一. 前言
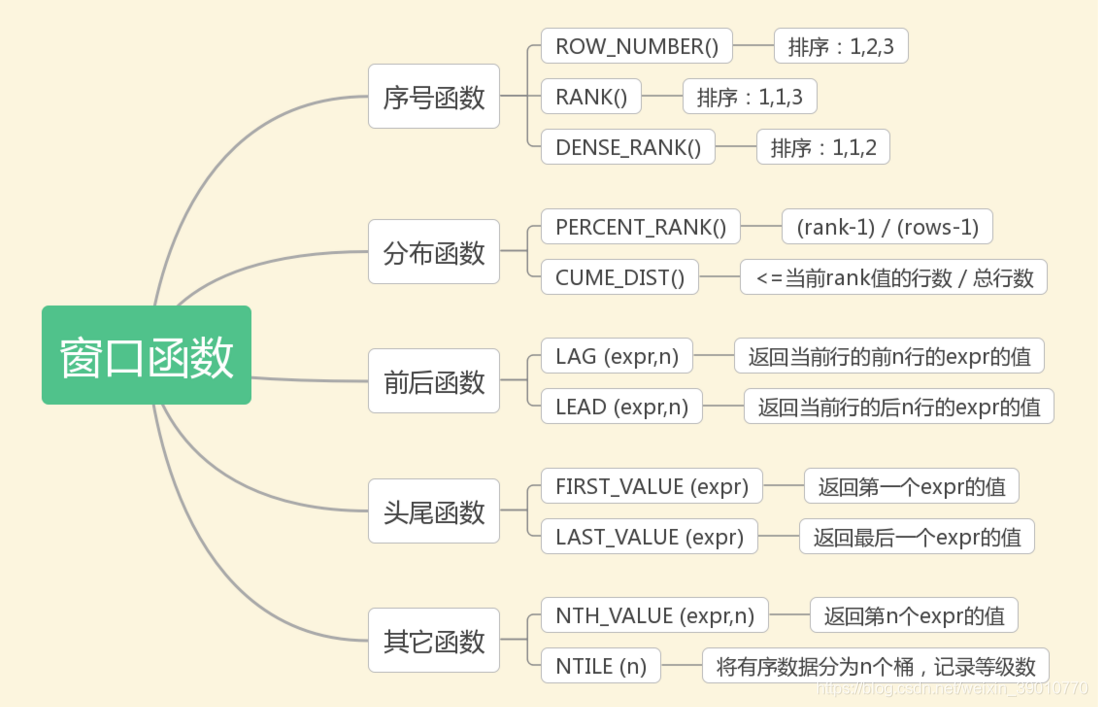
窗口函数(window function), 也称作OLAP, Online Analytical Processing,实时分析处理.
They can help boost query performance as an alternative to achieving the same result using more complex non-OLAP SQL code.
简而言之, 窗口函数大大强化了MySQL在数据分析上的能力, 通过窗口函数可以以相对简单的方式实现较为复杂的常态化数据输出, 例如经典的多层级汇总, topN问题, 多个区间之间得运算等.
以下内容, 先以简单的例子展示窗口函数的使用, 后使用相对复杂的内容来对窗口函数进行较深入的应用.
由于是在8.0后才增加的新特性, 搜索引擎/相关书籍提供的介绍较为简单和粗略, 相关参考主要以官方文档为主.
| Name | Description |
|---|---|
CUME_DIST() |
Cumulative distribution value |
DENSE_RANK() |
Rank of current row within its partition, without gaps |
FIRST_VALUE() |
Value of argument from first row of window frame |
LAG() |
Value of argument from row lagging current row within partition |
LAST_VALUE() |
Value of argument from last row of window frame |
LEAD() |
Value of argument from row leading current row within partition |
NTH_VALUE() |
Value of argument from N-th row of window frame |
NTILE() |
Bucket number of current row within its partition. |
PERCENT_RANK() |
Percentage rank value |
RANK() |
Rank of current row within its partition, with gaps |
ROW_NUMBER() |
Number of current row within its partition |
- 语法:
SELECT
val,
ROW_NUMBER() OVER (ORDER BY val) AS 'row_number',
RANK() OVER (ORDER BY val) AS 'rank',
DENSE_RANK() OVER (ORDER BY val) AS 'dense_rank'
FROM numbers;
# 等价
SELECT
val,
ROW_NUMBER() OVER w AS 'row_number',
RANK() OVER w AS 'rank',
DENSE_RANK() OVER w AS 'dense_rank'
FROM numbers
WINDOW w AS (ORDER BY val);
在理解窗口函数的时候, 需要有一个认知框架, 即在MySQL中对数据运算可能遇到的操作
- 区间运算, 对某个区域执行
- 横向运算(列之间的运算)
- 纵向运算(行之间的运算)
- 行转置为列进行运算(行与行之间进行, 将数据转为列)
- 混合执行上述的情形(例如行的数据转置为列, 在行之间进行区间运算...).
MySQL supports window functions that, for each row from a query, perform a calculation using rows related to that row.
官方文档对于窗口函数的使用的介绍: 解决行之间的运算.
一个"简单"的要求, 对行之间的数据进行减法的操作示例(在没有引入窗口函数时的操作):
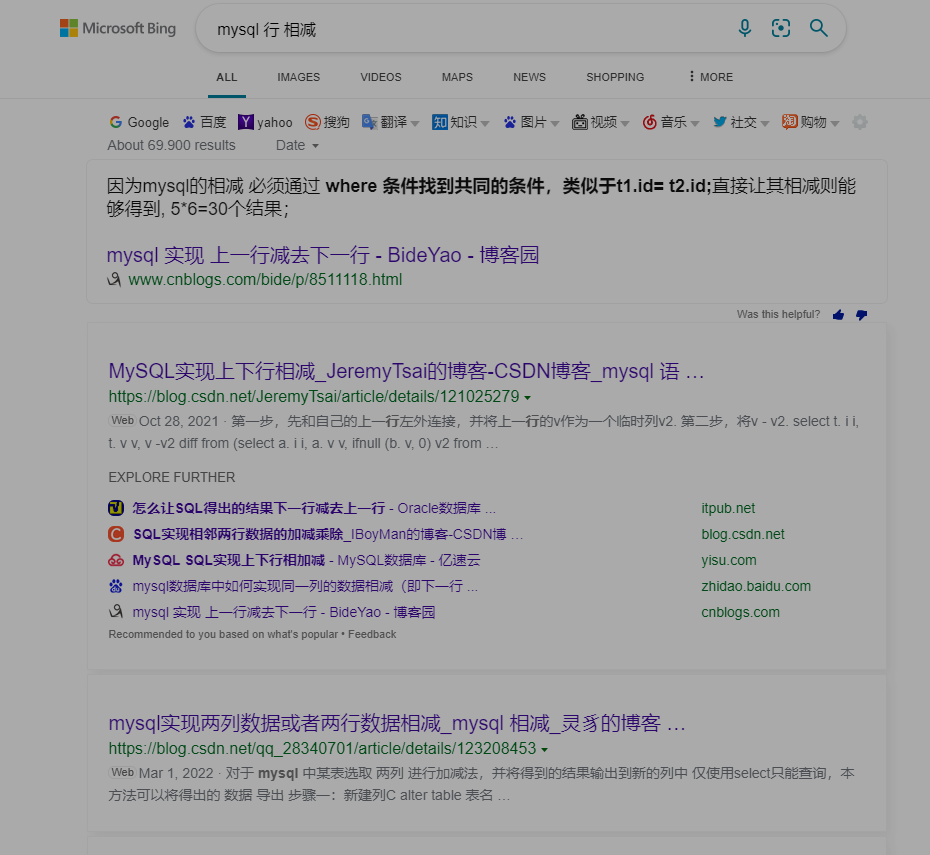
+--------+------------+------------+--------+------------+
| emp_no | first_name | hire_date | salary | to_date |
+--------+------------+------------+--------+------------+
| 10001 | Georgi | 2001-06-22 | 85097 | 2002-06-22 | # 这两行数据相减
| 10001 | Georgi | 2001-06-22 | 88958 | 9999-01-01 | #
| 10002 | Bezalel | 1999-08-03 | 72527 | 2000-08-02 | # 当emp_no出现次数等于2
+--------+------------+------------+--------+------------+
# 这种看似很简单的运算操作, 在传统方式的角度来看, 其实现是相对困难的
# 可能需要多次的join, 或者是引入临时的变量
在没有窗口函数时, 进行复杂的操作, 如多层级的汇总操作, 需要引入大量的临时表, 甚至是加入辅助变量进行操作, 这使得MySQL语句的可阅读性变得非常差, 在性能上可能也是相对较差的, 窗口函数很大程度解决了这些弊端.
简易搭配with一起使用
# 让代码逻辑更为清晰
# 多余需要聚合大量的表(临时表), with的更衣分清楚层次
WITH
cte1 AS (SELECT a, b FROM table1),
cte2 AS (SELECT c, d FROM table2)
SELECT b, d FROM cte1 JOIN cte2
WHERE cte1.a = cte2.c;
1.1 OLAP

The
GROUP BYclause permits aWITH ROLLUPmodifier that causes summary output to include extra rows that represent higher-level (that is, super-aggregate) summary operations.ROLLUPthus enables you to answer questions at multiple levels of analysis with a single query. For example,ROLLUPcan be used to provide support for OLAP (Online Analytical Processing) operations.
