAT;
-- --------------------------------------------------
delimiter $$
CREATE PROCEDURE rand_test_data (in i_many int)
BEGIN
DECLARE ic int DEFAULT 0;
drop table if EXISTS test_table;
CREATE TABLE test_table (id int not null PRIMARY key auto_increment, col varchar(32));
# 先将自动事务提交关闭
set @autocommit = 0;
REPEAT
# 执行需要循环的数据
insert into test_table (col) VALUES (LEFT ( concat( 1000000000000000 * rand(), 'ajkshxm' ), 18 ));
set ic = ic + 1;
UNTIL
# 退出执行的条件
ic = i_many
END REPEAT;
# 改为手动提交
COMMIT;
# 恢复设置
set @autocommit = 1;
end $$
delimiter ;
注意有个同名字符串函数:
mysql> SELECT REPEAT("a", 3);
+----------------+
| REPEAT("a", 3) |
+----------------+
| aaa |
+----------------+
1 row in set (0.00 sec)
13.3 公共表达式(CET)
这是mysql8.x之后版本启用的新特性.
WITH
cte1 AS (SELECT a, b FROM table1),
cte2 AS (SELECT c, d FROM table2)
SELECT b, d FROM cte1 JOIN cte2
WHERE cte1.a = cte2.c;
# 可复用对于数据的影响.
mysql> SELECT q1.year,q2.year AS next_year, q1.sum, q2.sum AS next_sum,
-> 100*(q2.sum-q1.sum)/q1.sum AS pct
-> FROM (SELECT year(from_date) as year, sum(salary) as sum FROM salaries GROUP BY year) AS q1,
-> (SELECT year(from_date) as year, sum(salary) as sum FROM salaries GROUP BY year) AS q2
-> WHERE q1.year=q2.year-1;
+------+-----------+-------------+-------------+----------+
| year | next_year | sum | next_sum | pct |
+------+-----------+-------------+-------------+----------+
| 1985 | 1986 | 972864875 | 2052895941 | 111.0155 |
| 1986 | 1987 | 2052895941 | 3156881054 | 53.7770 |
| 1987 | 1988 | 3156881054 | 4295598688 | 36.0710 |
| 1988 | 1989 | 4295598688 | 5454260439 | 26.9732 |
| 1989 | 1990 | 5454260439 | 6626146391 | 21.4857 |
| 1990 | 1991 | 6626146391 | 7798804412 | 17.6974 |
| 1991 | 1992 | 7798804412 | 9027872610 | 15.7597 |
| 1992 | 1993 | 9027872610 | 10215059054 | 13.1502 |
| 1993 | 1994 | 10215059054 | 11429450113 | 11.8882 |
| 1994 | 1995 | 11429450113 | 12638817464 | 10.5812 |
| 1995 | 1996 | 12638817464 | 13888587737 | 9.8883 |
| 1996 | 1997 | 13888587737 | 15056011781 | 8.4056 |
| 1997 | 1998 | 15056011781 | 16220495471 | 7.7343 |
| 1998 | 1999 | 16220495471 | 17360258862 | 7.0267 |
| 1999 | 2000 | 17360258862 | 17535667603 | 1.0104 |
| 2000 | 2001 | 17535667603 | 17507737308 | -0.1593 |
| 2001 | 2002 | 17507737308 | 10243347616 | -41.4925 |
+------+-----------+-------------+-------------+----------+
17 rows in set (2.37 sec)
mysql> WITH CTE AS
-> (SELECT year(from_date) AS year, SUM(salary) AS sum FROM salaries GROUP BY year)
-> SELECT q1.year,q2.year AS next_year, q1.sum, q2.sum AS next_sum,
-> 100*(q2.sum-q1.sum)/q1.sum AS pct FROM
-> CTE AS q1, CTE AS q2
-> WHERE q1.year = q2.year-1;
+------+-----------+-------------+-------------+----------+
| year | next_year | sum | next_sum | pct |
+------+-----------+-------------+-------------+----------+
| 1985 | 1986 | 972864875 | 2052895941 | 111.0155 |
| 1986 | 1987 | 2052895941 | 3156881054 | 53.7770 |
| 1987 | 1988 | 3156881054 | 4295598688 | 36.0710 |
| 1988 | 1989 | 4295598688 | 5454260439 | 26.9732 |
| 1989 | 1990 | 5454260439 | 6626146391 | 21.4857 |
| 1990 | 1991 | 6626146391 | 7798804412 | 17.6974 |
| 1991 | 1992 | 7798804412 | 9027872610 | 15.7597 |
| 1992 | 1993 | 9027872610 | 10215059054 | 13.1502 |
| 1993 | 1994 | 10215059054 | 11429450113 | 11.8882 |
| 1994 | 1995 | 11429450113 | 12638817464 | 10.5812 |
| 1995 | 1996 | 12638817464 | 13888587737 | 9.8883 |
| 1996 | 1997 | 13888587737 | 15056011781 | 8.4056 |
| 1997 | 1998 | 15056011781 | 16220495471 | 7.7343 |
| 1998 | 1999 | 16220495471 | 17360258862 | 7.0267 |
| 1999 | 2000 | 17360258862 | 17535667603 | 1.0104 |
| 2000 | 2001 | 17535667603 | 17507737308 | -0.1593 |
| 2001 | 2002 | 17507737308 | 10243347616 | -41.4925 |
+------+-----------+-------------+-------------+----------+
17 rows in set (1.18 sec)
mysql> select count(*) from salaries;
+----------+
| count(*) |
+----------+
| 2844047 |
+----------+
1 row in set (0.05 sec)
13.3.1 递归CET

递归成员不得包含以下结构:
# 当在表中操作, n会报不存在字段的问题
mysql> WITH RECURSIVE cte_count (n)
-> AS (
-> SELECT 1
-> UNION ALL
-> SELECT n + 1
-> FROM cte_count
-> WHERE n < 3
SELE -> )
-> SELECT n
-> FROM cte_count;
+------+
| n |
+------+
| 1 |
| 2 |
| 3 |
+------+
3 rows in set (0.00 sec)
递归CTE由三个主要部分组成:
- 初始查询 形成CTE结构的基本结果集. 初始查询部分称为锚成员.
- 递归查询部分是引用CTE名称的查询 因此 它被称为递归成员. 递归成员由
UNION ALL或UNION DISTINCT运算符与锚成员连接. - 终止条件 确保递归成员不返回任何行时停止递归.
递归CTE的执行顺序如下:
- 首先 将成员分为两部分: 锚点和递归成员.
- 接下来 执行锚成员以形成基本结果集(
R0) 并将此基本结果集用于下一次迭代. - 然后 执行带有
Ri结果集作为输入的递归成员并将其Ri+1作为输出. - 之后 重复第三步 直到递归成员返回空结果集 换句话说 满足终止条件.
- 最后 使用
UNION ALL运算符将结果集从R0到Rn组合.
drop table if exists test;
create table test(id int not null, col char(18) not null);
insert into test(id, col)
with recursive temp as (
# 1 n, 为了引入变量n
select 1 n, LEFT ( concat( 100000000000000 * rand(), 'ajkshxm' ), 18 )
union
select n + 1, LEFT ( concat( 100000000000000 * rand(), 'ajkshxm' ), 18 ) from temp where n < 1000)
select * from temp;
insert into test(id, col) select 2000 + id, LEFT ( concat( 100000000000000 * rand(), 'ajkshxm' ), 18 ) from test where id < 500000;
# 只会执行前1000次
# 递归的最大深度, 默认为1000
mysql> show variables like '%recursion%';
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| cte_max_recursion_depth | 1000 |
| max_sp_recursion_depth | 0 |
+-------------------------+-------+
十四. 十四. 查询

SELECT column_name,column_name FROM table_name [WHERE Clause] [LIMIT N][ OFFSET M]
- select
- where
- group by
- order by
- having
- union
- like, or, and, exists, in between
14.1 联表查询
(INNER)JOIN: 返回两个表中具有匹配值的记录LEFT( OUTER) JOIN: 返回左表中的所有记录 以及右表中的匹配记录RIGHT( OUTER) JOIN: 返回右表中的所有记录 以及左表中匹配的记录FULL( OUTER) JOIN: 当左表或右表中匹配时返回所有记录(注意:mysql并不支持此项)
# 注意, 其执行的逻辑
# 拿左表去对应数据, 然后根据对应的join方式得到数据, 假如有where, 再进一步处理数据
|id_left|id_right|
|1|null
|2|2|
|3|3|
# 返回左表对应的数据
mysql> select t1.id from t1 left join t2 on t1.id = t2.id;
# 1, 没有对应的数据, 但是属于左表, 同样返回
+----+
| id |
+----+
| 1 |
| 2 |
| 3 |
+----+
3 rows in set (0.00 sec)
# 返回左表的数据, 但是其判断的依据是量表进行匹配后, 与左边对应的右表的项为空的项
# 执行先后, join 优先于 where
# 即拿到了join的数据, 然后再进行where筛选
mysql> select t1.id from t1 left join t2 on t1.id = t2.id where t2.id is null;
+----+
| id |
+----+
| 1 |
+----+
1 row in set (0.00 sec)
# INSERT INTO t1 VALUES (1),(2),(3);
# INSERT INTO t2 VALUES (2),(3),(4);
# 返回两个表都存在的数据
mysql> select t1.id from t1 join t2 on t1.id = t2.id;
+----+
| id |
+----+
| 2 |
| 3 |
+----+
2 rows in set (0.00 sec)
|t2|t1|
|2|2|
|3|3|
|4|null|
# 返回右侧的内容 t1
mysql> select t1.id from t1 right join t2 on t1.id = t2.id;
+------+
| id |
+------+
| 2 |
| 3 |
| NULL |
+------+
3 rows in set (0.00 sec)
# 返回右侧表的, t1
mysql> select t1.id from t1 right join t2 on t1.id = t2.id where t1.id is null;
+------+
| id |
+------+
| NULL |
+------+
1 row in set (0.00 sec)
# join full?
mysql> select * from t1 left join t2 on t1.id = t2.id
-> union
-> select *
-> from t1 right join t2 on t1.id = t2.id;
+------+------+
| id | id |
+------+------+
| 1 | NULL |
| 2 | 2 |
| 3 | 3 |
| NULL | 4 |
+------+------+
4 rows in set (0.00 sec)
14.2 并集(union)
和jon的差异, 主要在于join是横向组合数据, 而union是纵向组合数据的.
