一. 前言
突然被问, excel如何实现中国式排名?
| 值 | 排名 |
|---|---|
| 1 | 1 |
| 1 | 1 |
| 2 | 2, 还是延续上面的序号, 而不是直接跳到3, 这种方式就称为中国式排名 |
| 3 | 3 |
| 4 | 4 |
即, 在排的值中出现重复值时该如何处理接下来的序号.
在MySQL的窗口函数, 针对排名的问题提供了三种模式:
- rank()
- dense_rank()
- row_number()
MySQL root@localhost:test_db> select * from test_r;
+----+
| id |
+----+
| 1 |
| 5 |
| 2 |
| 3 |
| 3 |
| 4 |
+----+
6 rows in set
Time: 0.011s
MySQL root@localhost:test_db> select
-> rank() over w as r,
-> dense_rank() over w as dr,
-> row_number() over w as rn
-> from test_r window w as (order by id);
+---+----+----+
| r | dr | rn |
+---+----+----+
| 1 | 1 | 1 |
| 2 | 2 | 2 |
| 3 | 3 | 3 |
| 3 | 3 | 4 |
| 5 | 4 | 5 | - 注意变化
| 6 | 5 | 6 |
+---+----+----+
6 rows in set
Time: 0.008s
查了一下资料, 觉得sumproduct()函数非常有趣, 记录一下.
二. 语法
若要使用默认操作 (乘法) :
SUMPRODUCT (array1 [array2] [array3] ...)
SUMPRODUCT 函数语法具有下列参数:
| 参数 | 说明 |
|---|---|
| array1 必需 | 其相应元素需要进行相乘并求和的第一个数组参数. |
| [array2] [array3],... 可选 |
三. 实现
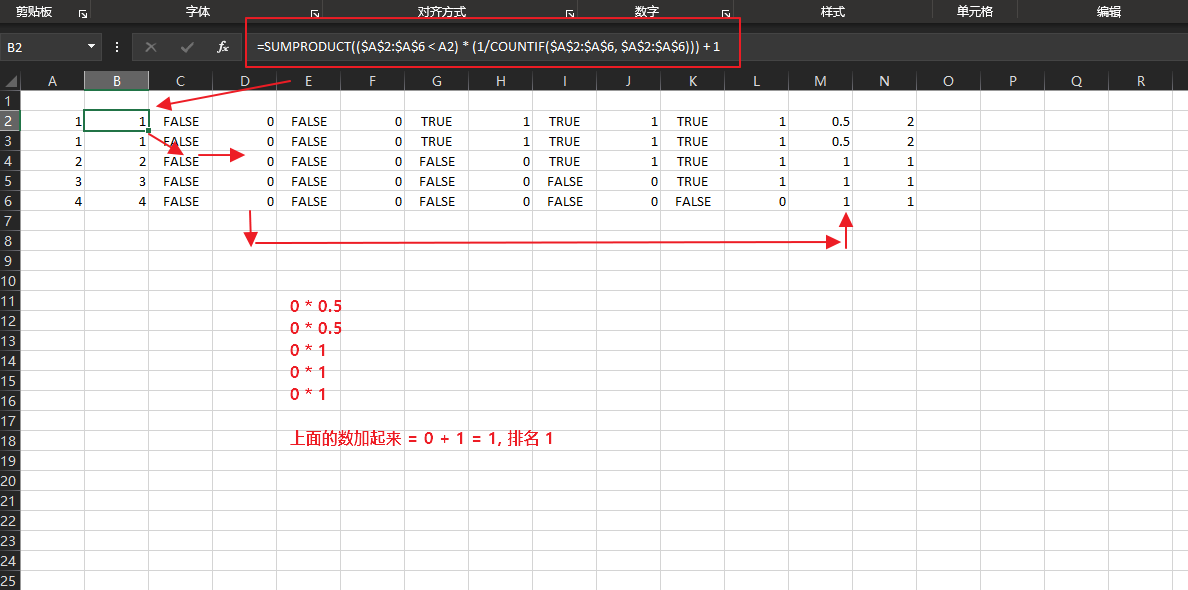
=SUMPRODUCT(($A$2:$A$6 < A2) * (1/COUNTIF($A$2:$A$6, $A$2:$A$6))) + 1
# 乍看这下还是有点难以理解的
($A$2:$A$6 < A2) => 在a2: a6中那些数小于a2, 得到一个布尔数组结果
1/COUNTIF($A$2:$A$6, $A$2:$A$6)), 这是固定值, 计算各个数出现的次数, 1/ 的操作, 是为了后面的乘积
| 1 | 1 | FALSE | 0 | FALSE | 0 | TRUE | 1 | TRUE | 1 | TRUE | 1 | 0.5 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | FALSE | 0 | FALSE | 0 | TRUE | 1 | TRUE | 1 | TRUE | 1 | 0.5 |
| 2 | 2 | FALSE | 0 | FALSE | 0 | FALSE | 0 | TRUE | 1 | TRUE | 1 | 1 |
| 3 | 3 | FALSE | 0 | FALSE | 0 | FALSE | 0 | FALSE | 0 | TRUE | 1 | 1 |
| 4 | 4 | FALSE | 0 | FALSE | 0 | FALSE | 0 | FALSE | 0 | FALSE | 0 | 1 |
countif()
返回要查找的内容在查找的内容中出现的次数
=COUNTIF(要检查哪些区域? 要查找哪些内容?)