- 参考链接: 什么是OLAP?主流八大开源OLAP技术架构对比
1.2 示例
# 仅作演示, 未优化的语句
WITH a AS ( SELECT *, IF ( goods_quality < 0, 1, 0 ) AS is_return FROM qian WHERE store_name = '抖音小店' AND type_week < 4 ),
b AS (
SELECT
store_name,
goods_code,
types,
type_week,
is_return,
sum( goods_quality ) AS gq_sum,
sum( cost_price ) AS cp_sum,
sum( share_cost ) AS sc_sum,
sum( supply_price ) AS sp_sum
FROM
a
GROUP BY
goods_code,
type_week,
is_return
),
c AS (
SELECT
t1.*,
t2.type_week AS nw,
t2.gq_sum AS n_gq_sum,
t2.cp_sum AS n_cp_sum,
t2.sc_sum AS n_sc_sum,
t2.sp_sum AS n_sp_sum
FROM
b AS t1
LEFT JOIN b AS t2 ON t1.goods_code = t2.goods_code
AND t1.is_return = t2.is_return
AND t2.type_week = t1.type_week + 1
),
d AS (
SELECT
*,
sum( gq_sum ) over w AS c_w_r_sales,
sum( n_gq_sum ) over w AS n_w_r_sales
FROM
c window w AS ( PARTITION BY types, type_week, is_return )
),
e AS (
SELECT
*,
gq_sum / c_w_r_sales AS cr,
n_gq_sum / n_w_r_sales AS nr,
IF
( n_w_r_sales IS NULL OR c_w_r_sales IS NULL, - 1, ( n_w_r_sales - c_w_r_sales ) / c_w_r_sales ) *
IF
( is_return = 1, - 1, 1 ) AS c_ratio
FROM
d
),
f AS (
SELECT
*,
DENSE_RANK() over w AS rk
FROM
e window w AS ( PARTITION BY types, type_week, is_return ORDER BY gq_sum DESC )),
h AS (
SELECT
*,
DENSE_RANK() over w AS tmp_r
FROM
f window w AS ( PARTITION BY goods_code, is_return ORDER BY type_week )),
i AS ( SELECT *, IF ( type_week = 0, type_week + 1 = tmp_r, tmp_r = type_week ) AS tmp_x FROM h ),
j AS (
SELECT
*,
sum( tmp_x ) over w AS continue_w,
sum( sc_sum ) over w AS total_sales,
sum( gq_sum ) over w AS total_gq,
sum( cp_sum ) over w AS total_cp
FROM
i window w AS ( PARTITION BY goods_code, is_return )) SELECT
*,
sum( total_sales ) over w AS t_sales,
sum( total_gq ) over w AS t_q,
sum( total_cp ) over w AS t_c
FROM
j window w AS ( PARTITION BY types, is_return )
ORDER BY
goods_code,
type_week;
整体概览, 局部细分.
这种看起来非常复杂的多层级数据分析, 在窗口函数加持之下, 只是按需获取的数据, 不需要各种临时表, 辅助变量即可实现
可以根据探索维度需要不断地进行调整, 但是不需要将数据进行拆分, 然后再合并, 可以将所有的数据都整合在一起实现.
As of MySQL 8.0.28, a maximum of 127 windows is supported for a given
SELECT. Note that a single query may use multipleSELECTclauses, and each of these clauses supports up to 127 windows. The number of distinct windows is defined as the sum of the named windows and any implicit windows specified as part of any window function'sOVERclause. You should also be aware that queries using very large numbers of windows may require increasing the default thread stack size (thread_stacksystem variable).MySQL 8.0.28以上版本, 单个
select子语句支持多达127个窗口.
相对遗憾的是navicat的绘图部分暂不支持with语句.
二. 滑动窗口(Rolling Window)解析
By defining a frame as extending
Nrows on either side of the current row, you can compute rolling averages.
区间(可能是特定的行号之间, 也可能是数据范围之间)范围的数据的局部处理, 这个特性, 需要格外注意, 是相对容易搞混的知识点.
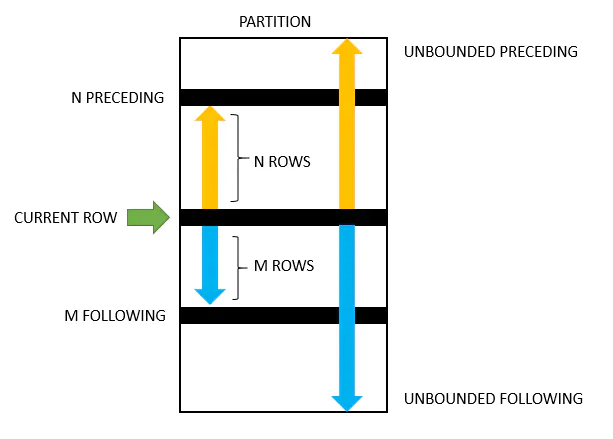
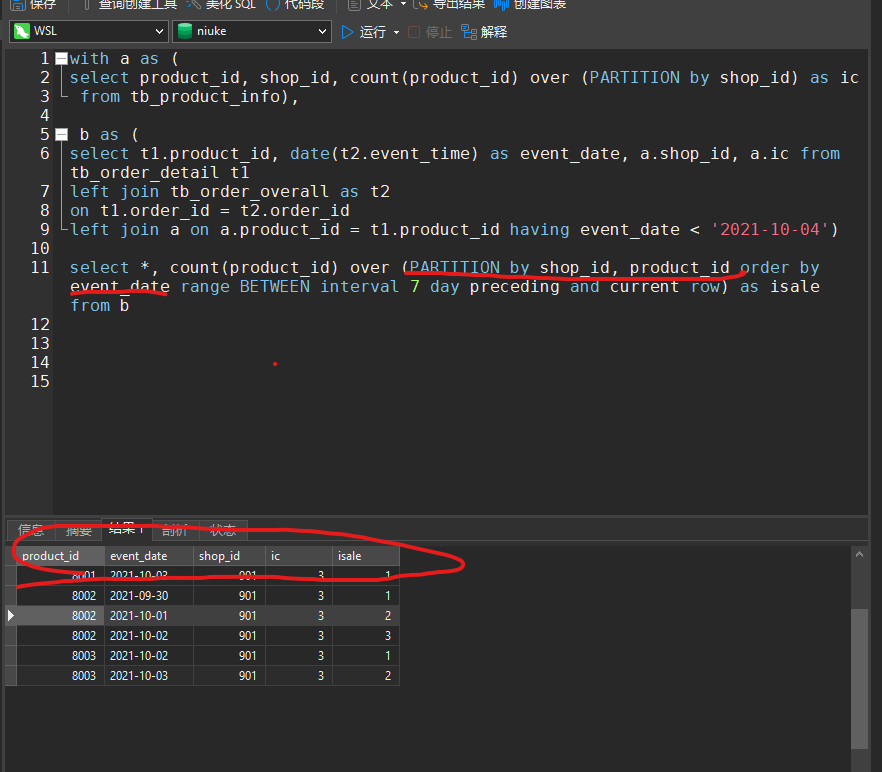
注意执行的顺序.
mysql> select * from test_f;
+------+------+
| c | v |
+------+------+
| a | 1 |
| b | 2 |
| c | 3 |
| d | 4 |
+------+------+
4 rows in set (0.00 sec)
SELECT
c,
v,
avg( v ) OVER ( ORDER BY v rows BETWEEN 1 preceding AND current ROW ) AS average_1,
avg( v ) OVER ( ORDER BY v rows BETWEEN 2 preceding AND current ROW ) AS average_2
FROM
test_f;
+------+------+-----------+-----------+
| c | v | average_1 | average_2 |
+------+------+-----------+-----------+
| a | 1 | 1.0000 | 1.0000 |
| b | 2 | 1.5000 | 1.5000 |
| c | 3 | 2.5000 | 2.0000 |
| d | 4 | 3.5000 | 3.0000 |
+------+------+-----------+-----------+
4 rows in set (0.00 sec)
上述结果的计算方式:
ETWEEN 1 preceding AND current ROW理论上包含2行数据
- 前一行
- 自身
avg1:
- 1.0, 这个值是在1 开始, 往后找1行, 找不到, 1 / 1 = 1
- 1.5, 这个是2 往后找1行, 找到1, (1 + 2) / 2 = 1.5
- 2.5, 这是从3往后找1行, 找到2, (2 + 3) / 2 = 2.5
- 3.5, 这是从4 开始找1行, 找到3, (3 + 4) / 2 = 3.5
avg2:
- 1.0, 这个值是在1开始, 往后找 2行, 找不到, 1 / 1 = 1
- 1.5, 这个是2 往后找, 找到2行(没有两行), 只能找到1, (1 + 2) / 2 = 1.5
- 2, 这是从3往后找, 向后找2行, 找到1, 2, (1 + 3 + 2) / 3 = 2
- 3, 这是从4 开始找, 向后找2行, 找到2, 3, (2 + 4 + 2) / 3 = 3
SELECT
c,
v,
avg( v ) OVER ( ORDER BY v rows BETWEEN 1 preceding AND 1 following ) AS average_3,
avg( v ) OVER ( ORDER BY v rows BETWEEN 2 preceding AND 2 following ) AS average_4
FROM
test_f;
+------+------+-----------+-----------+
| c | v | average_3 | average_4 |
+------+------+-----------+-----------+
| a | 1 | 1.5000 | 2.0000 |
| b | 2 | 2.0000 | 2.5000 |
| c | 3 | 3.0000 | 2.5000 |
| d | 4 | 3.5000 | 3.0000 |
+------+------+-----------+-----------+
4 rows in set (0.00 sec)
上述结果的计算方式:
BETWEEN 1 preceding AND 1 following理论上包含3行数据
- 前一行
- 自身
- 后一行
avg3:
- 1.5, 这个值是在1 开始, 往后找1行, 找不到, 往后找2, (2 + 1 / 2) = 1.5
- 2.5, 这个是2 往后找1行, 找到1, 向后找1行, 找到3, (1 + 2 + 3) / 3 = 2
- 3.0, 这是从3往后找1行, 找到2, 向后找一行, 找到4, (2 + 3 + 4) / 3 = 3
- 3.5, 这是从4 开始找1行, 找到3, 向前没找到, (3 + 4) / 2 = 3.5
avg4:
- 2.0, 这个值是在1开始, 往后找 2行, 找不到, 向前找2行, 2, 3 (1 + 2 + 3) / 2 = 2
- 2.5, 这个是2 往后找 , 找到2行(没有两行), 只能找到1, (2 + 1 + 3 + 4) / 4 = 2.5
- 2.5, 这是从3往后找, 向后找2行, 找到1, 2, 往前找4, (1 + 2 + 3 + 4) / 4 = 2.5
- 3.0, 这是从4 开始找, 向后找2行, 找到2, 3, (2 + 3 + 4) / 3 = 3
CUME_DIST()
DENSE_RANK()
LAG()
LEAD()
NTILE()
PERCENT_RANK()
RANK()
ROW_NUMBER()
Standard SQL specifies that window functions that operate on the entire partition should have no frame clause. MySQL permits a frame clause for such functions but ignores it. These functions use the entire partition even if a frame is specified:
注意以上函数是作用于整个分区(partition)的, 就算显式声明roll window也无效.