CREATE TABLE t1 (
id INT PRIMARY KEY
);
CREATE TABLE t2 (
id INT PRIMARY KEY
);
INSERT INTO t1 VALUES (1),(2),(3);
INSERT INTO t2 VALUES (2),(3),(4);
# union, 去重, 只保留一份数据
mysql> SELECT id
-> FROM t1
ION
S -> UNION
-> SELECT id
-> FROM t2;
+----+
| id |
+----+
| 1 |
| 2 |
| 3 |
| 4 |
+----+
4 rows in set (0.00 sec)
# union all, 交集部分不作去重
mysql> SELECT id
-> FROM t1
-> UNION ALL
-> SELECT id
-> FROM t2;
+----+
| id |
+----+
| 1 |
| 2 |
| 3 |
| 2 |
| 3 |
| 4 |
+----+
6 rows in set (0.01 sec)
14.3 交集(intersect)
- 列数量相同
- 列数据类型相同
mysql> (SELECT id
-> FROM t1)
-> INTERSECT
-> (SELECT id
-> FROM t2);
+----+
| id |
+----+
| 2 |
| 3 |
+----+
2 rows in set (0.00 sec)
# 等价于inner join
mysql> select t1.id from t1 join t2 on t1.id = t2.id;
+----+
| id |
+----+
| 2 |
| 3 |
+----+
2 rows in set (0.00 sec)
14.4 笛卡尔乘积(cross join)
笛卡尔乘积, 即穷举出所有的两个表的组合.
mysql> select * from t1 cross join t2;
+----+----+
| id | id |
+----+----+
| 3 | 2 |
| 2 | 2 |
| 1 | 2 |
| 3 | 3 |
| 2 | 3 |
| 1 | 3 |
| 3 | 4 |
| 2 | 4 |
| 1 | 4 |
+----+----+
9 rows in set (0.00 sec)
# cross
mysql> select * from t1 join t2;
+------+------+
| id | id |
+------+------+
| 3 | 2 |
| 2 | 2 |
| 1 | 2 |
| 3 | 3 |
| 2 | 3 |
| 1 | 3 |
| 3 | 4 |
| 2 | 4 |
| 1 | 4 |
+------+------+
9 rows in set (0.00 sec)
14.5 自连接(self join)
自连接, 即自我连接.
mysql> select employeeNumber, lastName, firstName, reportsTo from employees limit 5;
+----------------+-----------+-----------+-----------+
| employeeNumber | lastName | firstName | reportsTo |
+----------------+-----------+-----------+-----------+
| 1002 | Murphy | Diane | NULL |
| 1056 | Patterson | Mary | 1002 |
| 1076 | Firrelli | Jeff | 1002 |
| 1088 | Patterson | William | 1056 |
| 1102 | Bondur | Gerard | 1056 |
+----------------+-----------+-----------+-----------+
5 rows in set (0.00 sec)
mysql> SELECT
-> CONCAT(m.lastname, ', ', m.firstname) AS 'Manager',
-> CONCAT(e.lastname, ', ', e.firstname) AS 'Direct report'
-> FROM
-> employees e
INN -> INNER JOIN
-> employees m ON m.employeeNumber = e.reportsto
-> ORDER BY manager;
+--------------------+--------------------+
| Manager | Direct report |
+--------------------+--------------------+
| Bondur, Gerard | Bondur, Loui |
| Bondur, Gerard | Gerard, Martin |
| Bondur, Gerard | Jones, Barry |
| Bondur, Gerard | Bott, Larry |
| Bondur, Gerard | Castillo, Pamela |
| Bondur, Gerard | Hernandez, Gerard |
| Bow, Anthony | Thompson, Leslie |
| Bow, Anthony | Firrelli, Julie |
| Bow, Anthony | Patterson, Steve |
| Bow, Anthony | Tseng, Foon Yue |
| Bow, Anthony | Vanauf, George |
| Bow, Anthony | Jennings, Leslie |
| Murphy, Diane | Patterson, Mary |
| Murphy, Diane | Firrelli, Jeff |
| Nishi, Mami | Kato, Yoshimi |
| Patterson, Mary | Bow, Anthony |
| Patterson, Mary | Bondur, Gerard |
| Patterson, Mary | Patterson, William |
| Patterson, Mary | Nishi, Mami |
| Patterson, William | Fixter, Andy |
| Patterson, William | Marsh, Peter |
| Patterson, William | King, Tom |
+--------------------+--------------------+
22 rows in set (0.00 sec)
14.6 聚合查询
以牛客网的测试题作为示例
SQL156, 各个视频的平均完播率
# 相对麻烦的是多次计算
# if () 作为辅助计算
# having 使用的麻烦
with
t2 as (SELECT t3.video_id, if (( t1.end_time - t1.start_time - t3.duration )>=0, 1, 0) as finish FROM tb_video_info t3 JOIN tb_user_video_log t1 ON t1.video_id = t3.video_id)
select video_id, (sum(finish) / count(video_id)) as avg_rate from t2 GROUP BY video_id;
# 注意having的在多个temp table中的使用
- SQL180 某宝店铺的SPU数量
mysql> select style_id, count(style_id) SPU_num from product_tb group by style_id order by SPU_num desc;
+----------+---------+
| style_id | SPU_num |
+----------+---------+
| B | 4 |
| A | 3 |
| C | 2 |
+----------+---------+
3 rows in set (0.00 sec)
14.7 窗口函数
内容较多, 且重要, 单独拆分出来, 详细内容见MySQL窗口函数详解.
在窗口函数中, 注意对于聚合函数, 诸如sum, count等的使用, 很容易触发以下错误.
SQL_ERROR_INFO: "In aggregated query without GROUP BY, expression #1 of SELECT list contains nonaggregated column 'base_table.user_id'; this is incompatible with sql_mode=only_full_group_by"
注意各类函数之间大搭配使用, 如having, 就应该和group by进行一起使用. 在经过聚合处理的临时表, 引用聚合函数, sum等时, 注意聚合的字段和聚合的数据所在的字段.
关于这个问题, 详情见
MySQL翻译系列-MySQL Handling of GROUP BY

窗口函数即OLAP, Online Anallytical Processing 联机分析处理.
简而言之, 窗口函数强化了MySQL在数据分析的能力, 通过窗口函数可以实现较为复杂的常态化数据的直接输出, 例如经典的多层级的汇总, topN问题等.
注意: 这是MySQL专属函数, 不是标准的SQL语句, 需要8.x版本MySQL才支持(大部分的数据库都支持类似的功能, 如SQLite).
| Name | Description |
|---|---|
CUME_DIST() |
Cumulative distribution value, 累计分布 |
DENSE_RANK() |
Rank of current row within its partition, without gaps, 排名 |
FIRST_VALUE() |
Value of argument from first row of window frame,取值 |
LAG() |
Value of argument from row lagging current row within partition, 取值 |
LAST_VALUE() |
Value of argument from last row of window frame, 取值 |
LEAD() |
Value of argument from row leading current row within partition, 取值 |
NTH_VALUE() |
Value of argument from N-th row of window frame |
NTILE() |
Bucket number of current row within its partition. 分桶 |
PERCENT_RANK() |
Percentage rank value, 排名占比 |
RANK() |
Rank of current row within its partition, with gaps, 排名 |
ROW_NUMBER() |
Number of current row within its partition, 行号 |
一般语法结构
window_function_name (expression)
OVER (
[partition_defintion]
[order_definition]
[frame_definition]
)
SELECT fiscal_year, sales_employee, sale, SUM( sale ) OVER ( PARTITION BY fiscal_year ) as total_sales FROM sales;
-- 创建表格
CREATE TABLE sales(
sales_employee VARCHAR(50) NOT NULL,
fiscal_year INT NOT NULL,
sale DECIMAL(14,2) NOT NULL,
PRIMARY KEY(sales_employee,fiscal_year)
);
-- 插入数据
INSERT INTO sales(sales_employee,fiscal_year,sale)
VALUES('Bob',2016,100),
('Bob',2017,150),
('Bob',2018,200),
('Alice',2016,150),
('Alice',2017,100),
('Alice',2018,200),
('John',2016,200),
('John',2017,150),
('John',2018,250);
# 查看
mysql> select * from sales;
+----------------+-------------+--------+
| sales_employee | fiscal_year | sale |
+----------------+-------------+--------+
| Alice | 2016 | 150.00 |
| Alice | 2017 | 100.00 |
| Alice | 2018 | 200.00 |
| Bob | 2016 | 100.00 |
| Bob | 2017 | 150.00 |
| Bob | 2018 | 200.00 |
| John | 2016 | 200.00 |
| John | 2017 | 150.00 |
| John | 2018 | 250.00 |
+----------------+-------------+--------+
14.7.1 分组函数
# 常见的汇总
# 筛选出每个sale_employee的总销售额
mysql> select sales_employee, sum(sale) as total from sales group by sales_employee;
+----------------+--------+
| sales_employee | total |
+----------------+--------+
| Alice | 450.00 |
| Bob | 450.00 |
| John | 600.00 |
+----------------+--------+
3 rows in set (0.00 sec)
# 计算出每一年的销售总额, 以及每个sale的占比
mysql> SELECT *, concat ( left (temp.sale / temp.total_sales * 100, 5),'%') as ratio
-> FROM
-> ( SELECT fiscal_year, sales_employee, sale, SUM( sale ) OVER ( PARTITION BY fiscal_year ) as total_sales FROM sales ) as temp;
+-------------+----------------+--------+-------------+--------+
| fiscal_year | sales_employee | sale | total_sales | ratio |
+-------------+----------------+--------+-------------+--------+
| 2016 | Alice | 150.00 | 450.00 | 33.33% |
| 2016 | Bob | 100.00 | 450.00 | 22.22% |
| 2016 | John | 200.00 | 450.00 | 44.44% |
| 2017 | Alice | 100.00 | 400.00 | 25.00% |
| 2017 | Bob | 150.00 | 400.00 | 37.50% |
| 2017 | John | 150.00 | 400.00 | 37.50% |
| 2018 | Alice | 200.00 | 650.00 | 30.76% |
| 2018 | Bob | 200.00 | 650.00 | 30.76% |
| 2018 | John | 250.00 | 650.00 | 38.46% |
+-------------+----------------+--------+-------------+--------+
9 rows in set (0.00 sec)
-
partition, 分组函数, 但是和常规的group by有所区别的是,partition不会将数据进行合并压缩, 而是保留数据, 将计算的结果全部逐行放置.在
pandas中有对应的函数, 即transform函数, 同样也有同名的group by函数.import pandas as pd dfx = pd.DataFrame(data=[['a', 1,2], ['b', 2,3], ['a', 1,9], ['b', 3,4]], columns=['aa', 'bb', 'cc']) dfx.groupby(by=['aa']).transform(sum) bb cc 0 2 11 1 5 7 2 2 11 3 5 7该函数用于解决, 数据处理后, 源数据丢失的问题.
