一. 女士品茶
女士品茶, 一本强烈推荐的关于统计学的书籍.
这本书虽然和标题关系不大, 既没有女士也没有品茶, 女士品茶只是作者引出统计学内容的起点.
这本书关于统计学重要概念的介绍远比其他各种乱七八糟的机器学习相关图书介绍来得容易接受和直观, 统计学一些基础概念在很多书籍的介绍中被扭曲或者误解, 或者是引入大量的数学模型, 让问题复杂化.
1.1 麦迪逊 vs 汉密尔顿
关于这二人的(争端)历史是美国历史(特别是建国初期)重要的组成, 对于理解美国的建国理念, 这二人的争端是极其重要组成.
推荐一本有关于这段历史的重要图书, <联邦党人文集>.
<女士品茶>中提到了二人对于文章所有权争端在统计学角度上的解决方案.

理论上, 每个(成年)人的写作方式(包括说话方式)都是相对固定, 例如词汇的使用(教育程度, 社会环境等), 句子的长度, 介词, 宾语, 语气词等的使用.
通过分析这些词汇的词频, 各种词性词汇的使用, 特定词语出现在句子或者文章中的位置, 是有很大可能推断出该内容的归属权(真实作者).

因为在不同时期, 在同一社群中, 使用词汇数量是有所差异的, 如在前莎士比亚时期的英语词汇数量和之后的对比, 显然是有很大差异的, 一些旧的词汇可能因为新的词汇出现而逐步淡出视野, 在统计时需要考虑这些影响,.

二. 词性
由于不同的语言, 在这个的划分可能是有所差异的, 这里以现代汉语为例, 简单可以分为下面类型:
| 词性 | 含义 |
|---|---|
| 名词 | 事物的专有表示词语, 火箭(rocket) |
| 动词 | 动作行为词语, 打(hit) |
| 形容词 | 描述某种事务的特性的词语, 蓝色的(blue) |
| 数词 | 一二三四, ...(one) |
| 量词 | 尺度, 测量, 吨, 米 (meter) |
| 代词 | 代替, 你我他 (he) |
| 副词 | 修饰动词, 形容词, 很(very) |
| 介词 | 介词是用在词或词组前面一起组成"介词结构"作动词形容词的附加成分, 在(on) |
| 连词 | 连词是连接词短语或句子的虚词, 和(and) |
| 助词 | 助词是表示附加关系或时态等语法意义或语气的虚词, 来(着) |
| 拟声词 | 拟声词是用来摹拟事物发出的声音的词, 哎(hey) |
| 叹词 | 叹词是表示强烈感情或呼唤, 哦(oh) |
三. TF-IDF
TF-IDF(term frequency–inverse document frequency), TF-IDF分成两个部分, 一是"词频"(Term Frequency, TF), 另二是"逆文档频率"(Inverse Document Frequency, IDF).


3.1 计算方式

词频, 相对容易理解, 即, 词在文档中出现的次数, 注意这里指的是词, 不是单一的字, 是一个词汇.
由于汉字没有类似于英文的空格分隔开, 词汇的提取是相对困难的.
python中相对出名的是jieba中文分词库.
在计算词频的时候, 显然不是直接统计, 例如一些高频的辅助词语, 是, 在, 的等, 这些干扰过于明显的, 一般称作"停用词".
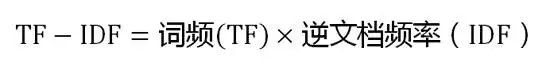
在直观的印象中, 当一篇文章出现的词汇次数越多, 通常意味着该词对于这篇文章是最重要的. 但是为什么这里还需要引用一个逆文档频率呢?
假设我们把它们都过滤掉了只考虑剩下的有实际意义的词. 这样又会遇到了另一个问题我们可能发现"中国""蜜蜂""养殖"这三个词的出现次数一样多. 这是不是意味着作为关键词它们的重要性是一样的?
显然不是这样.因为"中国"是很常见的词相对而言"蜜蜂"和"养殖"不那么常见. 如果这三个词在一篇文章的出现次数一样多有理由认为"蜜蜂"和"养殖"的重要程度要大于"中国"也就是说在关键词排序上面"蜜蜂"和"养殖"应该排在"中国"的前面.
所以我们需要一个重要性调整系数衡量一个词是不是常见词. 如果某个词比较少见但是它在这篇文章中多次出现那么它很可能就反映了这篇文章的特性正是我们所需要的关键词.
用统计学语言表达就是在词频的基础上要对每个词分配一个"重要性"权重. 最常见的词("的""是""在")给予最小的权重较常见的词("中国")给予较小的权重较少见的词("蜜蜂""养殖")给予较大的权重. 这个权重叫做"逆文档频率"(Inverse Document Frequency缩写为IDF)它的大小与一个词的常见程度成反比.
这里引用大佬-阮一峰的文章摘要, 上面的内容简明扼要地解释了这个问题.
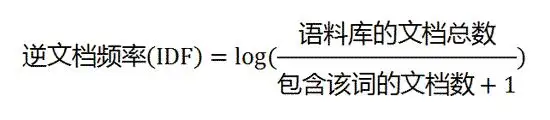
简单理解就是, 既要考虑局部的问题, 也需要考虑整体的问题, 二者是相互制衡的, 以避免单一数据对整体的影响过大, 也避免整体而忽略局部的特殊性.
在数据处理中, 常见的数据预处理: 归一化/标准化, 实际上就是让数据在相对均衡的标准下进行比较, 即避免个体之间的巨大差异导致的异常和不可比较性.
四. 小结
TF-IDF的优点是显而易见的, 简单明了. 但是需要有一个前提: 语料库的质量. 抗干扰能力较差, 在极端条件下适应性较弱.
如何维持一个相对高质量的语料库, 对于这种分析方式尤为关键.
- 词频, 需要有好的分词工具(分词需要的词库-权重-词义标注)
- 语料库, 和需要分析问题的关联