三. 函数详解
3.1 first_value()/last_value()
-
FIRST_VALUE()函数返回expression窗口框架第一行的值.FIRST_VALUE(expression) OVER ( [partition_clause] [order_clause] [frame_clause] ) -
LAST_VALUE()函数返回expression有序行集的最后一行的值.LAST_VALUE (expression) OVER ( [partition_clause] [order_clause] [frame_clause] )
SELECT
v,
FIRST_VALUE( v ) over w AS 'f_val',
FIRST_VALUE(v) over (PARTITION by v order by v) as 'f_val_2',
LAST_VALUE( v ) over () AS 'l_1',
LAST_VALUE( v ) over w AS 'l_2',
LAST_VALUE( v ) over ( ORDER BY v RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING ) AS 'l_3',
n
FROM
test_g WINDOW w AS ( ORDER BY v );
# 注意区别
+------+-------+---------+------+------+------+
| v | f_val | f_val_2 | l_1 | l_2 | l_3 |
+------+-------+---------+------+------+------+
| 1 | 1 | 1 | 5 | 1 | 5 |
| 1 | 1 | 1 | 5 | 1 | 5 |
| 2 | 1 | 2 | 5 | 2 | 5 |
| 3 | 1 | 3 | 5 | 3 | 5 |
| 3 | 1 | 3 | 5 | 3 | 5 |
| 3 | 1 | 3 | 5 | 3 | 5 |
| 4 | 1 | 4 | 5 | 4 | 5 |
| 4 | 1 | 4 | 5 | 4 | 5 |
| 5 | 1 | 5 | 5 | 5 | 5 |
+------+-------+---------+------+------+------+
9 rows in set (0.00 sec)
order by的作用
With
ORDER BY: The default frame includes rows from the partition start through the current row, including all peers of the current row (rows equal to the current row according to theORDER BYclause). The default is equivalent to this frame specification:RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
等价于此语句
Without
ORDER BY: The default frame includes all partition rows (because, withoutORDER BY, all partition rows are peers). The default is equivalent to this frame specification:假如没有
order by将包括所有的行(没有order by所有的(分区)的行都被视作等同的行)
f_val, 使用order by, 排序后返回第一行的数据, 即1, 1是最小的, 每一个行和1相比 都是返回1
f_val_2, 强制假如partition进行显式分区, 即, 每一行, 都是本身.
l_1, 没有使用order by, 即如上所述, 作用于全部的行, 最后一行是5, 所以返回的结果全是5
l_2, 使用order by, 即返回当前行和第一行中的最后一行, 由于已经进行排序, 最后显然是本身.
l_3, 使用order by, 同时手动指定窗体的范围(RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)是作用于全局, 即返回的是最后一行 和 l_1类似.
3.2 lead()/lag()
滑动函数
-
lead(), 向前LEAD(<expression>[,offset[, default_value]]) OVER ( PARTITION BY (expr) ORDER BY (expr) ) -
lag(), 向后LAG(<expression>[,offset[, default_value]]) OVER ( PARTITION BY expr,... ORDER BY expr [ASC|DESC],... )
支持参数:
col_nameoffset, 偏移值default_value, 默认值(不传入默认值, 则默认为null)
lag(col, 2, 0)
mysql> select * from test_f;
+------+------+
| c | v |
+------+------+
| a | 1 |
| b | 2 |
| c | 3 |
| d | 4 |
+------+------+
4 rows in set (0.00 sec)
# lag 向后
mysql> select *, lag(v) over() from test_f;
+------+------+---------------+
| c | v | lag(v) over() |
+------+------+---------------+
| a | 1 | NULL |
| b | 2 | 1 |
| c | 3 | 2 |
| d | 4 | 3 |
+------+------+---------------+
4 rows in set (0.00 sec)
# lad前
mysql> select *, lead(v) over() from test_f;
+------+------+----------------+
| c | v | lead(v) over() |
+------+------+----------------+
| a | 1 | 2 |
| b | 2 | 3 |
| c | 3 | 4 |
| d | 4 | NULL |
+------+------+----------------+
4 rows in set (0.01 sec)
3.3 percent_rank() /cume_dist()
分布函数
# CUME_DIST()函数的返回值大于零且小于或等于1(0 CUME_DIST()<< = 1)。重复的列值接收相同的CUME_DIST()值 CUME_DIST() OVER ( PARTITION BY expr, ... ORDER BY expr [ASC | DESC], ... )PERCENT_RANK() OVER ( PARTITION BY expr,... ORDER BY expr [ASC|DESC],... ) 计算公式: (rank - 1) / (total_rows - 1) rank 来自于 rank() 函数
WITH a AS (
SELECT
v,
ROW_NUMBER() OVER w AS 'row_number',
rank() over w AS 'rank_number',
CUME_DIST() OVER w AS 'cume_dist',
PERCENT_RANK() OVER w AS 'percent_rank',
count(*) over w AS 'total_row',
count(*) over () AS 'max_index'
FROM
test_g WINDOW w AS ( ORDER BY v )
) SELECT
*,
(( 1 / max_index ) * total_row ) ascum_cal,
((
rank_number - 1
) / ( max_index - 1 )) AS per_cal
FROM
a;
# 差异 / 计算方法
#
+------+------------+-------------+-----------+--------------+-----------+-----------+-----------+---------+
| v | row_number | rank_number | cume_dist | percent_rank | total_row | max_index | ascum_cal | per_cal |
+------+------------+-------------+-----------+--------------+-----------+-----------+-----------+---------+
| 1 | 1 | 1 | 0.22 | 0 | 2 | 9 | 0.2222 | 0.0000 |
| 1 | 2 | 1 | 0.22 | 0 | 2 | 9 | 0.2222 | 0.0000 |
| 2 | 3 | 3 | 0.33 | 0.25 | 3 | 9 | 0.3333 | 0.2500 |
| 3 | 4 | 4 | 0.67 | 0.375 | 6 | 9 | 0.6667 | 0.3750 |
| 3 | 5 | 4 | 0.67 | 0.375 | 6 | 9 | 0.6667 | 0.3750 |
| 3 | 6 | 4 | 0.67 | 0.375 | 6 | 9 | 0.6667 | 0.3750 |
| 4 | 7 | 7 | 0.89 | 0.75 | 8 | 9 | 0.8889 | 0.7500 |
| 4 | 8 | 7 | 0.89 | 0.75 | 8 | 9 | 0.8889 | 0.7500 |
| 5 | 9 | 9 | 1 | 1 | 9 | 9 | 1.0000 | 1.0000 |
+------+------------+-------------+-----------+--------------+-----------+-----------+-----------+---------+
9 rows in set (0.00 sec)
3.4 row_number()/rank()/dense_rank()
排名函数
SELECT
v,
ROW_NUMBER() over w AS 'rn',
rank() over w AS 'r',
DENSE_RANK() over w AS 'dr'
FROM
test_g window w AS ( ORDER BY v );
+------+----+---+----+
| v | rn | r | dr |
+------+----+---+----+
| 1 | 1 | 1 | 1 |
| 1 | 2 | 1 | 1 |
| 2 | 3 | 3 | 2 |
| 3 | 4 | 4 | 3 |
| 3 | 5 | 4 | 3 |
| 3 | 6 | 4 | 3 |
| 4 | 7 | 7 | 4 |
| 4 | 8 | 7 | 4 |
| 5 | 9 | 9 | 5 |
+------+----+---+----+
9 rows in set (0.00 sec)
3.5 nth_value()
取排名N(使用的是行号(row_number()))
SELECT
v,
NTH_VALUE( v, 3 ) over w AS 'a',
NTH_VALUE( v, 3 ) over ( ORDER BY v rows BETWEEN unbounded preceding AND unbounded following ) AS 'b'
FROM
test_g window w AS ( ORDER BY v );