14.7.2 排名函数
# 筛选出每个年度最高的sales_employee, topN
mysql> SELECT * from
->
-> (select *, DENSE_RANK() over (partition by fiscal_year order by sale desc) as r from sales) as temp where temp.r = 1;
+----------------+-------------+--------+---+
| sales_employee | fiscal_year | sale | r |
+----------------+-------------+--------+---+
| John | 2016 | 200.00 | 1 |
| Bob | 2017 | 150.00 | 1 |
| John | 2017 | 150.00 | 1 |
| John | 2018 | 250.00 | 1 |
+----------------+-------------+--------+---+
4 rows in set (0.00 sec)
# 如果不需要相同的数值, 选用row_number
mysql> SELECT * from
->
-> (select *, ROW_NUMBER() over (partition by fiscal_year order by sale desc) as r from sales) as temp where temp.r = 1;
+----------------+-------------+--------+---+
| sales_employee | fiscal_year | sale | r |
+----------------+-------------+--------+---+
| John | 2016 | 200.00 | 1 |
| Bob | 2017 | 150.00 | 1 |
| John | 2018 | 250.00 | 1 |
+----------------+-------------+--------+---+
3 rows in set (0.00 sec)
mysql> select *, RANK() over (partition by fiscal_year order by sale desc) as r from sales;
+----------------+-------------+--------+---+
| sales_employee | fiscal_year | sale | r |
+----------------+-------------+--------+---+
| John | 2016 | 200.00 | 1 |
| Alice | 2016 | 150.00 | 2 |
| Bob | 2016 | 100.00 | 3 |
| Bob | 2017 | 150.00 | 1 |
| John | 2017 | 150.00 | 1 |
| Alice | 2017 | 100.00 | 3 | # 注意
| John | 2018 | 250.00 | 1 |
| Alice | 2018 | 200.00 | 2 |
| Bob | 2018 | 200.00 | 2 |
+----------------+-------------+--------+---+
9 rows in set (0.00 sec)
mysql> select *, dense_rank() over (partition by fiscal_year order by sale desc) as r from sales;
+----------------+-------------+--------+---+
| sales_employee | fiscal_year | sale | r |
+----------------+-------------+--------+---+
| John | 2016 | 200.00 | 1 |
| Alice | 2016 | 150.00 | 2 |
| Bob | 2016 | 100.00 | 3 |
| Bob | 2017 | 150.00 | 1 |
| John | 2017 | 150.00 | 1 |
| Alice | 2017 | 100.00 | 2 | # 注意
| John | 2018 | 250.00 | 1 |
| Alice | 2018 | 200.00 | 2 |
| Bob | 2018 | 200.00 | 2 |
+----------------+-------------+--------+---+
mysql> select *, row_number() over (partition by fiscal_year order by sale desc) as r from sales;
+----------------+-------------+--------+---+
| sales_employee | fiscal_year | sale | r |
+----------------+-------------+--------+---+
| John | 2016 | 200.00 | 1 |
| Alice | 2016 | 150.00 | 2 |
| Bob | 2016 | 100.00 | 3 |
| Bob | 2017 | 150.00 | 1 |
| John | 2017 | 150.00 | 2 |
| Alice | 2017 | 100.00 | 3 |
| John | 2018 | 250.00 | 1 |
| Alice | 2018 | 200.00 | 2 |
| Bob | 2018 | 200.00 | 3 |
+----------------+-------------+--------+---+
9 rows in set (0.00 sec)
-
dense_rank, 1,1,2, 这里的排序当, 出现重复项. -
rank, 1, 1, 3, 这里的排序当, 出现重复项. -
row_number,1, 2, 3, 排序, 给出的是行号, 并不是排名. -
pandas中相关的方法为.# 基于年份, 取出总营收前三的项目 df.sort_values(by=['营业总收入'], ascending=False).groupby(by=['year']).head(3)
14.7.3 分桶函数
# 内置数据库
mysql> SELECT *, NTILE(2) over (partition by CountryCode order by Population) as nt from city limit 10;
+-----+----------------+-------------+----------+------------+----+
| ID | Name | CountryCode | District | Population | nt |
+-----+----------------+-------------+----------+------------+----+
| 129 | Oranjestad | ABW | – | 29034 | 1 |
| 4 | Mazar-e-Sharif | AFG | Balkh | 127800 | 1 |
| 3 | Herat | AFG | Herat | 186800 | 1 |
| 2 | Qandahar | AFG | Qandahar | 237500 | 2 |
| 1 | Kabul | AFG | Kabol | 1780000 | 2 |
| 60 | Namibe | AGO | Namibe | 118200 | 1 |
| 59 | Benguela | AGO | Benguela | 128300 | 1 |
| 58 | Lobito | AGO | Benguela | 130000 | 1 |
| 57 | Huambo | AGO | Huambo | 163100 | 2 |
| 56 | Luanda | AGO | Luanda | 2022000 | 2 |
+-----+----------------+-------------+----------+------------+----+
10 rows in set (0.01 sec)
# 计算占比
# 2020年支付金额排名前30%的用户, 以及该用户支付的金额占当年的总额的百分比
# 局部, 和全局同时计算的问题
# 1. 找出2020年的用户
# 2. 按照用户名计算出各个用户之间的金额
# 3. 找出前30%
# 4. 计算单个用户支出占整体的金额
WITH a AS ( SELECT * FROM test_c WHERE YEAR ( pay_time ) = 2020 ),
b AS ( SELECT user_name, sum( pay_amount ) AS user_total FROM a GROUP BY user_name ),
c AS (
SELECT
user_name,
sum( user_total ) over ( PARTITION BY NULL ) AS total,
NTILE( 10 ) over ( ORDER BY user_total DESC ) AS part
FROM
b
) SELECT
b.user_name,
round( b.user_total, 2 ) AS user_pay_total,
concat( round( user_total / total * 100, 2 ), '%' ) AS percent
FROM
b
left JOIN c ON b.user_name = c.user_name
WHERE
c.part < 4;
# 优化版本
WITH a AS ( SELECT user_name, sum( pay_amount ) AS total FROM test_c WHERE YEAR ( pay_time ) = 2020 GROUP BY user_name ),
b AS (
SELECT
user_name,
total,
sum( total ) over ( PARTITION BY NULL ) AS all_total,
ntile( 10 ) over ( ORDER BY total DESC ) AS s_part
FROM
a
) SELECT
user_name,
round( total, 2 ) AS user_pay_total,
concat( round( total / all_total * 100, 2 ), '%' ) AS user_percent
FROM
b
WHERE
s_part < 4;
+-----------+----------------+--------------+
| user_name | user_pay_total | user_percent |
+-----------+----------------+--------------+
| Moore | 686598 | 8.1% |
| KAREN | 626604 | 7.39% |
| Marshall | 586654.2 | 6.92% |
| Frank | 579942 | 6.84% |
| Emma | 564388 | 6.66% |
| King | 553344 | 6.53% |
| Keith | 493580.9 | 5.82% |
| JUNE | 379962 | 4.48% |
| Amanda | 359964 | 4.24% |
| Morris | 318814 | 3.76% |
| Bonnie | 310746 | 3.66% |
| Francis | 236731.2 | 2.79% |
| Carroll | 228866 | 2.7% |
| Christy | 218186.4 | 2.57% |
| Ethan | 208736 | 2.46% |
| Ray | 202202 | 2.38% |
| Regan | 195536 | 2.31% |
| Knight | 193314 | 2.28% |
| DAISY | 188870 | 2.23% |
| Ailsa | 151096 | 1.78% |
| Iris | 139986 | 1.65% |
+-----------+----------------+--------------+
21 rows in set (0.01 sec)
ntile, 分桶/分箱.pandas中对应的函数,cut/qcut.