亦或者可以使用
= SUM((UNIQUE($A$2:$A$6) < A2) * 1 ) + 1
这个函数就跟简单, unique函数得到数列的独一无二的列表, 和a2进行比较, 采用小于, 是因为, 从小向大排, 同理改成大于也是类似的, 计算得到的是数列中有多少个数比a2小, * 1 将布尔值转为0, 1数值, 求和就是排名所在, + 1是因为假如没有小于则为0.
3.1 变化
要实现上述mysql rank()的跳跃式的序号, 可以轻微变更一下公式即可:
=SUMPRODUCT(($A$2:$A$6 < A2) * (1/COUNTIF($A$2:$A$6, A2))) + 1
| 值 | 序号 |
|---|---|
| 1 | 1 |
| 1 | 1 |
| 2 | 3, 在这里发生跳跃 |
| 3 | 4 |
| 4 | 5 |
差异
(1/COUNTIF($A$2:$A$6, A2) = 单个值
(1/COUNTIF($A$2:$A$6, $A$2:$A$6)) = 数组
# 计算方式上的差异
1 * 0.5 + 1 *0.5 +0 * 1 + 0 * 1 + 0 * 1 + 1 = 2
1 * 1 + 1 * 1 + 0 * 1 + 0 * 1 + 0 * 1 + 1 = 3
# 当然直接使用excel的rank(), 新版本rank.eq()
=RANK.EQ(A2, $A$2:$A$6, 1)
四. 其他使用
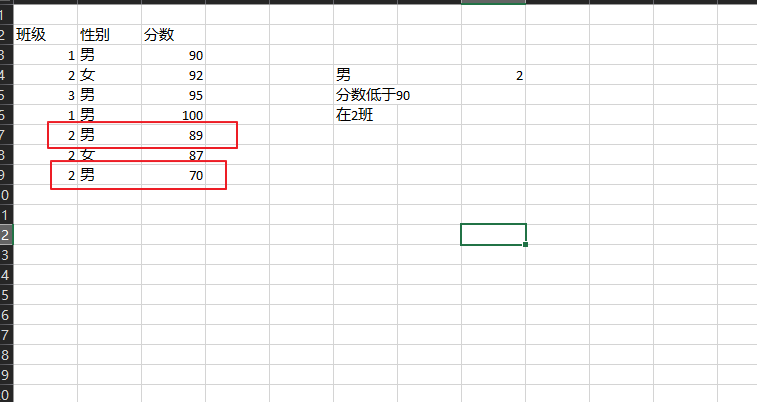
sumproduct()的其他使用, 如多条件的筛选, 找出, 满足以下三个条件的人数:
=SUMPRODUCT((A3:A9=2)*(B3:B9="男")*(C3:C9<90))
pandas类似实现
import pandas as pd
df = pd.DataFrame(
{
"a": [
1,
2,
3,
1,
2,
2,
2,
],
"b": [
"男",
"女",
"男",
"男",
"男",
"女",
"男",
],
'c': [
90,
92,
95,
100,
89,
87,
70,
]
}
)
# 传统的写法
df[(df['c'] < 90) & (df['a'] == 2) & (df['b'] == "男")]
# 类似于sql的写法
df.query('a == 2 & b=="男" & c < 90')
a b c
4 2 男 89
6 2 男 70
# 同样的, 实现上述两种排名
# 增加多一列
df.loc[7] = [1, '女', 100]
df['dense'] =df['c'].rank(ascending=False, method='dense')
df['min'] = df['c'].rank(ascending=False, method='min')
a b c dense min
0 1 男 90 4.0 5.0
1 2 女 92 3.0 4.0
2 3 男 95 2.0 3.0 , 两种排序的实现
3 1 男 100 1.0 1.0
4 2 男 89 5.0 6.0
5 2 女 87 6.0 7.0
6 2 男 70 7.0 8.0
7 1 女 100 1.0 1.0
# 支持的设置方式
method : {'average', 'min', 'max', 'first', 'dense'}, default 'average'
五. 小结
excel, 作为中小规模数据处理的瑞士军刀, 各种功能简单易用的.
作为整合数据承载, 处理, 可视化,...一条龙服务到底的强大工具, 用好excel, 不比那些花里胡哨的BI工具来得更是在, 特别是对于缺乏代码, 数据库能力的从业者(唯一可惜的是就业市场日益追逐华丽花哨的"技能").