+------+------+------+
| v | a | b |
+------+------+------+
| 1 | NULL | 2 |
| 1 | NULL | 2 | # 默认是空缺
| 2 | 2 | 2 | # 手动指定分区为全局模式, 不希望为null
| 3 | 2 | 2 |
| 3 | 2 | 2 |
| 3 | 2 | 2 |
| 4 | 2 | 2 |
| 4 | 2 | 2 |
| 5 | 2 | 2 |
+------+------+------+
9 rows in set (0.00 sec)
3.6 ntile()
分桶函数, NTILE(N), N即需要分的数量
SELECT
v,
NTILE(3) over w as 'bucket'
FROM
test_g window w AS ( ORDER BY v );
+------+--------+
| v | bucket |
+------+--------+
| 1 | 1 |
| 1 | 1 |
| 2 | 1 |
| 3 | 2 |
| 3 | 2 |
| 3 | 2 |
| 4 | 3 |
| 4 | 3 |
| 5 | 3 |
+------+--------+
9 rows in set (0.00 sec)
四. 数据
# 表结构
mysql> desc user_trade;
+----------------+-------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------------+-------------------+------+-----+---------+-------+
| user_name | varchar(16) | NO | | NULL | |
| piece | smallint unsigned | YES | | NULL | |
| price | float | YES | | NULL | |
| pay_amount | float | YES | | NULL | |
| goods_category | varchar(16) | YES | | NULL | |
| pay_time | timestamp | YES | | NULL | |
+----------------+-------------------+------+-----+---------+-------+
6 rows in set (0.00 sec)
# 数据简要
mysql> select * from user_trade limit 10;
+-----------+-------+-------+------------+----------------+---------------------+
| user_name | piece | price | pay_amount | goods_category | pay_time |
+-----------+-------+-------+------------+----------------+---------------------+
| Allison | 4 | 688.8 | 2755.2 | shoes | 2018-01-07 00:00:00 |
| Francis | 83 | 1.1 | 91.3 | food | 2018-01-07 00:00:00 |
| DEMI | 26 | 2222 | 57772 | electronics | 2018-01-12 00:00:00 |
| DEMI | 39 | 200 | 7800 | clothes | 2018-01-12 00:00:00 |
| Enid | 15 | 6666 | 99990 | computer | 2018-01-12 00:00:00 |
| Heidi | 93 | 688.8 | 64058.4 | shoes | 2018-01-12 00:00:00 |
| Jackson | 43 | 200 | 8600 | clothes | 2018-01-12 00:00:00 |
| Carroll | 1 | 688.8 | 688.8 | shoes | 2018-01-22 00:00:00 |
| Carlos | 52 | 8.9 | 462.8 | book | 2018-02-05 00:00:00 |
| Aviva | 74 | 2222 | 164428 | electronics | 2018-02-05 00:00:00 |
+-----------+-------+-------+------------+----------------+---------------------+
10 rows in set (0.00 sec)
五. 案例
基于上述数据, 简单演示生成相关常用指标数据.
5.1 用户端
5.1.1 交易
5.1.1.1 情景1
- 统计2019年的各个月的支付总额
- 计算出每个月的累积额
- 保留两位小数
- 按照月份排序
WITH a AS (
SELECT MONTH
( pay_time ) AS mon,
CONVERT (
sum( pay_amount ),
DECIMAL ( 10, 2 )) AS mon_pay
FROM
user_trade
WHERE
YEAR ( pay_time ) = 2019
GROUP BY
mon
) SELECT
a.mon,
a.mon_pay,
sum( a.mon_pay ) over ( ORDER BY a.mon ) AS sum_amount
FROM
a;
+------+------------+-------------+
| mon | mon_pay | sum_amount |
+------+------------+-------------+
| 1 | 317697.20 | 317697.20 |
| 2 | 2214537.10 | 2532234.30 |
| 3 | 3108435.90 | 5640670.20 |
| 4 | 2717482.60 | 8358152.80 |
| 5 | 2723670.10 | 11081822.90 |
| 6 | 3808041.30 | 14889864.20 |
| 7 | 5426222.30 | 20316086.50 |
| 8 | 2749747.00 | 23065833.50 |
| 9 | 891197.00 | 23957030.50 |
| 10 | 1510374.30 | 25467404.80 |
| 11 | 2307257.40 | 27774662.20 |
| 12 | 1759487.20 | 29534149.40 |
+------+------------+-------------+
12 rows in set (0.00 sec)
5.1.1.1.1 解析
# round函数
mysql> select round(1, 2) as a, round(1.1, 2) as c, round(1.234, 2) as c;
+---+-----+------+
| a | c | c |
+---+-----+------+
| 1 | 1.1 | 1.23 |
+---+-----+------+
1 row in set (0.00 sec)
# 即, 运算的内容是多少位的, round只会截取, 但不会主动补位
mysql> select round(1 * 1.00, 2) as a, round(1.1 * 1.00, 2) as c, round(1.234 * 1.00, 2) as c;
+------+------+------+
| a | c | c |
+------+------+------+
| 1.00 | 1.10 | 1.23 |
+------+------+------+
1 row in set (0.00 sec)
mysql> select round(1.235, 2);
+-----------------+
| round(1.235, 2) |
+-----------------+
| 1.24 |
+-----------------+
1 row in set (0.00 sec)
CONVERT 语法
# 将数据进行类型的转换
CONVERT(*value*, *type*)
OR:
CONVERT(*value* USING *charset*)
参数值
| 参数 | 描述 |
|---|---|
| value | 必需, 要转换的值 |
| type | 见下表 |
| charset | 必需。要转换成的字符集 |
| 值 | 描述 |
|---|---|
| DATE | 将 value 转换为 DATE, 格式: "YYYY-MM-DD" |
| DATETIME | 将 value 转换为 DATETIME.Format: "YYYY-MM-DD HH:MM:SS" |
| DECIMAL | 将 value 转换为 DECIMAL。 使用可选的 M 和 D 参数指定最大位数 (M) 和小数点后的位数 (D)。 |
| TIME | 将 值 转换为 TIME。 格式: "HH:MM:SS" |
| CHAR | 将 value 转换为 CHAR(固定长度字符串) |
| NCHAR | 将 value 转换为 NCHAR(类似于 CHAR,但生成带有地区字符集的字符串) |
| SIGNED | 将 value 转换为 SIGNED(带符号的 64 位整数) |
| UNSIGNED | 将 value 转换为 UNSIGNED(无符号 64 位整数) |
| BINARY | 将 value 转换为 BINARY(二进制字符串) |
WITH a AS (
SELECT MONTH
( pay_time ) AS mon,
CONVERT (
sum( pay_amount ),
DECIMAL ( 10, 2 )) AS mon_pay
FROM
user_trade
WHERE
YEAR ( pay_time ) = 2019
GROUP BY
mon
) SELECT
a.mon,
a.mon_pay,
# 这里去掉 over() 中的参数
# 得到的是最终的sum
sum( a.mon_pay ) over () AS sum_amount
FROM
a;
+------+------------+-------------+
| mon | mon_pay | sum_amount |
+------+------------+-------------+
| 1 | 317697.20 | 29534149.40 |
| 2 | 2214537.10 | 29534149.40 |
| 3 | 3108435.90 | 29534149.40 |
| 4 | 2717482.60 | 29534149.40 |
| 5 | 2723670.10 | 29534149.40 |
| 6 | 3808041.30 | 29534149.40 |
| 7 | 5426222.30 | 29534149.40 |
| 8 | 2749747.00 | 29534149.40 |
| 9 | 891197.00 | 29534149.40 |
| 10 | 1510374.30 | 29534149.40 |
| 11 | 2307257.40 | 29534149.40 |
| 12 | 1759487.20 | 29534149.40 |
+------+------------+-------------+
12 rows in set (0.00 sec)
WITH a AS (
SELECT MONTH
( pay_time ) AS mon,
CONVERT (
sum( pay_amount ),
DECIMAL ( 10, 2 )) AS mon_pay
FROM
user_trade