14.7.4 滑动函数
# 连续问题, 例如网站的登录, 哪些用户连续 N天 登录
select *, dense_rank() over (partition by user_id order by login_date) as r from SQL_8;
+---------+------------+---+
| user_id | login_date | r |
+---------+------------+---+
| A | 2022-09-02 | 1 |
| A | 2022-09-03 | 2 |
| A | 2022-09-03 | 2 |
| A | 2022-09-04 | 3 |
| A | 2022-10-03 | 4 |
| B | 2021-11-25 | 1 |
| B | 2021-12-31 | 2 |
| B | 2022-01-04 | 3 |
| B | 2022-01-05 | 4 |
| B | 2022-11-16 | 5 |
| B | 2022-11-17 | 6 |
| C | 2022-01-01 | 1 |
| C | 2022-04-04 | 2 |
| C | 2022-09-03 | 3 |
| C | 2022-09-04 | 4 |
| C | 2022-09-05 | 5 |
| D | 2022-10-20 | 1 |
| D | 2022-10-21 | 2 |
| D | 2022-10-22 | 3 |
| D | 2022-10-23 | 4 |
+---------+------------+---+
20 rows in set (0.00 sec)
# 过滤掉日期, 用户id相同的项
mysql> select distinct user_id, login_date from SQL_8;
+---------+------------+
| user_id | login_date |
+---------+------------+
| A | 2022-09-02 |
| A | 2022-09-03 |
| A | 2022-09-04 |
| B | 2021-11-25 |
| B | 2021-12-31 |
| C | 2022-01-01 |
| C | 2022-04-04 |
| C | 2022-09-03 |
| C | 2022-09-05 |
| C | 2022-09-04 |
| D | 2022-10-20 |
| D | 2022-10-21 |
| A | 2022-10-03 |
| D | 2022-10-22 |
| D | 2022-10-23 |
| B | 2022-01-04 |
| B | 2022-01-05 |
| B | 2022-11-16 |
| B | 2022-11-17 |
+---------+------------+
19 rows in set (0.00 sec)
# 对数据的预处理
# 连续, 则意味着, 登录的实践间隔为1
# 将上述两个语句串联起来
mysql> with tmp as (select distinct user_id, login_date from SQL_8)
->
-> select *, dense_rank() over (partition by user_id order by login_date) as r from tmp;
+---------+------------+---+
| user_id | login_date | r |
+---------+------------+---+
| A | 2022-09-02 | 1 |
| A | 2022-09-03 | 2 |
| A | 2022-09-04 | 3 |
| A | 2022-10-03 | 4 |
| B | 2021-11-25 | 1 |
| B | 2021-12-31 | 2 |
| B | 2022-01-04 | 3 |
| B | 2022-01-05 | 4 |
| B | 2022-11-16 | 5 |
| B | 2022-11-17 | 6 |
| C | 2022-01-01 | 1 |
| C | 2022-04-04 | 2 |
| C | 2022-09-03 | 3 |
| C | 2022-09-04 | 4 |
| C | 2022-09-05 | 5 |
| D | 2022-10-20 | 1 |
| D | 2022-10-21 | 2 |
| D | 2022-10-22 | 3 |
| D | 2022-10-23 | 4 |
+---------+------------+---+
19 rows in set (0.00 sec)
mysql> with tmp as (select distinct user_id, login_date from SQL_8),
->
-> tmp_a as (select *, dense_rank() over (partition by user_id order by login_date) as r from tmp)
->
-> select *, DATE_SUB(login_date, interval r day) as sub from tmp_a;
+---------+------------+---+------------+
| user_id | login_date | r | sub |
+---------+------------+---+------------+
| A | 2022-09-02 | 1 | 2022-09-01 |
| A | 2022-09-03 | 2 | 2022-09-01 |
| A | 2022-09-04 | 3 | 2022-09-01 |
| A | 2022-10-03 | 4 | 2022-09-29 |
| B | 2021-11-25 | 1 | 2021-11-24 |
| B | 2021-12-31 | 2 | 2021-12-29 |
| B | 2022-01-04 | 3 | 2022-01-01 |
| B | 2022-01-05 | 4 | 2022-01-01 |
| B | 2022-11-16 | 5 | 2022-11-11 |
| B | 2022-11-17 | 6 | 2022-11-11 |
| C | 2022-01-01 | 1 | 2021-12-31 |
| C | 2022-04-04 | 2 | 2022-04-02 |
| C | 2022-09-03 | 3 | 2022-08-31 |
| C | 2022-09-04 | 4 | 2022-08-31 |
| C | 2022-09-05 | 5 | 2022-08-31 |
| D | 2022-10-20 | 1 | 2022-10-19 |
| D | 2022-10-21 | 2 | 2022-10-19 |
| D | 2022-10-22 | 3 | 2022-10-19 |
| D | 2022-10-23 | 4 | 2022-10-19 |
+---------+------------+---+------------+
19 rows in set (0.00 sec)
# 假如连续间隔, 在剪掉排名对应的顺序, 时, 则得到的日期将是相同的
mysql> with
-> tmp as (select distinct user_id, login_date from SQL_8),
->
-> tmp_a as (select *, dense_rank() over (partition by user_id order by login_date) as r from tmp),
->
-> tmp_b as (select *, DATE_SUB(login_date, interval r day) as sub from tmp_a)
select ->
-> select tmp_b.user_id, count(*) as c from tmp_b group by tmp_b.user_id, tmp_b.sub having c > 2;
+---------+---+
| user_id | c |
+---------+---+
| A | 3 |
| C | 3 |
| D | 4 |
+---------+---+
3 rows in set (0.00 sec)
# 更为强大的滑动窗口函数
mysql> with
-> tmp as (select distinct user_id, login_date from SQL_8),
temp as (selec -> temp as (select *, count(user_id) over (partition by user_id order by login_date range between interval '3' day preceding and current row) as ic from tmp)
->
-> select temp.user_id, temp.ic from temp where temp.ic > 2;
+---------+----+
| user_id | ic |
+---------+----+
| A | 3 |
| C | 3 |
| D | 3 |
| D | 4 |
+---------+----+
# 注意最后的一句语句的写法
select tmp_b.user_id, count(tmp_b.sub) as c from tmp_b group by tmp_b.sub;
ERROR 1055 (42000): Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'tmp_b.user_id' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
# https://huaweicloud.csdn.net/633550cfd3efff3090b54121.html
# https://stackoverflow.com/questions/51856270/error-code-1055-expression-1-of-select-list-is-not-in-group-by-clause-and-con
-
with关键词mysql> with -> tmp as (select distinct user_id, login_date from SQL_8), -> -> tmp_a as (select *, dense_rank() over (partition by user_id order by login_date) as r from tmp), -> -> tmp_b as (select *, DATE_SUB(login_date, interval r day) as sub from tmp_a); # 解决使用多个临时表过于混乱的问题 -
date_sub函数, 从日期减去指定的时间间隔.语法
DATE_SUB(date,INTERVAL expr type)
date参数是合法的日期表达式,expr参数是您希望添加的时间间隔.间隔时间支持见下面时间处理
[
BETWEEN AND ]
rows: 表示按照行的范围进行定义框架 根据order by子句排序后 取的前N行及后N行的数据计算( 与当前行的值无关 只与排序后的行号相关) . 常用:rows n perceding表示从当前行到前n行( 一共n+1行)range: 表示按照值的范围进行定义框架 根据order by子句排序后 指定当前行对应值的范围取值 行数不固定 只要行值在范围内 对应行都包含在内. 适用于对日期 时间 数值排序分组
| 边界可取值( Start expr & End expr) | 说明 |
|---|---|
| Current Row | 当前行 |
| N preceding | 前 n 行 n 为数字 比如 2 Preceding 表示前2行 |
| unbounded preceding | 开头 |
| N following | 后N行 n 为数字 比如 2 following 表示后2行 |
| unbounded following | 结尾 |
| range取特定日期区间 | 说明 |
|---|---|
| range interval 7-1 day preceding | 最近7天的值 |
| range between interval 1 day preceding and interval 1 day following | 前后一天和当天的值 |
rows between 1 preceding and 1 following 窗口范围是分区中的当前行 前一行 后一行一共三
行记录.rows between 1 preceding and current row 窗口范围是分区中的前一行 当前行一共两行记录.
rows between current row and 1 following 窗口范围是分区中的当前行 后一行一共两行记录.
rows unbounded preceding 窗口范围是分区中的第一行到当前行.
rows between unbounded preceding and current row 窗口范围是分区中的第一行到当前行.
rows between current row and unbounded following 窗口范围是分区中的当前行到最后一行.
rows between unbounded preceding and unbounded following 窗口范围是当前分区中所有行.
14.7.5 累积分布
CUME_DIST() OVER (
PARTITION BY expr, ...
ORDER BY expr [ASC | DESC], ...
)
CUME_DIST()
# 累积分布
mysql> SELECT
-> name,
-> score,
-> ROW_NUMBER() OVER (ORDER BY score) row_num,
-> CUME_DIST() OVER (ORDER BY score) cume_dist_val
-> FROM
-> scores;
+----------+-------+---------+---------------+
| name | score | row_num | cume_dist_val |
+----------+-------+---------+---------------+
| Jones | 55 | 1 | 0.2 |
| Williams | 55 | 2 | 0.2 |
| Brown | 62 | 3 | 0.4 |
| Taylor | 62 | 4 | 0.4 |
| Thomas | 72 | 5 | 0.6 |
| Wilson | 72 | 6 | 0.6 |
| Smith | 81 | 7 | 0.7 |
| Davies | 84 | 8 | 0.8 |
| Evans | 87 | 9 | 0.9 |
| Johnson | 100 | 10 | 1 |
+----------+-------+---------+---------------+
10 rows in set (0.00 sec)
十五. 备份和还原
15.1 备份
需要注意的是
windows下Powershell导出的内容格式默认是UTF-16, 会导致异常.
逻辑/物理的差异
-
逻辑备份: 利用
mysqldump命令或其他方法, 将数据以数据库中的文件提取到文件中(就是一个大型的sql语句的文件/或者db格式的文件), 在恢复数据时, 就执行该SQL语句即可, 这里就会遇到导出的数据量太大时, 将数据恢复所花费的时间. -
物理备份: 故名思议, 将数据整体复制一份备份(将整个数据库关联的), 恢复时, 直接恢复, 而不需要执行
SQL的重新建立数据库, 重新放入数据的这花费时间的过程.
# mysqldump命令
# --all-databases, 备份所有的数据库
# --databases + 数据库名称, 备份指定的数据库
# 符号注意'\', 需要转为"/"
mysqldump -uroot -p --databases test_db > /all_test.sql
# 两种文件没什么区别
mysqldump -uroot -p --all-databases > /backup/mysqldump/all.db
| 参数名 | 缩写 | 含义 |
|---|---|---|
| --host | -h | 服务器IP地址 |
| --port | -P | 服务器端口号 |
| --user | -u | MySQL 用户名 |
| --pasword | -p | MySQL 密码 |
| --databases | 指定要备份的数据库 | |
| --all-databases | 备份mysql服务器上的所有数据库 | |
| --compact | 压缩模式 产生更少的输出 | |
| --comments | 添加注释信息 | |
| --complete-insert | 输出完成的插入语句 | |
| --lock-tables | 备份前 锁定所有数据库表 | |
| --no-create-db/--no-create-info | 禁止生成创建数据库语句 | |
| --force | 当出现错误时仍然继续备份操作 | |
| --default-character-set | 指定默认字符集 | |
| --add-locks | 备份数据库表时锁定数据库表 |
常见的备份方式对比:
| 备份方法 | 备份速度 | 恢复速度 | 便捷性 | 功能 | 使用场景 |
|---|---|---|---|---|---|
| 直接物理复制 | 快 | 快 | 一般, 灵活性低 | 弱 | 少量数据备份 |
mysqldump |
慢 | 慢 | 一般, 可无视存储引擎的差异 | 一般 | 中小型数据量的备份 |
xtrabackup |
较快 | 较快 | 实现innodb热备 对存储引擎有要求 |
强大 | 较大规模的备份 |
15.2 还原
mysqladmin -uroot -p create db_name
# 假如sql语句中包含自动创建db, 就不需要指定db
# 直接登录MySQL, 加载sql语句
mysql -uroot -p db_name < /backup/mysqldump/db_name.db
# 注: 在导入备份数据库前 db_name如果没有 是需要创建的; 而且与db_name.db中数据库名是一样的才可以导入.
mysql source命令主要用来倒入超大的sql文件
mysql > use db_name
mysql > source /backup/mysqldump/db_name.db
-- 执行SQL, 输入执行的结果到执行的文件中
mysql>source c:/test.sql > output.log
注意输入的路径符号使用的是反斜杠.
十六. 日期处理
时间的处理是一个相对麻烦而不讨好的事情.
- 跨时区
- 多种不同格式(不同时间的表示方式和时间戳)
- 间隔
- 细分时间段
- 星期天/节假日
16.1 获取时间
# 获取当前日期时间
select NOW(); # 2021-04-02 09:25:29
# 获取当前日期
SELECT CURDATE(); # 2021-04-02
# 获取当前时间
SELECT CURTIME(); # 09:26:10
# 对于时间2021-04-02 09:25:29 分别获取其年 月 日 时 分 秒
SELECT EXTRACT(YEAR FROM NOW()); # 2021
SELECT EXTRACT(MONTH FROM NOW()); # 4
SELECT EXTRACT(DAY FROM NOW()); # 2
SELECT EXTRACT(HOUR FROM NOW()); # 9
SELECT EXTRACT(MINUTE FROM NOW()); # 25
SELECT EXTRACT(SECOND FROM NOW()); # 29
# 或者从日期格式字符串中获取
SELECT EXTRACT(SECOND FROM '2021-04-02 10:37:14.123456'); # 14
16.2 日期增加 减少
# 注意 INTERVAL
# 时间减少1小时( 前一小时)
select date_sub(now(), INTERVAL 1 hour);
# 日期增加1天
select date_add(now(), INTERVAL 1 day);
支持时间间隔参数:
| Type 值 |
|---|
| MICROSECOND, 毫秒 |
| SECOND, 秒 |
| MINUTE, 分 |
| HOUR, 小时 |
| DAY, 天 |
| WEEK, 周 |
| MONTH, 月 |
| QUARTER, 季度 |
| YEAR, 年 |
| SECOND_MICROSECOND |
| MINUTE_MICROSECOND |
| MINUTE_SECOND |
| HOUR_MICROSECOND |
| HOUR_SECOND |
| HOUR_MINUTE |
| DAY_MICROSECOND |
| DAY_SECOND |
| DAY_MINUTE |
| DAY_HOUR |
| YEAR_MONTH |
16.3 日期格式化 字符串转日期
# 格式化参考:
select DATE_FORMAT(now(),'%Y-%m-%d %H:%i:%s');
# 只需要保留小时部分
select DATE_FORMAT(now(),'%Y-%m-%d %H:00:00');
#字符串转日期
select str_to_date('2021-04-02 10:37:14', '%Y-%m-%d %H:%i:%s'); # 2021-04-02 10:37:14
16.4 其他参考函数
以下较全的MySQL日期函数可做参考( 原文链接: https://blog.csdn.net/qinshijangshan/article/details/72874667)
-- MySQL日期时间处理函数
-- 当前日期: 2017-05-12( 突然发现今天512 是不是会拉防空警报)
SELECT NOW() FROM DUAL;-- 当前日期时间: 2017-05-12 11:41:47
-- 在MySQL里也存在和Oracle里类似的dual虚拟表: 官方声明纯粹是为了满足select ... from...这一习惯问题 mysql会忽略对该表的引用.
-- 那么MySQL中就不用DUAL了吧.
SELECT NOW();-- 当前日期时间: 2017-05-12 11:41:55
-- 除了 now() 函数能获得当前的日期时间外 MySQL 中还有下面的函数:
SELECT CURRENT_TIMESTAMP();-- 2017-05-15 10:19:31
SELECT CURRENT_TIMESTAMP;-- 2017-05-15 10:19:51
SELECT LOCALTIME();-- 2017-05-15 10:20:00
SELECT LOCALTIME;-- 2017-05-15 10:20:10
SELECT LOCALTIMESTAMP();-- 2017-05-15 10:20:21(v4.0.6)
SELECT LOCALTIMESTAMP;-- 2017-05-15 10:20:30(v4.0.6)
-- 这些日期时间函数 都等同于 now(). 鉴于 now() 函数简短易记 建议总是使用 now()来替代上面列出的函数.
SELECT SYSDATE();-- 当前日期时间: 2017-05-12 11:42:03
-- sysdate() 日期时间函数跟 now() 类似
-- 不同之处在于: now() 在执行开始时值就得到了;sysdate() 在函数执行时动态得到值.
-- 看下面的例子就明白了:
SELECT NOW(), SLEEP(3), NOW();
SELECT SYSDATE(), SLEEP(3), SYSDATE();
SELECT CURDATE();-- 当前日期: 2017-05-12
SELECT CURRENT_DATE();-- 当前日期: 等同于 CURDATE()
SELECT CURRENT_DATE;-- 当前日期: 等同于 CURDATE()
SELECT CURTIME();-- 当前时间: 11:42:47
SELECT CURRENT_TIME();-- 当前时间: 等同于 CURTIME()
SELECT CURRENT_TIME;-- 当前时间: 等同于 CURTIME()
-- 获得当前 UTC 日期时间函数
SELECT UTC_TIMESTAMP(), UTC_DATE(), UTC_TIME()
-- MySQL 获得当前时间戳函数: current_timestamp, current_timestamp()
SELECT CURRENT_TIMESTAMP, CURRENT_TIMESTAMP();-- 2017-05-15 10:32:21 | 2017-05-15 10:32:21
-- MySQL 日期时间 Extract( 选取) 函数
SET @dt = '2017-05-15 10:37:14.123456';
SELECT DATE(@dt);-- 获取日期: 2017-05-15
SELECT TIME('2017-05-15 10:37:14.123456');-- 获取时间: 10:37:14.123456
SELECT YEAR('2017-05-15 10:37:14.123456');-- 获取年份
SELECT MONTH('2017-05-15 10:37:14.123456');-- 获取月份
SELECT DAY('2017-05-15 10:37:14.123456');-- 获取日
SELECT HOUR('2017-05-15 10:37:14.123456');-- 获取时
SELECT MINUTE('2017-05-15 10:37:14.123456');-- 获取分
SELECT SECOND('2017-05-15 10:37:14.123456');-- 获取秒
SELECT MICROSECOND('2017-05-15 10:37:14.123456');-- 获取毫秒
SELECT QUARTER('2017-05-15 10:37:14.123456');-- 获取季度
SELECT WEEK('2017-05-15 10:37:14.123456');-- 20 (获取周)
SELECT WEEK('2017-05-15 10:37:14.123456', 7);-- ****** 测试此函数在MySQL5.6下无效
SELECT WEEKOFYEAR('2017-05-15 10:37:14.123456');-- 同week()
SELECT DAYOFYEAR('2017-05-15 10:37:14.123456');-- 135 (日期在年度中第几天)
SELECT DAYOFMONTH('2017-05-15 10:37:14.123456');-- 5 (日期在月度中第几天)
SELECT DAYOFWEEK('2017-05-15 10:37:14.123456');-- 2 (日期在周中第几天; 周日为第一天)
SELECT WEEKDAY('2017-05-15 10:37:14.123456');-- 0
SELECT WEEKDAY('2017-05-21 10:37:14.123456');-- 6(与dayofweek()都表示日期在周的第几天 只是参考标准不同 weekday()周一为第0天 周日为第6天)
SELECT YEARWEEK('2017-05-15 10:37:14.123456');-- 201720(年和周)
# 201720
SELECT EXTRACT(YEAR FROM '2017-05-15 10:37:14.123456');
SELECT EXTRACT(MONTH FROM '2017-05-15 10:37:14.123456');
SELECT EXTRACT(DAY FROM '2017-05-15 10:37:14.123456');
SELECT EXTRACT(HOUR FROM '2017-05-15 10:37:14.123456');
SELECT EXTRACT(MINUTE FROM '2017-05-15 10:37:14.123456');
SELECT EXTRACT(SECOND FROM '2017-05-15 10:37:14.123456');
SELECT EXTRACT(MICROSECOND FROM '2017-05-15 10:37:14.123456');
SELECT EXTRACT(QUARTER FROM '2017-05-15 10:37:14.123456');
SELECT EXTRACT(WEEK FROM '2017-05-15 10:37:14.123456');
SELECT EXTRACT(YEAR_MONTH FROM '2017-05-15 10:37:14.123456');
SELECT EXTRACT(DAY_HOUR FROM '2017-05-15 10:37:14.123456');
SELECT EXTRACT(DAY_MINUTE FROM '2017-05-15 10:37:14.123456');-- 151037(日时分)
SELECT EXTRACT(DAY_SECOND FROM '2017-05-15 10:37:14.123456');-- 15103714(日时分秒)
SELECT EXTRACT(DAY_MICROSECOND FROM '2017-05-15 10:37:14.123456');-- 15103714123456(日时分秒毫秒)
SELECT EXTRACT(HOUR_MINUTE FROM '2017-05-15 10:37:14.123456');-- 1037(时分)
SELECT EXTRACT(HOUR_SECOND FROM '2017-05-15 10:37:14.123456');-- 103714(时分秒)
SELECT EXTRACT(HOUR_MICROSECOND FROM '2017-05-15 10:37:14.123456');-- 103714123456(日时分秒毫秒)
SELECT EXTRACT(MINUTE_SECOND FROM '2017-05-15 10:37:14.123456');-- 3714(分秒)
SELECT EXTRACT(MINUTE_MICROSECOND FROM '2017-05-15 10:37:14.123456');-- 3714123456(分秒毫秒)
SELECT EXTRACT(SECOND_MICROSECOND FROM '2017-05-15 10:37:14.123456');-- 14123456(秒毫秒)
-- MySQL Extract() 函数除了没有date(),time() 的功能外 其他功能一应具全.
-- 并且还具有选取‘day_microsecond' 等功能.
-- 注意这里不是只选取 day 和 microsecond 而是从日期的 day 部分一直选取到 microsecond 部分.