WHERE
YEAR ( pay_time ) = 2019
GROUP BY
mon
) SELECT
a.mon,
a.mon_pay,
# 将参数修改
# 即实际上就是汇总自己
sum( a.mon_pay ) over (PARTITION by a.mon) AS sum_amount
FROM
a;
+------+------------+------------+
| mon | mon_pay | sum_amount |
+------+------------+------------+
| 1 | 317697.20 | 317697.20 |
| 2 | 2214537.10 | 2214537.10 |
| 3 | 3108435.90 | 3108435.90 |
| 4 | 2717482.60 | 2717482.60 |
| 5 | 2723670.10 | 2723670.10 |
| 6 | 3808041.30 | 3808041.30 |
| 7 | 5426222.30 | 5426222.30 |
| 8 | 2749747.00 | 2749747.00 |
| 9 | 891197.00 | 891197.00 |
| 10 | 1510374.30 | 1510374.30 |
| 11 | 2307257.40 | 2307257.40 |
| 12 | 1759487.20 | 1759487.20 |
+------+------------+------------+
12 rows in set (0.00 sec)
5.1.1.2 情景2
WITH a AS (
SELECT
# 用户
user_name,
# 支付的月份
substring( pay_time, 1, 7 ) AS pay_mon,
# 该用户的支付总额
sum(pay_amount) as user_pay_sum,
# 平均支付额
avg( pay_amount ) AS avg_user_pay,
# 累积支付次数
count( user_name ) AS pay_times
FROM
user_trade
WHERE
YEAR ( pay_time ) = 2018
GROUP BY
user_name,
pay_mon
),
b AS (
SELECT
*,
# 月的整体支付额
sum( avg_user_pay ) over ( PARTITION BY pay_mon ) AS mon_pay_total,
# 月整体支付笔
sum( pay_times ) over ( PARTITION BY pay_mon ) AS total_mon_pay_times,
# 月平均每个用户支付额
avg( avg_user_pay ) over ( PARTITION BY pay_mon ) AS total_avg_user_pay
FROM
a
) SELECT
*,
# 月平局每一笔的支付额
mon_pay_total / total_mon_pay_times AS total_avg_one_pay
FROM
b;
| user_name | pay_mon | user_pay_sum | avg_user_pay | pay_times | mon_pay_total | total_mon_pay_times | total_avg_user_pay | total_avg_one_pay |
|---|---|---|---|---|---|---|---|---|
| Francis | 2018-01 | 91.3 | 91.3 | 1 | 208969.7 | 8 | 29852.81405 | 26121.21 |
| DEMI | 2018-01 | 65572 | 32786 | 2 | 208969.7 | 8 | 29852.81405 | 26121.21 |
| Enid | 2018-01 | 99990 | 99990 | 1 | 208969.7 | 8 | 29852.81405 | 26121.21 |
| Heidi | 2018-01 | 64058.4 | 64058.4 | 1 | 208969.7 | 8 | 29852.81405 | 26121.21 |
| Jackson | 2018-01 | 8600 | 8600 | 1 | 208969.7 | 8 | 29852.81405 | 26121.21 |
| Carroll | 2018-01 | 688.8 | 688.8 | 1 | 208969.7 | 8 | 29852.81405 | 26121.21 |
| Allison | 2018-01 | 2755.2 | 2755.2 | 1 | 208969.7 | 8 | 29852.81405 | 26121.21 |
5.1.1.3 情景3
- 2020年支付金额排名前30%的用户, 以及该用户支付的金额占当年的总额的百分比
WITH a AS ( SELECT user_name, sum( pay_amount ) AS total FROM test_c WHERE YEAR ( pay_time ) = 2020 GROUP BY user_name ),
b AS (
SELECT
user_name,
total,
sum( total ) over ( PARTITION BY NULL ) AS all_total,
ntile( 10 ) over ( ORDER BY total DESC ) AS s_part
FROM
a
) SELECT
user_name,
round( total, 2 ) AS user_pay_total,
concat( round( total / all_total * 100, 2 ), '%' ) AS user_percent
FROM
b
WHERE
s_part < 4;
+-----------+----------------+--------------+
| user_name | user_pay_total | user_percent |
+-----------+----------------+--------------+
| Moore | 686598 | 8.1% |
| KAREN | 626604 | 7.39% |
| Marshall | 586654.2 | 6.92% |
| Frank | 579942 | 6.84% |
| Emma | 564388 | 6.66% |
| King | 553344 | 6.53% |
| Keith | 493580.9 | 5.82% |
| JUNE | 379962 | 4.48% |
| Amanda | 359964 | 4.24% |
| Morris | 318814 | 3.76% |
| Bonnie | 310746 | 3.66% |
| Francis | 236731.2 | 2.79% |
| Carroll | 228866 | 2.7% |
| Christy | 218186.4 | 2.57% |
| Ethan | 208736 | 2.46% |
| Ray | 202202 | 2.38% |
| Regan | 195536 | 2.31% |
| Knight | 193314 | 2.28% |
| DAISY | 188870 | 2.23% |
| Ailsa | 151096 | 1.78% |
| Iris | 139986 | 1.65% |
+-----------+----------------+--------------+
21 rows in set (0.01 sec)
5.1.1.4 情景4
- 每个月的支付总额
- 每4个月(不一定是连续的月份), 挑出支付总额最大的
WITH a AS (
SELECT
SUBSTRING( pay_time, 1, 7 ) AS mon,
sum( pay_amount ) AS pay_amount
FROM
user_trade
GROUP BY
SUBSTRING( pay_time, 1, 7 )
) SELECT
a.mon,
a.pay_amount,
max( a.pay_amount ) over ( ORDER BY a.mon rows BETWEEN 3 preceding AND current ROW ) AS max_amount
FROM
a;
+---------+--------------------+--------------------+
| mon | pay_amount | max_amount |
+---------+--------------------+--------------------+
| 2018-01 | 241755.6983795166 | 241755.6983795166 |
| 2018-02 | 2582410.601480484 | 2582410.601480484 |
| 2018-03 | 1977644.698231697 | 2582410.601480484 |
| 2018-04 | 1162322.8000335693 | 2582410.601480484 | # 每4个月, 就挑出最大的
| 2018-05 | 3038255.1976127625 | 3038255.1976127625 |
| 2018-06 | 2773154.397846222 | 3038255.1976127625 |
| 2018-07 | 1677527.2999550104 | 3038255.1976127625 |
| 2018-08 | 2135214.4019756317 | 3038255.1976127625 |
| 2018-09 | 1355307.2950782776 | 2773154.397846222 |
| 2018-10 | 1380672.7007484436 | 2135214.4019756317 |
| 2018-11 | 2428753.8984622955 | 2428753.8984622955 |
| 2018-12 | 3580954.6004139185 | 3580954.6004139185 |
| 2019-01 | 317697.20156288147 | 3580954.6004139185 |
| 2019-02 | 2214537.096616745 | 3580954.6004139185 |
| 2019-03 | 3108435.8980026245 | 3580954.6004139185 |
| 2019-04 | 2717482.603122711 | 3108435.8980026245 |
| 2019-05 | 2723670.100774765 | 3108435.8980026245 |
| 2019-06 | 3808041.298687935 | 3808041.298687935 |
| 2019-07 | 5426222.302730083 | 5426222.302730083 |
| 2019-08 | 2749746.999607086 | 5426222.302730083 |
| 2019-09 | 891197.0007789135 | 5426222.302730083 |
| 2019-10 | 1510374.30027318 | 5426222.302730083 |
| 2019-11 | 2307257.399263382 | 2749746.999607086 |
| 2019-12 | 1759487.2003774643 | 2307257.399263382 |
| 2020-01 | 1480003.602306366 | 2307257.399263382 |
| 2020-02 | 3180078.69924736 | 3180078.69924736 |