SELECT DAYNAME('2017-05-15 10:37:14.123456');-- Monday(返回英文星期)
SELECT MONTHNAME('2017-05-15 10:37:14.123456');-- May(返回英文月份)
SELECT LAST_DAY('2016-02-01');-- 2016-02-29 (返回月份中最后一天)
SELECT LAST_DAY('2016-05-01');-- 2016-05-31
-- DATE_ADD(date,INTERVAL expr type) 从日期加上指定的时间间隔
-- type参数可参考: http://www.w3school.com.cn/sql/func_date_sub.asp
SELECT DATE_ADD('2017-05-15 10:37:14.123456',INTERVAL 1 YEAR);-- 表示: 2018-05-15 10:37:14.123456
SELECT DATE_ADD('2017-05-15 10:37:14.123456',INTERVAL 1 QUARTER);-- 表示: 2017-08-15 10:37:14.123456
SELECT DATE_ADD('2017-05-15 10:37:14.123456',INTERVAL 1 MONTH);-- 表示: 2017-06-15 10:37:14.123456
SELECT DATE_ADD('2017-05-15 10:37:14.123456',INTERVAL 1 WEEK);-- 表示: 2017-05-22 10:37:14.123456
SELECT DATE_ADD('2017-05-15 10:37:14.123456',INTERVAL 1 DAY);-- 表示: 2017-05-16 10:37:14.123456
SELECT DATE_ADD('2017-05-15 10:37:14.123456',INTERVAL 1 HOUR);-- 表示: 2017-05-15 11:37:14.123456
SELECT DATE_ADD('2017-05-15 10:37:14.123456',INTERVAL 1 MINUTE);-- 表示: 2017-05-15 10:38:14.123456
SELECT DATE_ADD('2017-05-15 10:37:14.123456',INTERVAL 1 SECOND);-- 表示: 2017-05-15 10:37:15.123456
SELECT DATE_ADD('2017-05-15 10:37:14.123456',INTERVAL 1 MICROSECOND);-- 表示: 2017-05-15 10:37:14.123457
-- DATE_SUB(date,INTERVAL expr type) 从日期减去指定的时间间隔
SELECT DATE_SUB('2017-05-15 10:37:14.123456',INTERVAL 1 YEAR);-- 表示: 2016-05-15 10:37:14.123456
SELECT DATE_SUB('2017-05-15 10:37:14.123456',INTERVAL 1 QUARTER);-- 表示: 2017-02-15 10:37:14.123456
SELECT DATE_SUB('2017-05-15 10:37:14.123456',INTERVAL 1 MONTH);-- 表示: 2017-04-15 10:37:14.123456
SELECT DATE_SUB('2017-05-15 10:37:14.123456',INTERVAL 1 WEEK);-- 表示: 2017-05-08 10:37:14.123456
SELECT DATE_SUB('2017-05-15 10:37:14.123456',INTERVAL 1 DAY);-- 表示: 2017-05-14 10:37:14.123456
SELECT DATE_SUB('2017-05-15 10:37:14.123456',INTERVAL 1 HOUR);-- 表示: 2017-05-15 09:37:14.123456
SELECT DATE_SUB('2017-05-15 10:37:14.123456',INTERVAL 1 MINUTE);-- 表示: 2017-05-15 10:36:14.123456
SELECT DATE_SUB('2017-05-15 10:37:14.123456',INTERVAL 1 SECOND);-- 表示: 2017-05-15 10:37:13.123456
SELECT DATE_SUB('2017-05-15 10:37:14.123456',INTERVAL 1 MICROSECOND);-- 表示: 2017-05-15 10:37:14.123455
-- 经特殊日期测试 DATE_SUB(date,INTERVAL expr type)可放心使用
SELECT DATE_SUB(CURDATE(),INTERVAL 1 DAY);-- 前一天: 2017-05-11
SELECT DATE_SUB(CURDATE(),INTERVAL -1 DAY);-- 后一天: 2017-05-13
SELECT DATE_SUB(CURDATE(),INTERVAL 1 MONTH);-- 一个月前日期: 2017-04-12
SELECT DATE_SUB(CURDATE(),INTERVAL -1 MONTH);-- 一个月后日期: 2017-06-12
SELECT DATE_SUB(CURDATE(),INTERVAL 1 YEAR);-- 一年前日期: 2016-05-12
SELECT DATE_SUB(CURDATE(),INTERVAL -1 YEAR);-- 一年后日期: 20178-06-12
-- MySQL date_sub() 日期时间函数 和 date_add() 用法一致 并且可以用INTERNAL -1 xxx的形式互换使用;
-- 另外 MySQL 中还有两个函数 subdate(), subtime() 建议 用 date_sub() 来替代.
-- MySQL 另类日期函数: period_add(P,N), period_diff(P1,P2)
-- 函数参数" P" 的格式为" YYYYMM" 或者 " YYMM" 第二个参数" N" 表示增加或减去 N month( 月) .
-- MySQL period_add(P,N): 日期加/减去N月.
SELECT PERIOD_ADD(201705,2), PERIOD_ADD(201705,-2);-- 201707 20170503
-- period_diff(P1,P2): 日期 P1-P2 返回 N 个月.
SELECT PERIOD_DIFF(201706, 201703);--
-- datediff(date1,date2): 两个日期相减 date1 - date2 返回天数
SELECT DATEDIFF('2017-06-05','2017-05-29');-- 7
-- TIMEDIFF(time1,time2): 两个日期相减 time1 - time2 返回 TIME 差值
SELECT TIMEDIFF('2017-06-05 19:28:37', '2017-06-05 17:00:00');-- 02:28:37
-- MySQL日期转换函数
SELECT TIME_TO_SEC('01:00:05'); -- 3605
SELECT SEC_TO_TIME(3605);-- 01:00:05
-- MySQL ( 日期 天数) 转换函数: to_days(date), from_days(days)
SELECT TO_DAYS('0000-00-00'); -- NULL
SELECT TO_DAYS('2017-06-05'); -- 736850
SELECT FROM_DAYS(0); -- '0000-00-00'
SELECT FROM_DAYS(736850); -- '2017-06-05'
-- MySQL Str to Date ( 字符串转换为日期) 函数: str_to_date(str, format)
SELECT STR_TO_DATE('06.05.2017 19:40:30', '%m.%d.%Y %H:%i:%s');-- 2017-06-05 19:40:30
SELECT STR_TO_DATE('06/05/2017', '%m/%d/%Y'); -- 2017-06-05
SELECT STR_TO_DATE('2017/12/3','%Y/%m/%d') -- 2017-12-03
SELECT STR_TO_DATE('20:09:30', '%h:%i:%s') -- NULL(超过12时的小时用小写h 得到的结果为NULL)
-- 日期时间格式化
SELECT DATE_FORMAT('2017-05-12 17:03:51', '%Y年%m月%d日 %H时%i分%s秒');-- 2017年05月12日 17时03分51秒(具体需要什么格式的数据根据实际情况来;小写h为12小时制;)
SELECT TIME_FORMAT('2017-05-12 17:03:51', '%Y年%m月%d日 %H时%i分%s秒');-- 0000年00月00日 17时03分51秒(time_format()只能用于时间的格式化)
-- STR_TO_DATE()和DATE_FORMATE()为互逆操作
-- MySQL 获得国家地区时间格式函数: get_format()
-- MySQL get_format() 语法: get_format(date|time|datetime, 'eur'|'usa'|'jis'|'iso'|'internal'
-- MySQL get_format() 用法的全部示例:
SELECT GET_FORMAT(DATE,'usa'); -- '%m.%d.%Y'
SELECT GET_FORMAT(DATE,'jis'); -- '%Y-%m-%d'
SELECT GET_FORMAT(DATE,'iso'); -- '%Y-%m-%d'
SELECT GET_FORMAT(DATE,'eur'); -- '%d.%m.%Y'
SELECT GET_FORMAT(DATE,'internal'); -- '%Y%m%d'
SELECT GET_FORMAT(DATETIME,'usa'); -- '%Y-%m-%d %H.%i.%s'
SELECT GET_FORMAT(DATETIME,'jis'); -- '%Y-%m-%d %H:%i:%s'
SELECT GET_FORMAT(DATETIME,'iso'); -- '%Y-%m-%d %H:%i:%s'
SELECT GET_FORMAT(DATETIME,'eur'); -- '%Y-%m-%d %H.%i.%s'
SELECT GET_FORMAT(DATETIME,'internal'); -- '%Y%m%d%H%i%s'
SELECT GET_FORMAT(TIME,'usa'); -- '%h:%i:%s %p'
SELECT GET_FORMAT(TIME,'jis'); -- '%H:%i:%s'
SELECT GET_FORMAT(TIME,'iso'); -- '%H:%i:%s'
SELECT GET_FORMAT(TIME,'eur'); -- '%H.%i.%s'
SELECT GET_FORMAT(TIME,'internal'); -- '%H%i%s'
-- MySQL 拼凑日期 时间函数: makdedate(year,dayofyear), maketime(hour,minute,second)
SELECT MAKEDATE(2017,31); -- '2017-01-31'
SELECT MAKEDATE(2017,32); -- '2017-02-01'
SELECT MAKETIME(19,52,35); -- '19:52:35'
-- MySQL 时区( timezone) 转换函数: convert_tz(dt,from_tz,to_tz)
SELECT CONVERT_TZ('2017-06-05 19:54:12', '+08:00', '+00:00'); -- 2017-06-05 11:54:12
-- MySQL ( Unix 时间戳 日期) 转换函数
-- unix_timestamp(), unix_timestamp(date), from_unixtime(unix_timestamp), from_unixtime(unix_timestamp,format)
-- 将具体时间时间转为timestamp
SELECT UNIX_TIMESTAMP();-- 当前时间的时间戳: 1494815779
SELECT UNIX_TIMESTAMP('2017-05-15');-- 指定日期的时间戳: 1494777600
SELECT UNIX_TIMESTAMP('2017-05-15 10:37:14');-- 指定日期时间的时间戳: 1494815834
-- 将时间戳转为具体时间
SELECT FROM_UNIXTIME(1494815834);-- 2017-05-15 10:37:14
SELECT FROM_UNIXTIME(1494815834, '%Y年%m月%d日 %h时%分:%s秒');-- 获取时间戳对应的格式化日期时间
-- MySQL 时间戳( timestamp) 转换 增 减函数
SELECT TIMESTAMP('2017-05-15');-- 2017-05-15 00:00:00
SELECT TIMESTAMP('2017-05-15 08:12:25', '01:01:01');-- 2017-05-15 09:13:26
SELECT DATE_ADD('2017-05-15 08:12:25', INTERVAL 1 DAY);-- 2017-05-16 08:12:25
SELECT TIMESTAMPADD(DAY, 1, '2017-05-15 08:12:25');-- 2017-05-16 08:12:25; MySQL timestampadd() 函数类似于 date_add().
SELECT TIMESTAMPDIFF(YEAR, '2017-06-01', '2016-05-15');-- -1
SELECT TIMESTAMPDIFF(MONTH, '2017-06-01', '2016-06-15');-- -11
SELECT TIMESTAMPDIFF(DAY, '2017-06-01', '2016-06-15');-- -351
SELECT TIMESTAMPDIFF(HOUR, '2017-06-01 08:12:25', '2016-06-15 00:00:00');-- -8432
SELECT TIMESTAMPDIFF(MINUTE, '2017-06-01 08:12:25', '2016-06-15 00:00:00');-- -505932
SELECT TIMESTAMPDIFF(SECOND, '2017-06-01 08:12:25', '2016-06-15 00:00:00');-- -30355945
十七. 外部交互
17.1 Python
# 假如没有安装
# 安装python/connector
pip install mysql-connector-python
import mysql_connector as conn
# 数据库的连接配置
configs = {
"user": "your_id",
"host": "localhost",
"passwd": "your_pw",
"port": 3306,
"database": "your_db"
}
my_sql = conn.connect(**configs)
# 通过pandas读取数据
my_data = pd.read_sql("select * from table limit 10;", my_sql)
# 游标的方式
cursor = my_sql.cursor()
# 读取内容
cursor.execute("select * from table limit 10;")
# 读取内容后, 记得清空游标的数据
cursor.fetchall()
my_sql.free_result()
# 退出mysql
cursor.close()
my_sql.cmd_quit()
17.2 PowerBI
Power BI can connect to data by using existing connectors and generic data sources, like ODBC, OData, OLE DB, Web, CSV, XML, and JSON. Or, developers can enable new data sources with custom data extensions called custom connectors. Some custom connectors are certified and distributed by Microsoft as certified connectors.
mysql和power bi之间的连接需要.net版本的connector支持, 可以通过mysql installer管理器, 增加这个组件.

数据可以直接在powerbi上预览, 也可以在连接时, 直接从SQL语句中返回结果.

另一种方式就是通过传统的ODBC进行连接

相关配置见下面的VBA部分
17.3 VBA
17.3.1 环境
Office 2016, 32bit(注意这里的版本问题)MySQL 8.x
安装教程略过, 但是在安装驱动时需要注意安装对应的驱动和安装的office版本相对应, 32位的office安装32为, 64位office安装64位.
(注: 建议使用MySQL installer来安装和管理MySQL, 方便配置和调整.)

17.3.2 VBA和MySQL的连接主要依赖组件
VBA端: 依赖于Microsoft ActiveX Data Object
(注: 或者可以补充勾选Microsoft ActiveX Data Objects Recordset 2.8 Library)

中间件: ODBC(Open Database Connectivity)
17.3.3 配置连接
在Windows中需要配置

注意配置需要区分开32位和64位和安装的office, ODBC一致)
打开后添加驱动

选择unicode即可
配置数据库的连接

填写完参数, 务必测试连接是否可用.
VBA连接测试
Option Explicit
Sub test()
Dim con As New ADODB.Connection
con.ConnectionString = "Driver={MySQL ODBC 8.0 Unicode Driver};Server=localhost;DB=test_db;UID=root;PWD=123456;OPTION=3;"
con.Open
MsgBox ("connect" & vbCrLf & "mysql" & con.State & vbCrLf & "mysql version" & con.Version)
con.Close
Set con = Nothing
End Sub
参数解析
"Driver={MySQL ODBC 8.0 Unicode Driver};Server=localhost;DB=test_db;UID=root;PWD=123456;OPTION=3;"
Driver: 驱动名称
Server: 数据库地址
DB: 需要连接的数据库具体名称
UID: 用户名称
PWD: 登录密码
OPTION: 取自官方文档, 和驱动的工作方式有关, 但是这个参数=3没有查到具体的含义, 在文档中没有提及3的含义
17.3.4 在局域网中访问
- 确保Windows防火墙(假如处于开启状态)的进站规则当中包含MySQL的端口处于开放的状态(默认端口
3306/33060), 使用前可以先ping对应的主机是否可用. - 配置数据库的权限, 允许局域网访问.
17.4 文本数据交互
相关的参数, 同样适用诸在python pandas的文本内容的读取上.
17.4.1 导入
# csv / txt / 或者其他制表符的变种文件
# 需要注意的细节
# 字符编码
# 错误处理
# 重复数据处理
# 字符的转义
# 字符的连带符号, 例如逗号分隔符下的","逗号需要保留下来
LOAD DATA
[LOW_PRIORITY | CONCURRENT] [LOCAL] | 锁的影响, low, 在其他线程执行完, 在执行, con, 同时执行;
INFILE 'file_name' | 文件
[REPLACE | IGNORE] | 处理冲突数据;
INTO TABLE tbl_name | 插入的数据表
[PARTITION (partition_name [, partition_name] ...)] | 分区相关(假如表采用了分区)
[CHARACTER SET charset_name] | 编码类型
[{FIELDS | COLUMNS} | 字段相关, 任意指定一个参数即可, 等价的
[TERMINATED BY 'string'] | 分隔符
[[OPTIONALLY] ENCLOSED BY 'char'] | 字段值由什么符号包围, 例如 需要表示 "abc", 包含符号在内
[ESCAPED BY 'char'] | 转义字符
]
[LINES | 行相关
[STARTING BY 'string'] |
[TERMINATED BY 'string'] | 分割符号, 即每一行是使用什么换行符
]
[IGNORE number {LINES | ROWS}] | 跳过前几行, 从1开始(一般为表头, 就跳过1)
[(col_name_or_user_var | 字段名称
[, col_name_or_user_var] ...)]
[SET col_name={expr | DEFAULT} | 设置字段名称
[, col_name={expr | DEFAULT}] ...]
create table test_c (
user_name varchar(16) not null,
piece smallint unsigned,
price float,
pay_amount float,
goods_category varchar(16),
pay_time timestamp
);
mysql> load data infile 'C:/Users/Lian/Desktop/user_trade.csv'
-> into table test_c
-> fields terminated by ','
-> lines terminated by '\n'
-> ignore 1 lines
-> (`user_name`,`piece`,`price`, `pay_amount`, `goods_category`, `pay_time`);
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statement
# 这个参数能临时允许数据导入? 没测试
mysql> show global variables like 'local_infile';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| local_infile | OFF |
+---------------+-------+
1 row in set (0.00 sec)
mysql> show variables like '%secure%';
+--------------------------+-----------------------+
| Variable_name | Value |
+--------------------------+-----------------------+
| require_secure_transport | OFF |
| secure_file_priv | /var/lib/mysql-files/ |
+--------------------------+-----------------------+
2 rows in set (0.00 sec)
## secure_file_priv 是个只读变量, 修改必须在配置文件
# 指定可以从特定的路径,导入数据
# linux, cnf
# windows, ini
# 这里是在linux
# 先暂停服务
sudo service mysql stop
# 进入配置文件
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf
# 由于文件是存放在主机上的, linux在wsl上
# 在配置文件上, 添加一个路径
# secure_file_priv=/mnt/c/Users/Lian/Desktop/
# 假如设置为secure_file_priv = '', 理论上这是表示任意路径下的文件的导入
# 访问时会加上 /var/lib/mysql-files/ + 传入的路径
# 重启服务
sudo service mysql start
# 添加数据即可, 注意文件的编码类型, 这里表默认utf-8, 文件也需要时utf-8
load data infile '/mnt/c/Users/Lian/Desktop/user_trade.csv'
into table test_c
fields terminated by ','
lines terminated by '\n'
ignore 1 lines
(`user_name`, `piece`, `price`, `pay_amount`, `goods_category`, `pay_time`);
# 注意时间
# 2020-01-01
# excel会将时间转为如下, 在转为csv文件时
# 1/1/2020
# 手动复制时间重新覆盖csv文件上的数据即可.
# 导入速度非常快
mysql> select * from test_c limit 10;
+-----------+-------+-------+------------+----------------+---------------------+
| user_name | piece | price | pay_amount | goods_category | pay_time |
+-----------+-------+-------+------------+----------------+---------------------+
| Allison | 4 | 688.8 | 2755.2 | shoes | 2018-01-07 00:00:00 |
| Francis | 83 | 1.1 | 91.3 | food | 2018-01-07 00:00:00 |
| DEMI | 26 | 2222 | 57772 | electronics | 2018-01-12 00:00:00 |
| DEMI | 39 | 200 | 7800 | clothes | 2018-01-12 00:00:00 |
| Enid | 15 | 6666 | 99990 | computer | 2018-01-12 00:00:00 |
| Heidi | 93 | 688.8 | 64058.4 | shoes | 2018-01-12 00:00:00 |
| Jackson | 43 | 200 | 8600 | clothes | 2018-01-12 00:00:00 |
| Carroll | 1 | 688.8 | 688.8 | shoes | 2018-01-22 00:00:00 |
| Carlos | 52 | 8.9 | 462.8 | book | 2018-02-05 00:00:00 |
| Aviva | 74 | 2222 | 164428 | electronics | 2018-02-05 00:00:00 |
+-----------+-------+-------+------------+----------------+---------------------+
10 rows in set (0.00 sec)
17.4.2 导出
# 参数设置和导入一样
# 只是数据的导入导出差异
# 安全设置也一样
# 默认导出数据不包含表头
with tmp as (select 'id', 'name' union select id, name from test_e)
SELECT * FROM tmp
INTO OUTFILE "/mnt/c/Users/Lian/Desktop/abc.csv"
FIELDS TERMINATED BY "," ENCLOSED BY '"' lines terminated by '\n';
# with tmp as (select 'id', 'name' union select id, name from test_e)
# 设置表头
mysql> select 'id', 'name' union select id, name from test_e;
+----+------+
| id | name |
+----+------+
| id | name |
| 1 | tom |
| 2 | xx |
| 3 | jimi |
| 4 | tome |
| 5 | al |
| 6 | jamy |
+----+------+
7 rows in set (0.00 sec)
十八. 使用与实践
18.1 数据库设计范式
设计范式只是理想状态下的要求, 未必是最佳实践(如: 表字段拆分过细, 对于多表的关联查询或者是数据的获取是否造成不必要的麻烦? 数据的更新, 插入新数据等是否存在问题等).
- 第一范式: 原子性, 每个字段的值不能再分.
- 第二范式: 唯一性, 表内每行数据必须描述同一业务属性的数据.
- 第三范式: 独立性, 表中每个非主键字段之间不能存在依赖性.
- 巴斯范式(
BCNF): 主键字段独立性, 联合主键字段之间不能存在依赖性. - 第四范式: 表中字段不能存在多值依赖关系.
- 第五范式: 表中字段的数据之间不能存在连接依赖关系.
- 域键范式: 试图研究出一个库表设计时的终极完美范式.
以下介绍前三大范式:
18.1.1 1NF
无比需要实现的一个规范.