| 2020-03 | 2394982.3970298767 | 3180078.69924736 |
| 2020-04 | 1424853.5996108055 | 3180078.69924736 |
+---------+--------------------+--------------------+
28 rows in set (0.01 sec)
5.1.1.5 情景5
- 2018 -2019的各个月累积支付
WITH a AS (
SELECT YEAR( a.pay_time ) AS year,
MONTH ( a.pay_time ) AS mon,
sum( a.pay_amount ) AS pay_amount
FROM
user_trade a
GROUP BY
year,
mon having year in (2018, 2019)
) SELECT
a.*,
sum( a.pay_amount ) over ( PARTITION BY a.year ORDER BY a.mon ) AS sum_amount
FROM
a;
# 记住order by = between unbounded preceding and current row
+------+------+--------------------+--------------------+
| year | mon | pay_amount | sum_amount |
+------+------+--------------------+--------------------+
| 2018 | 1 | 241755.6983795166 | 241755.6983795166 |
| 2018 | 2 | 2582410.601480484 | 2824166.2998600006 |
| 2018 | 3 | 1977644.698231697 | 4801810.998091698 |
| 2018 | 4 | 1162322.8000335693 | 5964133.798125267 |
| 2018 | 5 | 3038255.1976127625 | 9002388.99573803 |
| 2018 | 6 | 2773154.397846222 | 11775543.393584251 |
| 2018 | 7 | 1677527.2999550104 | 13453070.693539262 |
| 2018 | 8 | 2135214.4019756317 | 15588285.095514894 |
| 2018 | 9 | 1355307.2950782776 | 16943592.39059317 |
| 2018 | 10 | 1380672.7007484436 | 18324265.091341615 |
| 2018 | 11 | 2428753.8984622955 | 20753018.98980391 |
| 2018 | 12 | 3580954.6004139185 | 24333973.59021783 |
| 2019 | 1 | 317697.20156288147 | 317697.20156288147 |
| 2019 | 2 | 2214537.096616745 | 2532234.2981796265 |
| 2019 | 3 | 3108435.8980026245 | 5640670.196182251 |
| 2019 | 4 | 2717482.603122711 | 8358152.799304962 |
| 2019 | 5 | 2723670.100774765 | 11081822.900079727 |
| 2019 | 6 | 3808041.298687935 | 14889864.198767662 |
| 2019 | 7 | 5426222.302730083 | 20316086.501497746 |
| 2019 | 8 | 2749746.999607086 | 23065833.50110483 |
| 2019 | 9 | 891197.0007789135 | 23957030.501883745 |
| 2019 | 10 | 1510374.30027318 | 25467404.802156925 |
| 2019 | 11 | 2307257.399263382 | 27774662.201420307 |
| 2019 | 12 | 1759487.2003774643 | 29534149.40179777 |
+------+------+--------------------+--------------------+
24 rows in set (0.00 sec)
5.1.2 活跃
# 连续两天产生支付行为的用户
# 类似于连续登录问题
# 注意连续问题
WITH tmp AS ( SELECT DISTINCT user_name, pay_time FROM user_trade ),
temp AS (
SELECT
*,
# 注意需求, 是否要求连续, 如 1, 2, 3, 还是 1, 3, 5这种情况也满足要求
count( user_name ) over ( PARTITION BY user_name ORDER BY pay_time RANGE BETWEEN INTERVAL 1 day preceding AND current ROW ) AS ic
FROM
tmp
) SELECT
temp.user_name,
temp.ic
FROM
temp
WHERE
temp.ic > 1 order by temp.ic;
### or
### 显然没有滚动窗口的实现方方式来的简洁
# 但是这种方式使用处理不确定区间的, 只是希望取得最长的连续区间的情况
WITH tmp AS ( SELECT DISTINCT user_name, pay_time FROM user_trade ),
tmp_a AS ( SELECT *, dense_rank() over ( PARTITION BY user_name ORDER BY pay_time ) AS r FROM tmp ),
tmp_b AS ( SELECT *, DATE_SUB( pay_time, INTERVAL r DAY ) AS sub FROM tmp_a ) SELECT
tmp_b.user_name,
count(*) AS c
FROM
tmp_b
GROUP BY
tmp_b.user_name,
tmp_b.sub
HAVING
c > 1;
| user_name | c |
|---|---|
| David | 2 |
| Dunn | 2 |
| Gordon | 2 |
| Grant | 2 |
| Jocelyn | 2 |
| JOY | 2 |
| Judy | 2 |
mysql> SELECT DISTINCT user_name, pay_time FROM user_trade where user_name = 'Allen';
+-----------+---------------------+
| user_name | pay_time |
+-----------+---------------------+
| Allen | 2018-08-19 00:00:00 |
| Allen | 2019-08-14 00:00:00 |
| Allen | 2019-08-15 00:00:00 |
| Allen | 2020-04-21 00:00:00 |
+-----------+---------------------+
4 rows in set (0.00 sec)
mysql> SELECT DISTINCT user_name, pay_time FROM user_trade where user_name = 'David';
+-----------+---------------------+
| user_name | pay_time |
+-----------+---------------------+
| David | 2018-03-03 00:00:00 |
| David | 2018-12-01 00:00:00 |
| David | 2019-03-29 00:00:00 |
| David | 2019-03-30 00:00:00 |
+-----------+---------------------+
4 rows in set (0.00 sec)
# 连续2个月(及以上)支付情况
WITH tmp AS ( SELECT DISTINCT user_name, convert(concat(substring(pay_time, 1, 7), '-01'), date) as pay_mon FROM user_trade ),
temp AS (
SELECT
*,
count( user_name ) over ( PARTITION BY user_name ORDER BY pay_mon RANGE BETWEEN INTERVAL 2 month preceding AND current ROW ) AS ic
FROM
tmp
) SELECT
temp.user_name,
temp.ic
FROM
temp
WHERE
temp.ic > 1 order by temp.ic;
# 该用户连续三个月活跃
# 这个活跃度问题, 在算法中就是有趣的连续数字的问题
# 找出最长的连续数字部分, 1,4,2,3,5,7,8,9,0, => 7,8,9
mysql> SELECT DISTINCT user_name, convert(concat(substring(pay_time, 1, 7), '-01'), date) as pay_mon FROM user_trade where user_name ='Andrea';
+-----------+------------+
| user_name | pay_mon |
+-----------+------------+
| Andrea | 2019-06-01 |
| Andrea | 2019-07-01 |
| Andrea | 2019-08-01 |
+-----------+------------+
3 rows in set (0.00 sec)
用户的月活跃情况
- 用户的月支付总额, 支付次数, 平均单笔支付金额
- 月整体用户支付次数, 支付/用户平均金额, 支付/支付次数平均金额
- 用户连续N天/月内产生支付行为.
- 哪些用户的低于平均值
- 月的支付总次数的变化, 单笔支付平均金额的变化, 用户平均支付金额的变化
- 最大最小值, 在月支付总额, 单笔平均支付, 单个用户平均支付.
- 哪些用户的活跃度最高/低
5.1.3 用户划分
5.1.3.1 情景1
- 根据2020-02用户支付的总额对用户进行分桶, 分成5份
SELECT
a.user_name,
CONVERT (
sum( a.pay_amount ),
DECIMAL ( 10, 2 )) AS pay_amount,
ntile( 5 ) over ( ORDER BY sum( a.pay_amount ) DESC ) AS level
FROM
user_trade a
WHERE
SUBSTRING( a.pay_time, 1, 7 ) = '2020-02'
GROUP BY
a.user_name;
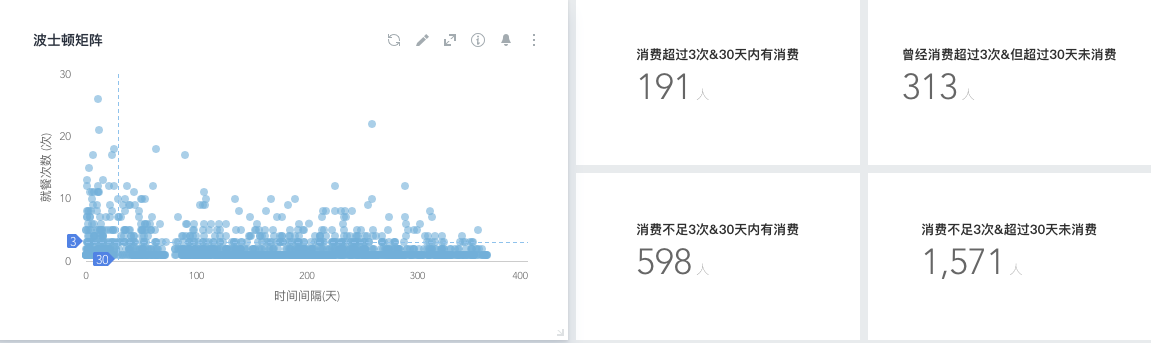
根据用户的支付情况, 对用户进行划分
根据用户的支付情况, 对比成本, 获得收益情况, 根据收益情况(如毛利高于多少的)对用户进行划分.
根据用户的活跃情况, 对用户进行划分.
根据用户的情况, 对用户进行差异化管理和使用不同的营销策略.
5.1.3.2 情景2
- 查询每年支付时间间隔最长的用户.
WITH a AS (
SELECT YEAR
( pay_time ) AS years,
user_name,
pay_time,
lag( pay_time ) over ( PARTITION BY user_name, YEAR ( pay_time ) ORDER BY pay_time ) AS lg
FROM
user_trade
),
b AS (
SELECT
a.years,
a.user_name,
datediff( a.pay_time, a.lg ) AS pay_days,
rank() over ( PARTITION BY a.years ORDER BY datediff( a.pay_time, a.lg ) DESC ) AS rk
FROM
a
where
a.lg IS NOT NULL
) SELECT
b.years,
b.user_name,
b.pay_days
FROM
b
WHERE
b.rk = 1;
5.13.2.1 解析
# 以年-用户作为维度
# lag
SELECT YEAR
( pay_time ) AS years,
user_name,
pay_time,
lag( pay_time ) over ( PARTITION BY user_name, YEAR ( pay_time ) ORDER BY pay_time ) AS lg
FROM
user_trade limit 10;
+-------+-----------+---------------------+---------------------+
| years | user_name | pay_time | lg |
+-------+-----------+---------------------+---------------------+
| 2018 | Abby | 2018-06-29 00:00:00 | NULL |
| 2019 | Abby | 2019-07-02 00:00:00 | NULL |
| 2019 | Abby | 2019-09-01 00:00:00 | 2019-07-02 00:00:00 |
| 2019 | Abby | 2019-09-01 00:00:00 | 2019-09-01 00:00:00 |
| 2018 | Ailsa | 2018-12-13 00:00:00 | NULL |
| 2018 | Ailsa | 2018-12-13 00:00:00 | 2018-12-13 00:00:00 |
| 2019 | Ailsa | 2019-02-03 00:00:00 | NULL |
| 2020 | Ailsa | 2020-02-20 00:00:00 | NULL |
| 2018 | Albert | 2018-07-15 00:00:00 | NULL |
| 2019 | Albert | 2019-09-03 00:00:00 | NULL |
+-------+-----------+---------------------+---------------------+
10 rows in set (0.00 sec)
5.1.3.3 情景3
- 找出支付时间间隔超过1年的用户
with a as (
SELECT
user_name,
pay_time,
lag( pay_time ) over ( PARTITION BY user_name ORDER BY pay_time ) AS lg
FROM
user_trade
)
SELECT
DISTINCT a.user_name as user, DATEDIFF( a.pay_time, a.lg ) as gap
FROM a
having
gap > 365;
+------------+------+
| user | gap |
+------------+------+
| Abby | 368 |
| Ailsa | 382 |
| Albert | 415 |
| Andy | 379 |
| Angela | 510 |
| Ann | 500 |
| Annie | 538 |
| April | 644 |
| Aviva | 529 |
| Baker | 464 |
| Bonnie | 631 |
| Brooklyn | 418 |
| Candice | 467 |
| Carl | 465 |
| Carlos | 602 |
| Carroll | 547 |
| Christine | 372 |
| Christy | 570 |
| Cloris | 593 |
| DAISY | 451 |
| DEBBIE | 448 |
| EDITHA | 409 |
| ELLIE | 433 |
| Elliott | 378 |
| Ellis | 509 |
| Emma | 420 |
| Ethan | 399 |
| Eva | 409 |
| Eve | 481 |
| Fiona | 486 |
| Francis | 420 |
| Frank | 429 |
| Franklin | 380 |
| Gloria | 622 |
| Harris | 372 |
| Harrison | 491 |
| HELLEN | 538 |
| Henry | 377 |
| Hunter | 575 |
| Iris | 395 |
| Jackson | 517 |
| Jessica | 574 |
| Jill | 625 |
| Johnson | 417 |
| JUNE | 728 |
| KATHY | 506 |
| KELLY | 514 |
| KITTY | 448 |
| Klein | 476 |
| Knight | 501 |
| Lawrence | 430 |
| Lee | 502 |
| Marshall | 475 |
| Mason | 637 |
| Morris | 656 |
| Murphy | 366 |
| Pearson | 382 |
| Perry | 367 |
| Peterson | 413 |
| Phillips | 496 |
| Powell | 391 |
| Regan | 483 |
| Rupert | 398 |
| Taylor | 499 |
| Ward | 571 |
| Washington | 423 |
| Webb | 372 |
| West | 491 |
| Wheeler | 705 |
| Willis | 390 |
+------------+------+
70 rows in set (0.01 sec)
5.1.3.3.1 解析
-
DATEDIFF函数语法
DATEDIFF(date1, date2)参数值
参数 描述 date1, date2 必需。计算两个日期之间的天数。 (日期 1 - 日期 2) -
lag函数LAG(<expression>[,offset[, default_value]]) OVER ( PARTITION BY expr,... ORDER BY expr [ASC|DESC],... ) # 如果没有前一行,则LAG()函数返回default_value。例如,如果offset为2,则第一行的返回值为default_value。如果省略default_value,则默认LAG()返回函数NULL。lag函数从同一结果集中的当前行访问上一行的数据.mysql> SELECT -> -> user_name, -> -> pay_time, -> -> lag( pay_time ) over ( PARTITION BY user_name ORDER BY pay_time ) AS lg ROM -> FROM -> -> user_trade limit 10; +-----------+---------------------+---------------------+ | user_name | pay_time | lg | +-----------+---------------------+---------------------+ | Abby | 2018-06-29 00:00:00 | NULL | | Abby | 2019-07-02 00:00:00 | 2018-06-29 00:00:00 | | Abby | 2019-09-01 00:00:00 | 2019-07-02 00:00:00 | | Abby | 2019-09-01 00:00:00 | 2019-09-01 00:00:00 | | Ailsa | 2018-12-13 00:00:00 | NULL | | Ailsa | 2018-12-13 00:00:00 | 2018-12-13 00:00:00 | | Ailsa | 2019-02-03 00:00:00 | 2018-12-13 00:00:00 | | Ailsa | 2020-02-20 00:00:00 | 2019-02-03 00:00:00 | | Albert | 2018-07-15 00:00:00 | NULL | | Albert | 2019-09-03 00:00:00 | 2018-07-15 00:00:00 | +-----------+---------------------+---------------------+ 10 rows in set (0.00 sec)# lag 带有参数 2 mysql> SELECT -> -> user_name, -> -> pay_time, -> -> lag( pay_time, 2 ) over ( PARTITION BY user_name ORDER BY pay_time ) AS lg r_trade -> FROM 0; -> -> user_trade limit 10; +-----------+---------------------+---------------------+ | user_name | pay_time | lg | +-----------+---------------------+---------------------+ | Abby | 2018-06-29 00:00:00 | NULL | | Abby | 2019-07-02 00:00:00 | NULL | | Abby | 2019-09-01 00:00:00 | 2018-06-29 00:00:00 | | Abby | 2019-09-01 00:00:00 | 2019-07-02 00:00:00 | | Ailsa | 2018-12-13 00:00:00 | NULL | | Ailsa | 2018-12-13 00:00:00 | NULL | | Ailsa | 2019-02-03 00:00:00 | 2018-12-13 00:00:00 | | Ailsa | 2020-02-20 00:00:00 | 2018-12-13 00:00:00 | | Albert | 2018-07-15 00:00:00 | NULL | | Albert | 2019-09-03 00:00:00 | NULL | +-----------+---------------------+---------------------+ 10 rows in set (0.00 sec)
5.2 产品端
5.2.1 情景1
WITH a AS (
SELECT
goods_category,
CONVERT ( concat( substring( pay_time, 1, 7 ), '-01' ), date ) AS pay_mon,
sum( piece ) AS pcs
FROM
user_trade
WHERE
YEAR ( pay_time ) = 2018
GROUP BY
goods_category,
pay_mon
),
b AS ( SELECT *, lag( pcs, 1, - 1 ) over ( PARTITION BY goods_category ORDER BY pay_mon ) AS qoq FROM a ) SELECT
*, IF(qoq < 0, 'None', concat(left((pcs - qoq ) / pcs * 100, 5), '%')) AS q_rate
FROM
b;
# 月份销售
# 数据太长, 只提取book的数据
# 环比情况(pcs)
+----------------+------------+------+------+--------+
| goods_category | pay_mon | pcs | qoq | q_rate |
+----------------+------------+------+------+--------+
| book | 2018-02-01 | 190 | -1 | None |
| book | 2018-03-01 | 344 | 190 | 44.76% |
| book | 2018-04-01 | 114 | 344 | -201.% |
| book | 2018-05-01 | 545 | 114 | 79.08% |
| book | 2018-06-01 | 466 | 545 | -16.9% |
| book | 2018-07-01 | 411 | 466 | -13.3% |
| book | 2018-08-01 | 109 | 411 | -277.% |
| book | 2018-09-01 | 406 | 109 | 73.15% |
| book | 2018-10-01 | 100 | 406 | -306.% |
| book | 2018-11-01 | 81 | 100 | -23.4% |
| book | 2018-12-01 | 255 | 81 | 68.23% |
+----------------+------------+------+------+--------+
11 rows in set (0.00 sec)
WITH a AS (
SELECT
goods_category,
# 因为后面使用了range, 这里需要将string转为date
CONVERT ( concat( substring( pay_time, 1, 7 ), '-01' ), date ) AS pay_mon,
sum( piece ) AS pcs
FROM
user_trade
WHERE
YEAR ( pay_time ) = 2018
GROUP BY
goods_category,
pay_mon
),
b AS ( SELECT *, lag( pcs, 1, - 1 ) over ( PARTITION BY goods_category ORDER BY pay_mon ) AS qoq FROM a ),
c AS ( SELECT *, IF ( qoq < 0, 'None', pcs - qoq ) AS q_rate FROM b HAVING q_rate != 'None' AND q_rate > 0 ),
d as (SELECT
goods_category,
# 剔除掉了负增长的行(这里不将负增长的那个月包含在内)
# 这里设置前后的间隔为1个月
count( goods_category ) over ( PARTITION BY goods_category ORDER BY pay_mon RANGE BETWEEN INTERVAL 1 MONTH preceding AND INTERVAL 1 MONTH following ) AS ic
FROM
c)
select goods_category, max(ic) from d GROUP BY goods_category;
# 产品连续月份销售增长
# 即book这个类别再2018年没有形成过连续的正增长
+----------------+---------+
| goods_category | max(ic) |
+----------------+---------+
| book | 1 |
| clothes | 3 |
| computer | 3 |
| electronics | 2 |
| food | 2 |
| shoes | 2 |
+----------------+---------+
6 rows in set (0.00 sec)
- 销量的连续变化情况.
- 哪些产品的销量较为异常(连续增长或者减少)
- 产品的销售的波动幅度.