相对容易理解, 作为关系型数据库的基础要求规范. 看似简单, 但是也最为核心的一环, 没有这一环, 后续的其他的设计范式皆是空中楼阁, 镜中花水中月.
- 每个列必须有一个唯一的名称.
- 行和列的次序无关紧要.
- 不允许包含相同值的两行.
- 每一列都必须包含一个单值 (一个列不能保存多个数据值).
- 列不能包含重复的组.
简而言之, 其中的关键在于数据的拆分.
例如:
| id | address |
|---|---|
| 1 | A省B市C区D街道E路F楼G号房 |
| id | province | city | district | street | detail |
|---|---|---|---|---|---|
| 1 | A省 | B市 | C区 | D街道 | E路F楼G号房 |
数据被拆分到原子层级, 不可再分为止, 这样做的好处是显而易见的.
以数据检索为例: 将可以轻松定位不同层级的数据. 将字符串转换为对应的区域编码, 使用整数作为字符串, 形成一一对应的关系, 数据的检索将变得更快.
18.1.2 2NF
符合1NF的前提下, 满足以下要求:
- 表中必须存在业务
主键, 并且非主键全部依赖于业务主键
| name | id | address |
|---|---|---|
| alex | 1 | us |
| alex | 2 | china |
name显然无法作为主键, 因为name可能存在重复值.
| id | name | country_name | country_code | college | course | grade |
|---|---|---|---|---|---|---|
| 1 | alex | us | 1001 | cs | math | a |
| 1 | alex | us | 1001 | cs | enconomy | c |
| 2 | tom | cn | 1002 | pr | english | a |
| 3 | alex | en | 1003 | cs | math | a |
每个id不同的course的情况下, 就出现数据需要重复, 造成数据冗余的问题.
| id | name | country_name | country_code | college |
|---|---|---|---|---|
| 1 | alex | us | 1001 | cs |
| 2 | tom | cn | 1002 | pr |
| 3 | alex | en | 1003 | cs |
| id | course | grade |
|---|---|---|
| 1 | math | a |
| 1 | enconomy | c |
| 2 | english | a |
| 3 | math | a |
简而言之, 主键, 和每张表尽量实现自身的独立性.
18.1.3 3NF
满足2NF要求的前提下, 满足以下要求
- 不包含传递相关性, 即, 一个非键值字段的值依赖于另一个非键值字段的值, 不含冗余数据.
| id | name | country_code | college |
|---|---|---|---|
| 1 | alex | 1001 | cs |
| 2 | tom | 1002 | pr |
| 3 | alex | 1003 | cs |
| id | course | grade |
|---|---|---|
| 1 | math | a |
| 1 | enconomy | c |
| 2 | english | a |
| 3 | math | a |
| country_code | country_name |
|---|---|
| 1001 | us |
| 1002 | cn |
| 1003 | en |
简而言之, 就决定某字段值的必须是主键.
18.2 业务实践
- 浮点数的处理:
A方案: 为了保持精度使用decimal类型来保存;B方案: 在前端将数据转为整数后, 例如乘以1000/10000, 相对于double类型的, 整数型字段占用的空间更小. - 前后端操作的分离: 如
排序结果输出(排序是典型的CPU密集型的操作), 完全可以放在前端执行, 而不一定需要在服务端执行完后才输出结果, 考虑到数据库所处的服务器端(后端)的CPU资源相对宝贵. - 对于需要对表格结果和内容发生较大改变的操作, 如
alter语句, 需要控制特定时间段的执行, 减少数据库操作对业务层的影响. - 尽量保持个字段非
null约束(null的存在存在很多隐形问题, 如索引失效, 窗口函数排序等). join表格的数据, 尽量少于3个(阿里巴巴Java手册1.6提及的要求).- 应该禁止
跨数据库的join. - 核心表需要有
时间戳字段用于追踪数据的变化, 方便问题出现的回溯. - 建表时的字段需要
comment, 以便于快速确定字段的含义. - 有效控制字段的数据类型, 例如人的
年龄, 很显然tinyint unsigned(0 - 255)完全满足需求, 就不必要直接使用int, 减少资源的占用. - 减少非索引的SQL语句的使用, 如
like等可能导致的索引失效, 对于执行效率底下的SQL语句, 应当explain检查执行的细节. - 数据是否需要执行真实的删除操作, 还是使用删除标记即可(增加一个字段标注当前的行的使用状态)(减少数据可能误删的情况).(或者是在数据库处于非服务状态集中进行删除和表的优化)
- 数据库再服务状态避免进行表结构的变化的操作.
18.3 小表驱动大表?
前提, 小表, 大表, 即在数据检索中, 涉及到多个表, 表之间的数据差异较大.
所谓大小表驱动大表, 主要环节在于减少循环的次数.
for a in range(100):
... # do something
# 将长耗时放置在外层的循环
for b in range(100000000):
# 假设某个耗时的操作在这个循环执行, 显然是很慢的
... # do something
主要涉及 exists, in以及join.
delimiter $$
CREATE PROCEDURE rand_test_a_data (in i_many int)
BEGIN
DECLARE ic int DEFAULT 0;
truncate table test_a;
START TRANSACTION;
REPEAT
insert into test_a (id, col) VALUES (floor(rand() * 100000), LEFT ( concat(rand() * 10000000000, 'ajkshxm' ), 18 ));
set ic = ic + 1;
UNTIL
ic = i_many
END REPEAT;
COMMIT;
end $$
delimiter ;
使用上述的两个存储过程, test_tbale 表(大表), 写入1,000,000行的随机数据, 分别测试在test_a, 10, 100, 1,000, 50,000函数的数据, 按照查找到的资料基本介绍进行测试.
explain analyze select * from test_table where col in (select col from test_a);
explain analyze select * from test_table where exists (select 1 from test_a where test_a.col = test_table.col);
上述两条语句, 基本没有测试出任何的差别(可以显著看到时间差异的水平).
join中的差异
创建test_a, 随机插入1000000万行的数据
创建test_b, 随机插入10000行的数据
mysql> select a.* from test_b b join test_a a on a.idx = b.idx;
90 rows in set (0.45 sec)(多次测试)
mysql> select a.* from test_a a join test_b b on a.idx = b.idx;
90 rows in set (0.47 sec) (多次测试)
还是相对明显的, 速度的差异, 作为驱动表的是小表, 那么在速度上是优于大表作为驱动.
18.4 术语
18.4.1 回表
相关内容见另一篇文章.
查询到信息对这个词的介绍相当混乱, 各种文章都是相互抄袭, 不管对错.
主要涉及
- 索引的类型, 聚簇索引(
Clustered Index), 二级索引(Secondary Index)(辅助索引), 具体见上述的索引章节. B Tree+- 联合索引
所谓的回表, 是否可以简单理解, 查询获取的数据不是执行一次, 即检索到A然后在基础查找B?
explain select id from test_d where id =3;这个语句相对明确, 数据的获取是不需要从表获取的, 因为索引即数据, 返回找到的索引即可.
# 不同情况下, Extra展示的信息
mysql> desc test_d;
+---------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+-------------+------+-----+---------+-------+
| id | int | NO | PRI | NULL | |
| name | char(4) | YES | MUL | NULL | |
| address | varchar(10) | YES | | NULL | |
+---------+-------------+------+-----+---------+-------+
3 rows in set (0.01 sec)
mysql> insert into test_d values (1, 'tom', 'abc'), (2, 'alex', 'abc'), (3, 'tom', 'bb'), (4, 'jam','csa');
Query OK, 4 rows affected (0.01 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> select * from test_d;
+----+------+---------+
| id | name | address |
+----+------+---------+
| 1 | tom | abc |
| 2 | alex | abc |
| 3 | tom | bb |
| 4 | jam | csa |
+----+------+---------+
4 rows in set (0.00 sec)
# 这种情况?
mysql> explain select * from test_d where id = 3;
+----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | test_d | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
# 这里和下面的语句的差异?
mysql> explain select id, name from test_d where id = 3;
+----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | test_d | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
# 注意和上面的语句的差异
mysql> explain select id, name from test_d where name = 'tom';
+----+-------------+--------+------------+------+---------------+------------+---------+-------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------------+---------+-------+------+----------+--------------------------+
| 1 | SIMPLE | test_d | NULL | ref | index_name | index_name | 17 | const | 2 | 100.00 | Using where; Using index |
+----+-------------+--------+------------+------+---------------+------------+---------+-------+------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select id from test_d where name = 'tom';
+----+-------------+--------+------------+------+---------------+------------+---------+-------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------------+---------+-------+------+----------+--------------------------+
| 1 | SIMPLE | test_d | NULL | ref | index_name | index_name | 17 | const | 2 | 100.00 | Using where; Using index |
+----+-------------+--------+------------+------+---------------+------------+---------+-------+------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select id from test_d where id =3;
+----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | test_d | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | Using index |
+----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
mysql> explain select id, name, address from test_d where id =3;
+----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | test_d | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
# 使用distinct
mysql> explain select distinct name from test_d;
+----+-------------+--------+------------+-------+---------------+------------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+------------+---------+------+------+----------+-------------+
| 1 | SIMPLE | test_d | NULL | index | index_name | index_name | 17 | NULL | 4 | 100.00 | Using index |
+----+-------------+--------+------------+-------+---------------+------------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
# 在非索引的列执行
mysql> explain select distinct address from test_d;
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra
|
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-----------------+
| 1 | SIMPLE | test_d | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | Using temporary |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-----------------+
1 row in set, 1 warning (0.00 sec)
- using index
- using where
- using temporary
- null
- ...
针对上述信息的官方文档解析.
由于内容较多, 这里不一一详述, 这里着重注意using index的情形
The column information is retrieved from the table using only information in the index tree without having to do an additional seek to read the actual row. This strategy can be used when the query uses only columns that are part of a single index.
可以认为显示为using index时, 数据的获取不需要再表中查找, 而是直接返回索引上的信息?
For
InnoDBtables that have a user-defined clustered index, that index can be used even whenUsing indexis absent from theExtracolumn. This is the case iftypeisindexandkeyisPRIMARY.对于具有用户定义的聚集索引的
InnoDB表, 即使在Extra列中没有Using索引时, 也可以使用该索引. 如果type是index而key是PRIMARY就会出现这种情况.Information about any covering indexes used is shown for
EXPLAIN FORMAT=TRADITIONALandEXPLAIN FORMAT=JSON. Beginning with MySQL 8.0.27, it is also shown forEXPLAIN FORMAT=TREE.