5.2.2 情景2
# 找出每个月销售的产品数量排名第二的类目
WITH a AS (
SELECT
goods_category,
CONVERT ( concat( substring( pay_time, 1, 7 ), '-01' ), date ) AS pay_mon,
sum( piece ) AS pcs
FROM
user_trade
WHERE
YEAR ( pay_time ) = 2018
GROUP BY
goods_category,
pay_mon
) SELECT
*,
# NTH_VALUE(col, N), 需要获取的排名的位置
NTH_VALUE( goods_category, 2 ) over ( PARTITION BY pay_mon ORDER BY pcs DESC RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING ) AS second_good
FROM
a;
+----------------+------------+------+-------------+
| goods_category | pay_mon | pcs | second_good |
+----------------+------------+------+-------------+
| shoes | 2018-01-01 | 98 | food |
| food | 2018-01-01 | 83 | food |
| clothes | 2018-01-01 | 82 | food |
| electronics | 2018-01-01 | 26 | food |
| computer | 2018-01-01 | 15 | food |
| electronics | 2018-02-01 | 421 | computer |
| computer | 2018-02-01 | 229 | computer |
| clothes | 2018-02-01 | 224 | computer |
| food | 2018-02-01 | 220 | computer |
| book | 2018-02-01 | 190 | computer |
| shoes | 2018-02-01 | 107 | computer |
| shoes | 2018-03-01 | 364 | book |
| book | 2018-03-01 | 344 | book |
| food | 2018-03-01 | 309 | book |
| computer | 2018-03-01 | 215 | book |
| clothes | 2018-03-01 | 174 | book |
| electronics | 2018-03-01 | 115 | book |
| electronics | 2018-04-01 | 226 | food |
| food | 2018-04-01 | 182 | food |
| book | 2018-04-01 | 114 | food |
| computer | 2018-04-01 | 96 | food |
| clothes | 2018-04-01 | 95 | food |
| book | 2018-05-01 | 545 | computer |
| computer | 2018-05-01 | 366 | computer |
| shoes | 2018-05-01 | 272 | computer |
| electronics | 2018-05-01 | 169 | computer |
| food | 2018-05-01 | 161 | computer |
| clothes | 2018-05-01 | 153 | computer |
| shoes | 2018-06-01 | 506 | book |
| book | 2018-06-01 | 466 | book |
| electronics | 2018-06-01 | 338 | book |
| clothes | 2018-06-01 | 280 | book |
| computer | 2018-06-01 | 242 | book |
| food | 2018-06-01 | 242 | book |
| clothes | 2018-07-01 | 559 | shoes |
| shoes | 2018-07-01 | 435 | shoes |
| book | 2018-07-01 | 411 | shoes |
| electronics | 2018-07-01 | 385 | shoes |
| food | 2018-07-01 | 314 | shoes |
| computer | 2018-07-01 | 61 | shoes |
| clothes | 2018-08-01 | 302 | computer |
| computer | 2018-08-01 | 258 | computer |
| food | 2018-08-01 | 253 | computer |
| shoes | 2018-08-01 | 220 | computer |
| book | 2018-08-01 | 109 | computer |
| electronics | 2018-08-01 | 91 | computer |
| book | 2018-09-01 | 406 | shoes |
| shoes | 2018-09-01 | 350 | shoes |
| clothes | 2018-09-01 | 286 | shoes |
| food | 2018-09-01 | 169 | shoes |
| computer | 2018-09-01 | 158 | shoes |
| clothes | 2018-10-01 | 205 | computer |
| computer | 2018-10-01 | 170 | computer |
| shoes | 2018-10-01 | 166 | computer |
| food | 2018-10-01 | 109 | computer |
| book | 2018-10-01 | 100 | computer |
| electronics | 2018-10-01 | 41 | computer |
| clothes | 2018-11-01 | 380 | computer |
| computer | 2018-11-01 | 306 | computer |
| food | 2018-11-01 | 186 | computer |
| shoes | 2018-11-01 | 153 | computer |
| electronics | 2018-11-01 | 93 | computer |
| book | 2018-11-01 | 81 | computer |
| clothes | 2018-12-01 | 553 | food |
| food | 2018-12-01 | 437 | food |
| computer | 2018-12-01 | 378 | food |
| electronics | 2018-12-01 | 359 | food |
| book | 2018-12-01 | 255 | food |
| shoes | 2018-12-01 | 218 | food |
+----------------+------------+------+-------------+
5.2.3 情景3
- 2020-01的用户购买的商品品类数量
- 各个用户购买商品品类排名
WITH a AS ( SELECT user_name, count( DISTINCT goods_category ) AS cat_num FROM user_trade WHERE SUBSTRING( pay_time, 1, 7 ) = '2020-01' GROUP BY user_name ) SELECT
a.user_name,
a.cat_num,
# 按顺序, 实际上返回的是行号
ROW_NUMBER() over ( ORDER BY a.cat_num ) AS rank1,
# rank(). 排名相同的, 同意序号, 延续行号, 下一开始, 直接从行号开始
rank() over ( ORDER BY a.cat_num ) AS rank2,
# DENSE_RANK(). 排名相同的, 同意序号, 不延续行号, 下一开始从当前序号开始
DENSE_RANK() over ( ORDER BY a.cat_num ) AS rank3
FROM
a;
+-----------+---------+-------+-------+-------+
| user_name | cat_num | rank1 | rank2 | rank3 |
+-----------+---------+-------+-------+-------+
| Amanda | 1 | 1 | 1 | 1 |
| Cameron | 1 | 2 | 1 | 1 |
| Ward | 1 | 3 | 1 | 1 |
| Cathy | 1 | 4 | 1 | 1 |
| Cherry | 1 | 5 | 1 | 1 |
| Rupert | 1 | 6 | 1 | 1 |
| Cloris | 1 | 7 | 1 | 1 |
| Fiona | 1 | 8 | 1 | 1 |
| Peterson | 1 | 9 | 1 | 1 |
| Janet | 1 | 10 | 1 | 1 |
| Jill | 1 | 11 | 1 | 1 |
| Marshall | 1 | 12 | 1 | 1 |
| Mitchell | 1 | 13 | 1 | 1 |
| Parker | 1 | 14 | 1 | 1 |
| Payne | 1 | 15 | 1 | 1 |
| Wheeler | 2 | 16 | 16 | 2 |
| Ingrid | 2 | 17 | 16 | 2 |
| Christy | 2 | 18 | 16 | 2 |
| Catherine | 2 | 19 | 16 | 2 |
| Angelia | 2 | 20 | 16 | 2 |
+-----------+---------+-------+-------+-------+
20 rows in set (0.01 sec)
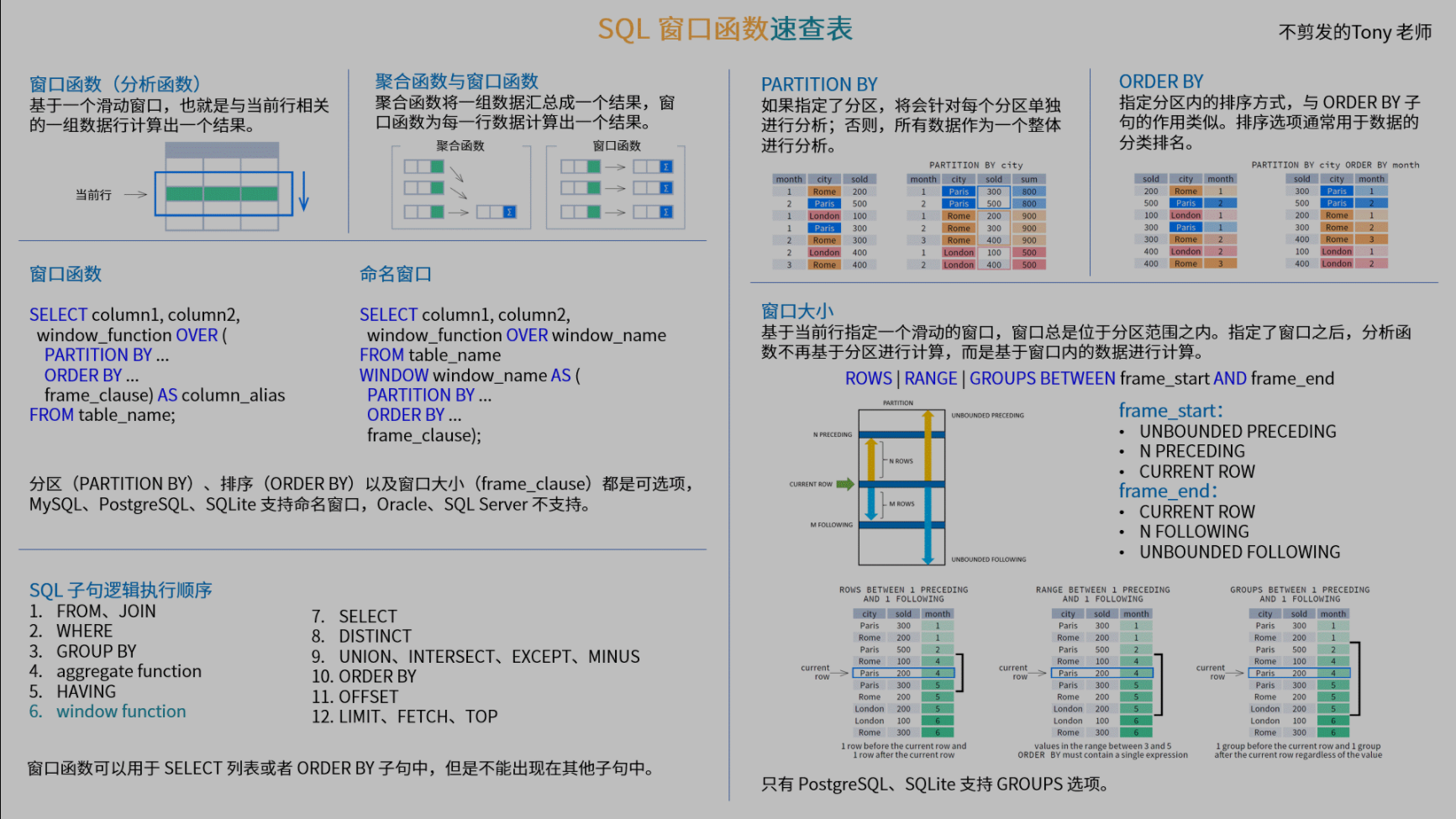
六. 速查表
from @不剪发的Tony老师

七. 总结
只有两(五)个字: 必学(必掌握)
对于从事数据分析以及相关工作的用户, 不掌握数据库(查询), 不掌握窗口函数, 这是难以想象的.
窗口函数的深度使用, 将在牛客网-SQL测试(困难)中详细展示出来.
